 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImage inpainting enhancement by replacing the original mask with a self-attended region from the input image
Nov 08, 2024Image inpainting, the process of restoring missing or corrupted regions of an image by reconstructing pixel information, has recently seen considerable advancements through deep learning-based approaches. In this paper, we introduce a novel deep learning-based pre-processing methodology for image inpainting utilizing the Vision Transformer (ViT). Our approach involves replacing masked pixel values with those generated by the ViT, leveraging diverse visual patches within the attention matrix to capture discriminative spatial features. To the best of our knowledge, this is the first instance of such a pre-processing model being proposed for image inpainting tasks. Furthermore, we show that our methodology can be effectively applied using the pre-trained ViT model with pre-defined patch size. To evaluate the generalization capability of the proposed methodology, we provide experimental results comparing our approach with four standard models across four public datasets, demonstrating the efficacy of our pre-processing technique in enhancing inpainting performance.
Recent Advances in Multi-Choice Machine Reading Comprehension: A Survey on Methods and Datasets
Aug 04, 2024This paper provides a thorough examination of recent developments in the field of multi-choice Machine Reading Comprehension (MRC). Focused on benchmark datasets, methodologies, challenges, and future trajectories, our goal is to offer researchers a comprehensive overview of the current landscape in multi-choice MRC. The analysis delves into 30 existing cloze-style and multiple-choice MRC benchmark datasets, employing a refined classification method based on attributes such as corpus style, domain, complexity, context style, question style, and answer style. This classification system enhances our understanding of each dataset's diverse attributes and categorizes them based on their complexity. Furthermore, the paper categorizes recent methodologies into Fine-tuned and Prompt-tuned methods. Fine-tuned methods involve adapting pre-trained language models (PLMs) to a specific task through retraining on domain-specific datasets, while prompt-tuned methods use prompts to guide PLM response generation, presenting potential applications in zero-shot or few-shot learning scenarios. By contributing to ongoing discussions, inspiring future research directions, and fostering innovations, this paper aims to propel multi-choice MRC towards new frontiers of achievement.
A Transformer Model for Boundary Detection in Continuous Sign Language
Feb 22, 2024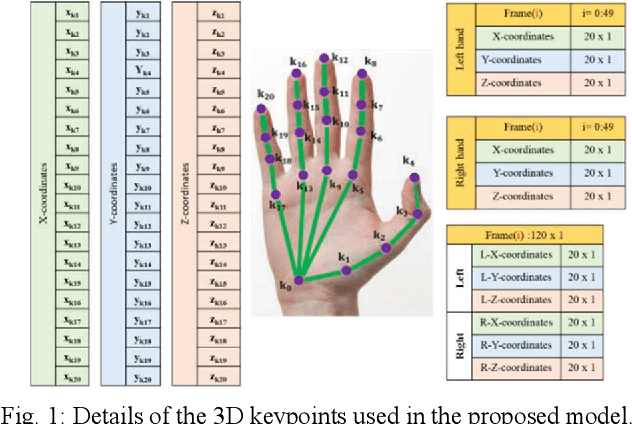
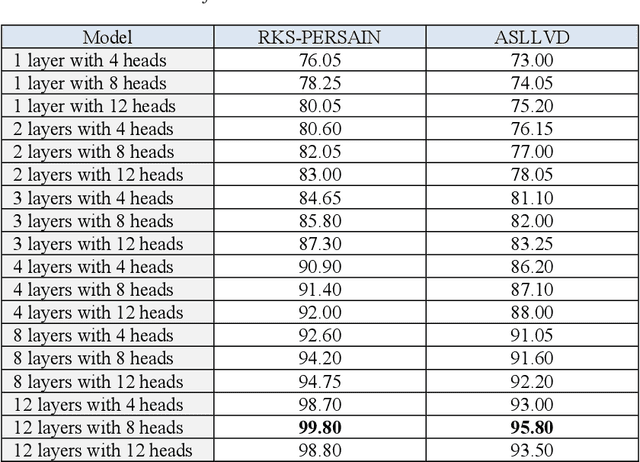
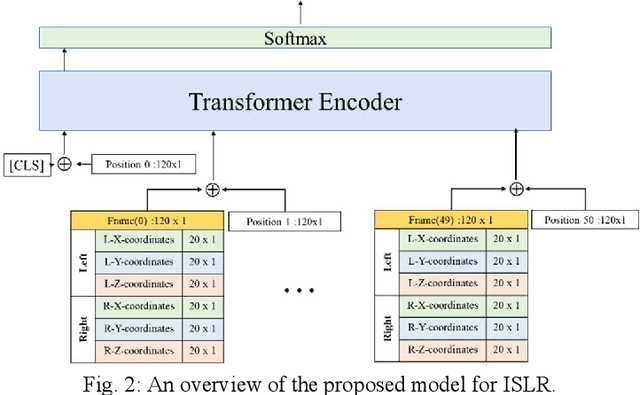
