 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLEROjD: Lidar Extended Radar-Only Object Detection
Sep 09, 2024



Accurate 3D object detection is vital for automated driving. While lidar sensors are well suited for this task, they are expensive and have limitations in adverse weather conditions. 3+1D imaging radar sensors offer a cost-effective, robust alternative but face challenges due to their low resolution and high measurement noise. Existing 3+1D imaging radar datasets include radar and lidar data, enabling cross-modal model improvements. Although lidar should not be used during inference, it can aid the training of radar-only object detectors. We explore two strategies to transfer knowledge from the lidar to the radar domain and radar-only object detectors: 1. multi-stage training with sequential lidar point cloud thin-out, and 2. cross-modal knowledge distillation. In the multi-stage process, three thin-out methods are examined. Our results show significant performance gains of up to 4.2 percentage points in mean Average Precision with multi-stage training and up to 3.9 percentage points with knowledge distillation by initializing the student with the teacher's weights. The main benefit of these approaches is their applicability to other 3D object detection networks without altering their architecture, as we show by analyzing it on two different object detectors. Our code is available at https://github.com/rst-tu-dortmund/lerojd
Multi-Object Tracking based on Imaging Radar 3D Object Detection
Jun 03, 2024



Effective tracking of surrounding traffic participants allows for an accurate state estimation as a necessary ingredient for prediction of future behavior and therefore adequate planning of the ego vehicle trajectory. One approach for detecting and tracking surrounding traffic participants is the combination of a learning based object detector with a classical tracking algorithm. Learning based object detectors have been shown to work adequately on lidar and camera data, while learning based object detectors using standard radar data input have proven to be inferior. Recently, with the improvements to radar sensor technology in the form of imaging radars, the object detection performance on radar was greatly improved but is still limited compared to lidar sensors due to the sparsity of the radar point cloud. This presents a unique challenge for the task of multi-object tracking. The tracking algorithm must overcome the limited detection quality while generating consistent tracks. To this end, a comparison between different multi-object tracking methods on imaging radar data is required to investigate its potential for downstream tasks. The work at hand compares multiple approaches and analyzes their limitations when applied to imaging radar data. Furthermore, enhancements to the presented approaches in the form of probabilistic association algorithms are considered for this task.
Ego-Motion Estimation and Dynamic Motion Separation from 3D Point Clouds for Accumulating Data and Improving 3D Object Detection
Aug 29, 2023



New 3+1D high-resolution radar sensors are gaining importance for 3D object detection in the automotive domain due to their relative affordability and improved detection compared to classic low-resolution radar sensors. One limitation of high-resolution radar sensors, compared to lidar sensors, is the sparsity of the generated point cloud. This sparsity could be partially overcome by accumulating radar point clouds of subsequent time steps. This contribution analyzes limitations of accumulating radar point clouds on the View-of-Delft dataset. By employing different ego-motion estimation approaches, the dataset's inherent constraints, and possible solutions are analyzed. Additionally, a learning-based instance motion estimation approach is deployed to investigate the influence of dynamic motion on the accumulated point cloud for object detection. Experiments document an improved object detection performance by applying an ego-motion estimation and dynamic motion correction approach.
Reviewing 3D Object Detectors in the Context of High-Resolution 3+1D Radar
Aug 10, 2023



Recent developments and the beginning market introduction of high-resolution imaging 4D (3+1D) radar sensors have initialized deep learning-based radar perception research. We investigate deep learning-based models operating on radar point clouds for 3D object detection. 3D object detection on lidar point cloud data is a mature area of 3D vision. Many different architectures have been proposed, each with strengths and weaknesses. Due to similarities between 3D lidar point clouds and 3+1D radar point clouds, those existing 3D object detectors are a natural basis to start deep learning-based 3D object detection on radar data. Thus, the first step is to analyze the detection performance of the existing models on the new data modality and evaluate them in depth. In order to apply existing 3D point cloud object detectors developed for lidar point clouds to the radar domain, they need to be adapted first. While some detectors, such as PointPillars, have already been adapted to be applicable to radar data, we have adapted others, e.g., Voxel R-CNN, SECOND, PointRCNN, and PV-RCNN. To this end, we conduct a cross-model validation (evaluating a set of models on one particular data set) as well as a cross-data set validation (evaluating all models in the model set on several data sets). The high-resolution radar data used are the View-of-Delft and Astyx data sets. Finally, we evaluate several adaptations of the models and their training procedures. We also discuss major factors influencing the detection performance on radar data and propose possible solutions indicating potential future research avenues.
