 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnomalous Change Point Detection Using Probabilistic Predictive Coding
May 24, 2024Change point detection (CPD) and anomaly detection (AD) are essential techniques in various fields to identify abrupt changes or abnormal data instances. However, existing methods are often constrained to univariate data, face scalability challenges with large datasets due to computational demands, and experience reduced performance with high-dimensional or intricate data, as well as hidden anomalies. Furthermore, they often lack interpretability and adaptability to domain-specific knowledge, which limits their versatility across different fields. In this work, we propose a deep learning-based CPD/AD method called Probabilistic Predictive Coding (PPC) that jointly learns to encode sequential data to low dimensional latent space representations and to predict the subsequent data representations as well as the corresponding prediction uncertainties. The model parameters are optimized with maximum likelihood estimation by comparing these predictions with the true encodings. At the time of application, the true and predicted encodings are used to determine the probability of conformity, an interpretable and meaningful anomaly score. Furthermore, our approach has linear time complexity, scalability issues are prevented, and the method can easily be adjusted to a wide range of data types and intricate applications. We demonstrate the effectiveness and adaptability of our proposed method across synthetic time series experiments, image data, and real-world magnetic resonance spectroscopic imaging data.
Generating Time-Based Label Refinements to Discover More Precise Process Models
Oct 31, 2017
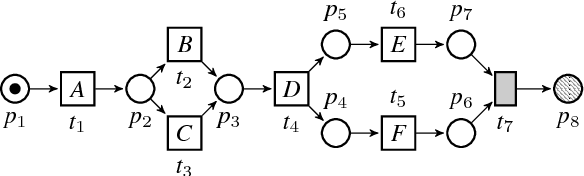
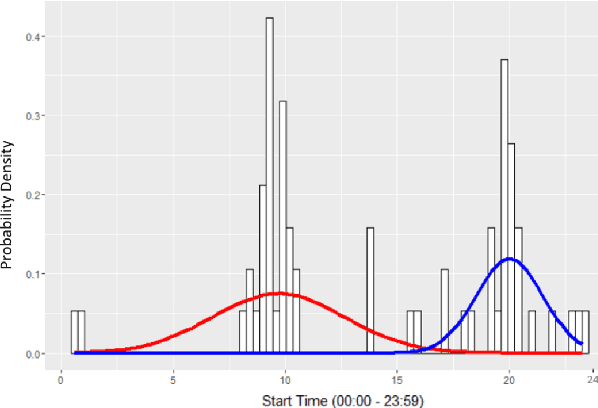

Process mining is a research field focused on the analysis of event data with the aim of extracting insights related to dynamic behavior. Applying process mining techniques on data from smart home environments has the potential to provide valuable insights in (un)healthy habits and to contribute to ambient assisted living solutions. Finding the right event labels to enable the application of process mining techniques is however far from trivial, as simply using the triggering sensor as the label for sensor events results in uninformative models that allow for too much behavior (overgeneralizing). Refinements of sensor level event labels suggested by domain experts have been shown to enable discovery of more precise and insightful process models. However, there exists no automated approach to generate refinements of event labels in the context of process mining. In this paper we propose a framework for the automated generation of label refinements based on the time attribute of events, allowing us to distinguish behaviourally different instances of the same event type based on their time attribute. We show on a case study with real life smart home event data that using automatically generated refined labels in process discovery, we can find more specific, and therefore more insightful, process models. We observe that one label refinement could have an effect on the usefulness of other label refinements when used together. Therefore, we explore four strategies to generate useful combinations of multiple label refinements and evaluate those on three real life smart home event logs.
Mining Process Model Descriptions of Daily Life through Event Abstraction
May 25, 2017



Process mining techniques focus on extracting insight in processes from event logs. Process mining has the potential to provide valuable insights in (un)healthy habits and to contribute to ambient assisted living solutions when applied on data from smart home environments. However, events recorded in smart home environments are on the level of sensor triggers, at which process discovery algorithms produce overgeneralizing process models that allow for too much behavior and that are difficult to interpret for human experts. We show that abstracting the events to a higher-level interpretation can enable discovery of more precise and more comprehensible models. We present a framework for the extraction of features that can be used for abstraction with supervised learning methods that is based on the XES IEEE standard for event logs. This framework can automatically abstract sensor-level events to their interpretation at the human activity level, after training it on training data for which both the sensor and human activity events are known. We demonstrate our abstraction framework on three real-life smart home event logs and show that the process models that can be discovered after abstraction are more precise indeed.
* arXiv admin note: substantial text overlap with arXiv:1606.07283
Mining Local Process Models
May 16, 2017