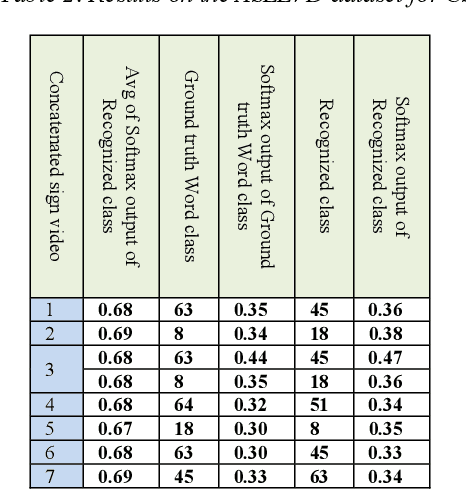
Sign Language Recognition (SLR) has garnered significant attention from researchers in recent years, particularly the intricate domain of Continuous Sign Language Recognition (CSLR), which presents heightened complexity compared to Isolated Sign Language Recognition (ISLR). One of the prominent challenges in CSLR pertains to accurately detecting the boundaries of isolated signs within a continuous video stream. Additionally, the reliance on handcrafted features in existing models poses a challenge to achieving optimal accuracy. To surmount these challenges, we propose a novel approach utilizing a Transformer-based model. Unlike traditional models, our approach focuses on enhancing accuracy while eliminating the need for handcrafted features. The Transformer model is employed for both ISLR and CSLR. The training process involves using isolated sign videos, where hand keypoint features extracted from the input video are enriched using the Transformer model. Subsequently, these enriched features are forwarded to the final classification layer. The trained model, coupled with a post-processing method, is then applied to detect isolated sign boundaries within continuous sign videos. The evaluation of our model is conducted on two distinct datasets, including both continuous signs and their corresponding isolated signs, demonstrates promising results.
A Conditional Generative Chatbot using Transformer Model
Jun 03, 2023A Chatbot serves as a communication tool between a human user and a machine to achieve an appropriate answer based on the human input. In more recent approaches, a combination of Natural Language Processing and sequential models are used to build a generative Chatbot. The main challenge of these models is their sequential nature, which leads to less accurate results. To tackle this challenge, in this paper, a novel end-to-end architecture is proposed using conditional Wasserstein Generative Adversarial Networks and a transformer model for answer generation in Chatbots. While the generator of the proposed model consists of a full transformer model to generate an answer, the discriminator includes only the encoder part of a transformer model followed by a classifier. To the best of our knowledge, this is the first time that a generative Chatbot is proposed using the embedded transformer in both generator and discriminator models. Relying on the parallel computing of the transformer model, the results of the proposed model on the Cornell Movie-Dialog corpus and the Chit-Chat datasets confirm the superiority of the proposed model compared to state-of-the-art alternatives using different evaluation metrics.
A Non-Anatomical Graph Structure for isolated hand gesture separation in continuous gesture sequences