Path Assignment Techniques For Vehicle Tracking
Feb 11, 2017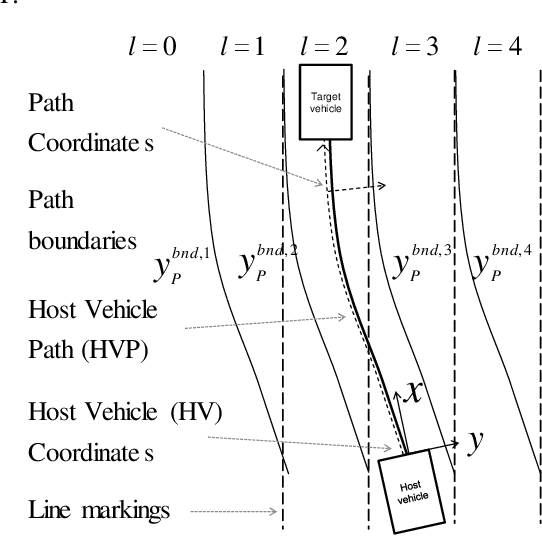
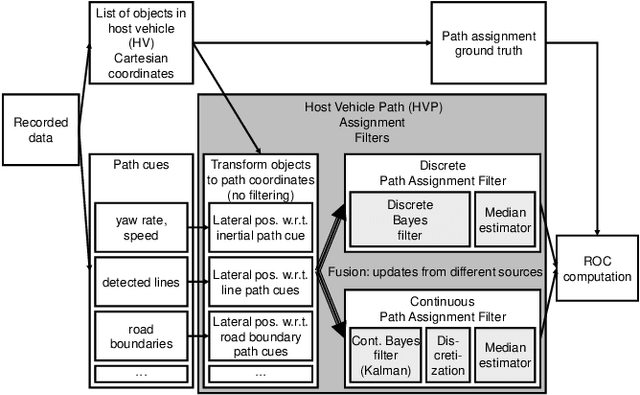
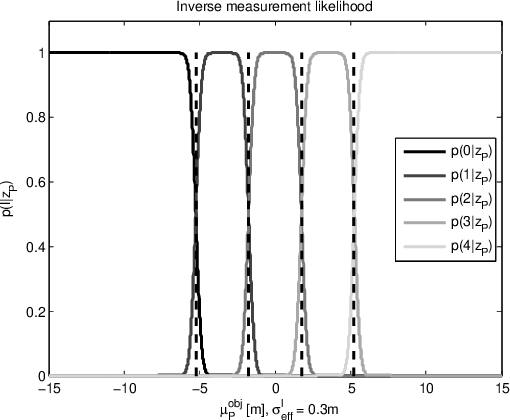
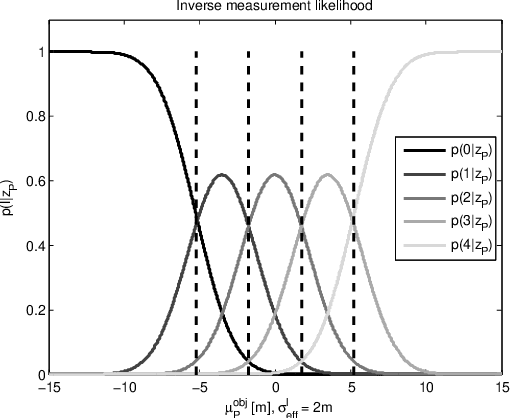
Many driver assistance systems such as Adaptive Cruise Control require the identification of the closest vehicle that is in the host vehicle's path. This entails an assignment of detected vehicles to the host vehicle path or neighboring paths. After reviewing approaches to the estimation of the host vehicle path and lane assignment techniques we introduce two methods that are motivated by the rationale to filter measured data as late in the processing stages as possible in order to avoid delays and other artifacts of intermediate filters. These filters generate discrete posterior probability distributions from which a path or "lane" index is extracted by a median estimator. The relative performance of those methods is illustrated by a ROC using experimental data and labeled ground truth data.