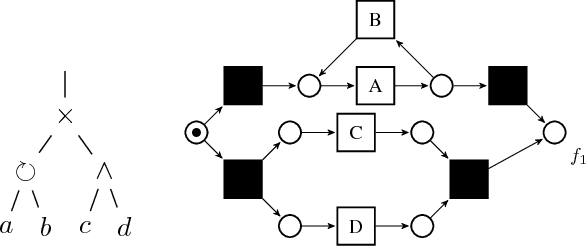

In this paper we describe a method to discover frequent behavioral patterns in event logs. We express these patterns as \emph{local process models}. Local process model mining can be positioned in-between process discovery and episode / sequential pattern mining. The technique presented in this paper is able to learn behavioral patterns involving sequential composition, concurrency, choice and loop, like in process mining. However, we do not look at start-to-end models, which distinguishes our approach from process discovery and creates a link to episode / sequential pattern mining. We propose an incremental procedure for building local process models capturing frequent patterns based on so-called process trees. We propose five quality dimensions and corresponding metrics for local process models, given an event log. We show monotonicity properties for some quality dimensions, enabling a speedup of local process model discovery through pruning. We demonstrate through a real life case study that mining local patterns allows us to get insights in processes where regular start-to-end process discovery techniques are only able to learn unstructured, flower-like, models.
* Published in Elsevier's Journal of Innovation in Digital Ecosystems, Special Issue on Data Mining
Heuristic Approaches for Generating Local Process Models through Log Projections
Oct 10, 2016



Local Process Model (LPM) discovery is focused on the mining of a set of process models where each model describes the behavior represented in the event log only partially, i.e. subsets of possible events are taken into account to create so-called local process models. Often such smaller models provide valuable insights into the behavior of the process, especially when no adequate and comprehensible single overall process model exists that is able to describe the traces of the process from start to end. The practical application of LPM discovery is however hindered by computational issues in the case of logs with many activities (problems may already occur when there are more than 17 unique activities). In this paper, we explore three heuristics to discover subsets of activities that lead to useful log projections with the goal of speeding up LPM discovery considerably while still finding high-quality LPMs. We found that a Markov clustering approach to create projection sets results in the largest improvement of execution time, with discovered LPMs still being better than with the use of randomly generated activity sets of the same size. Another heuristic, based on log entropy, yields a more moderate speedup, but enables the discovery of higher quality LPMs. The third heuristic, based on the relative information gain, shows unstable performance: for some data sets the speedup and LPM quality are higher than with the log entropy based method, while for other data sets there is no speedup at all.
* paper accepted and to appear in the proceedings of the IEEE Symposium on Computational Intelligence and Data Mining (CIDM), special session on Process Mining, part of the Symposium Series on Computational Intelligence (SSCI)
On Generation of Time-based Label Refinements
Sep 12, 2016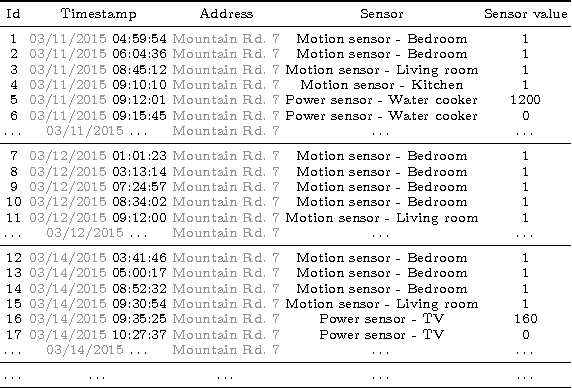
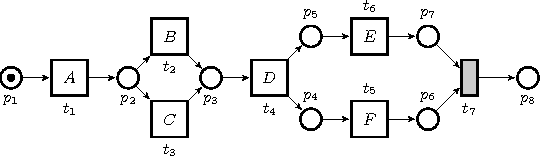
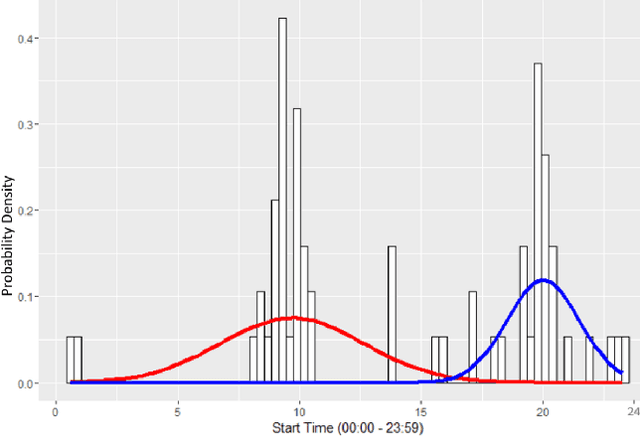
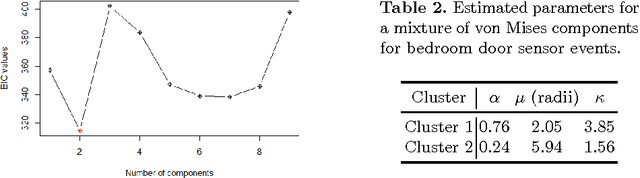
Process mining is a research field focused on the analysis of event data with the aim of extracting insights in processes. Applying process mining techniques on data from smart home environments has the potential to provide valuable insights in (un)healthy habits and to contribute to ambient assisted living solutions. Finding the right event labels to enable application of process mining techniques is however far from trivial, as simply using the triggering sensor as the label for sensor events results in uninformative models that allow for too much behavior (overgeneralizing). Refinements of sensor level event labels suggested by domain experts have shown to enable discovery of more precise and insightful process models. However, there exist no automated approach to generate refinements of event labels in the context of process mining. In this paper we propose a framework for automated generation of label refinements based on the time attribute of events. We show on a case study with real life smart home event data that behaviorally more specific, and therefore more insightful, process models can be found by using automatically generated refined labels in process discovery.
Event Abstraction for Process Mining using Supervised Learning Techniques
Jun 23, 2016



Process mining techniques focus on extracting insight in processes from event logs. In many cases, events recorded in the event log are too fine-grained, causing process discovery algorithms to discover incomprehensible process models or process models that are not representative of the event log. We show that when process discovery algorithms are only able to discover an unrepresentative process model from a low-level event log, structure in the process can in some cases still be discovered by first abstracting the event log to a higher level of granularity. This gives rise to the challenge to bridge the gap between an original low-level event log and a desired high-level perspective on this log, such that a more structured or more comprehensible process model can be discovered. We show that supervised learning can be leveraged for the event abstraction task when annotations with high-level interpretations of the low-level events are available for a subset of the sequences (i.e., traces). We present a method to generate feature vector representations of events based on XES extensions, and describe an approach to abstract events in an event log with Condition Random Fields using these event features. Furthermore, we propose a sequence-focused metric to evaluate supervised event abstraction results that fits closely to the tasks of process discovery and conformance checking. We conclude this paper by demonstrating the usefulness of supervised event abstraction for obtaining more structured and/or more comprehensible process models using both real life event data and synthetic event data.
* paper to appear in the proceedings of the SAI Intelligent Systems Conference 2016
Log-based Evaluation of Label Splits for Process Models
Jun 23, 2016



Process mining techniques aim to extract insights in processes from event logs. One of the challenges in process mining is identifying interesting and meaningful event labels that contribute to a better understanding of the process. Our application area is mining data from smart homes for elderly, where the ultimate goal is to signal deviations from usual behavior and provide timely recommendations in order to extend the period of independent living. Extracting individual process models showing user behavior is an important instrument in achieving this goal. However, the interpretation of sensor data at an appropriate abstraction level is not straightforward. For example, a motion sensor in a bedroom can be triggered by tossing and turning in bed or by getting up. We try to derive the actual activity depending on the context (time, previous events, etc.). In this paper we introduce the notion of label refinements, which links more abstract event descriptions with their more refined counterparts. We present a statistical evaluation method to determine the usefulness of a label refinement for a given event log from a process perspective. Based on data from smart homes, we show how our statistical evaluation method for label refinements can be used in practice. Our method was able to select two label refinements out of a set of candidate label refinements that both had a positive effect on model precision.
* Paper accepted at the 20th International Conference on Knowledge-Based and Intelligent Information & Engineering Systems, to appear in Procedia Computer Science