* 6 pages, 9 figures
A Complete Derivation Of The Association Log-Likelihood Distance For Multi-Object Tracking
Sep 08, 2015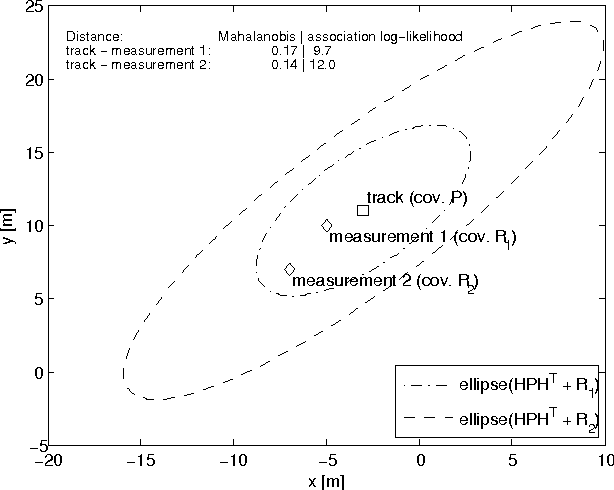
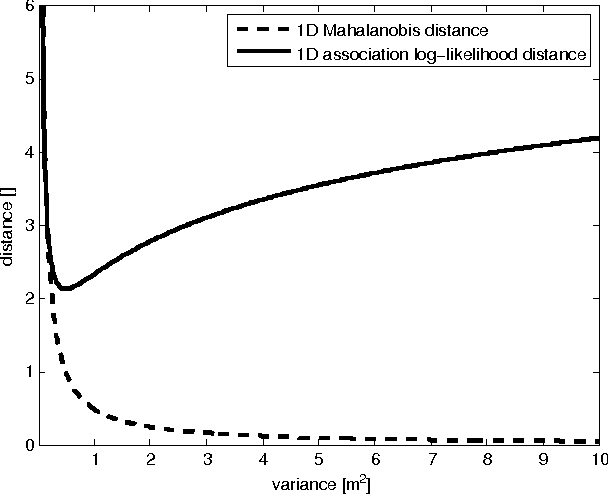
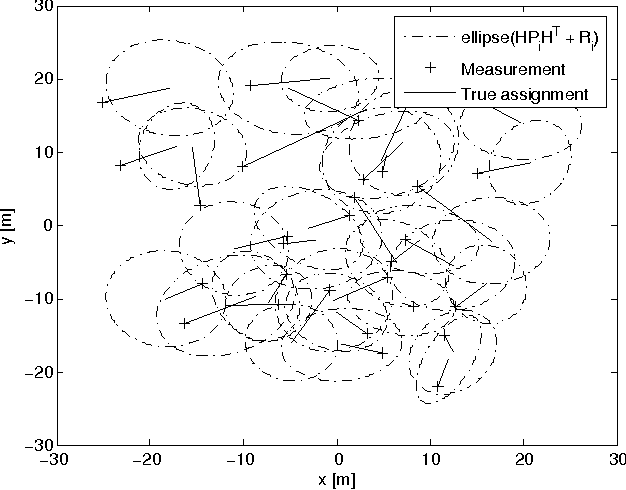
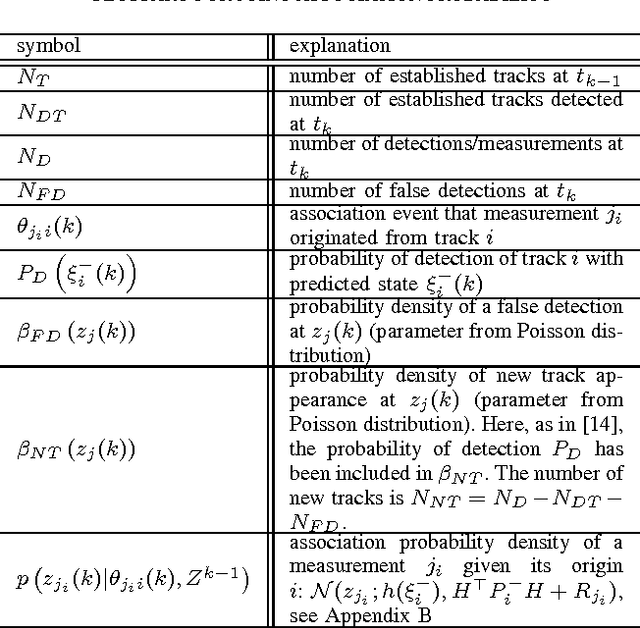
The Mahalanobis distance is commonly used in multi-object trackers for measurement-to-track association. Starting with the original definition of the Mahalanobis distance we review its use in association. Given that there is no principle in multi-object tracking that sets the Mahalanobis distance apart as a distinguished statistical distance we revisit the global association hypotheses of multiple hypothesis tracking as the most general association setting. Those association hypotheses induce a distance-like quantity for assignment which we refer to as association log-likelihood distance. We compare the ability of the Mahalanobis distance to the association log-likelihood distance to yield correct association relations in Monte-Carlo simulations. It turns out that on average the distance based on association log-likelihood performs better than the Mahalanobis distance, confirming that the maximization of global association hypotheses is a more fundamental approach to association than the minimization of a certain statistical distance measure.
Observable dynamics and coordinate systems for automotive target tracking
Sep 21, 2014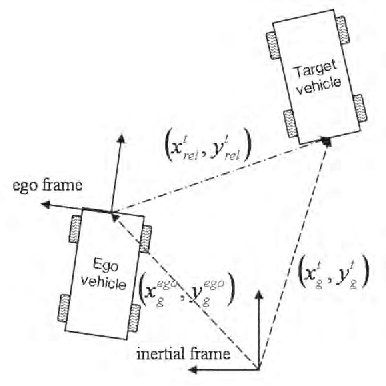

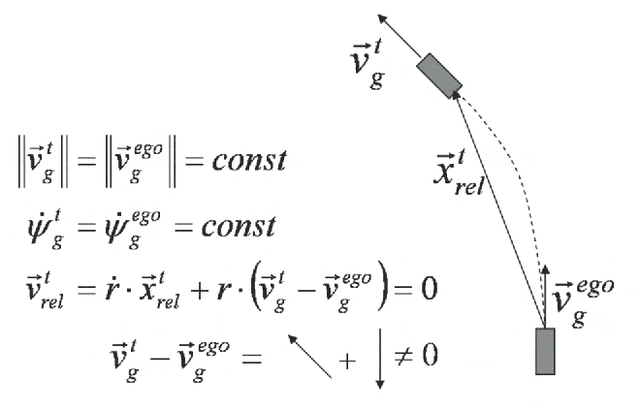

We investigate several coordinate systems and dynamical vector fields for target tracking to be used in driver assistance systems. We show how to express the discrete dynamics of maneuvering target vehicles in arbitrary coordinates starting from the target's and the own (ego) vehicle's assumed dynamical model in global coordinates. We clarify the notion of "ego compensation" and show how non-inertial effects are to be included when using a body-fixed coordinate system for target tracking. We finally compare the tracking error of different combinations of target tracking coordinates and dynamical vector fields for simulated data.
* 6 pages, 3 figures