Jul 15, 2022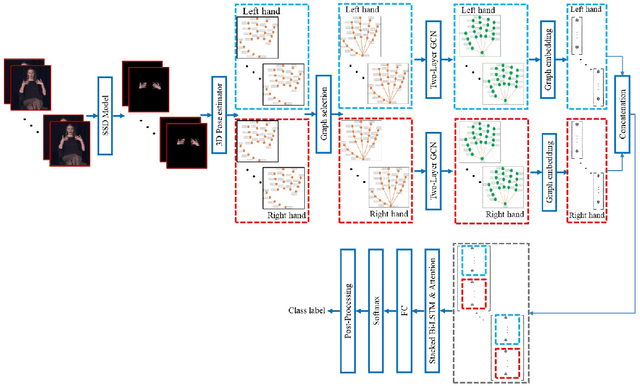
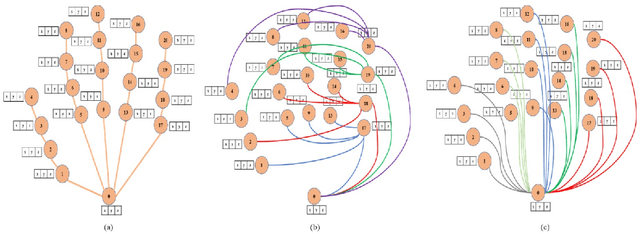
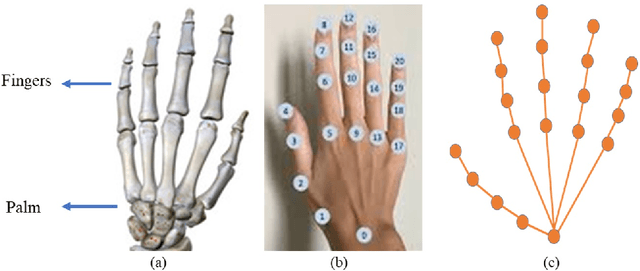
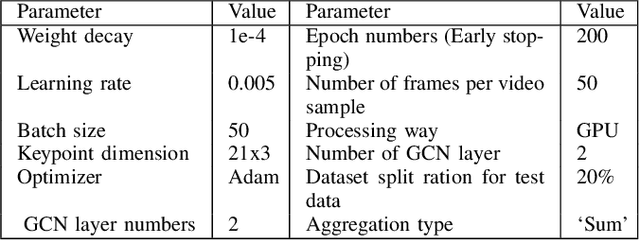
Continuous Hand Gesture Recognition (CHGR) has been extensively studied by researchers in the last few decades. Recently, one model has been presented to deal with the challenge of the boundary detection of isolated gestures in a continuous gesture video [17]. To enhance the model performance and also replace the handcrafted feature extractor in the presented model in [17], we propose a GCN model and combine it with the stacked Bi-LSTM and Attention modules to push the temporal information in the video stream. Considering the breakthroughs of GCN models for skeleton modality, we propose a two-layer GCN model to empower the 3D hand skeleton features. Finally, the class probabilities of each isolated gesture are fed to the post-processing module, borrowed from [17]. Furthermore, we replace the anatomical graph structure with some non-anatomical graph structures. Due to the lack of a large dataset, including both the continuous gesture sequences and the corresponding isolated gestures, three public datasets in Dynamic Hand Gesture Recognition (DHGR), RKS-PERSIANSIGN, and ASLVID, are used for evaluation. Experimental results show the superiority of the proposed model in dealing with isolated gesture boundaries detection in continuous gesture sequences
TriHorn-Net: A Model for Accurate Depth-Based 3D Hand Pose Estimation
Jun 14, 2022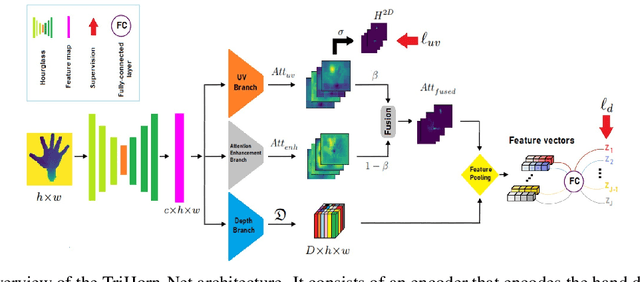

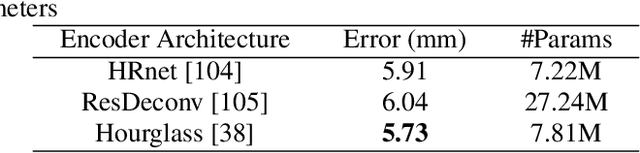
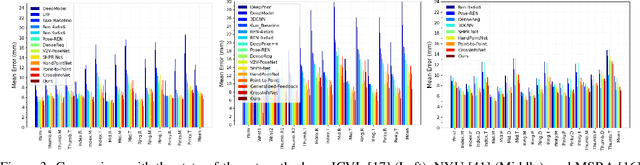
3D hand pose estimation methods have made significant progress recently. However, estimation accuracy is often far from sufficient for specific real-world applications, and thus there is significant room for improvement. This paper proposes TriHorn-Net, a novel model that uses specific innovations to improve hand pose estimation accuracy on depth images. The first innovation is the decomposition of the 3D hand pose estimation into the estimation of 2D joint locations in the depth image space (UV), and the estimation of their corresponding depths aided by two complementary attention maps. This decomposition prevents depth estimation, which is a more difficult task, from interfering with the UV estimations at both the prediction and feature levels. The second innovation is PixDropout, which is, to the best of our knowledge, the first appearance-based data augmentation method for hand depth images. Experimental results demonstrate that the proposed model outperforms the state-of-the-art methods on three public benchmark datasets.
Word separation in continuous sign language using isolated signs and post-processing
Apr 13, 2022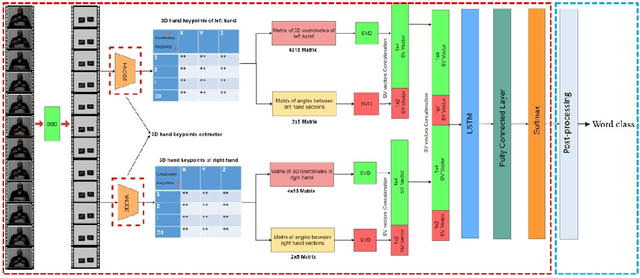

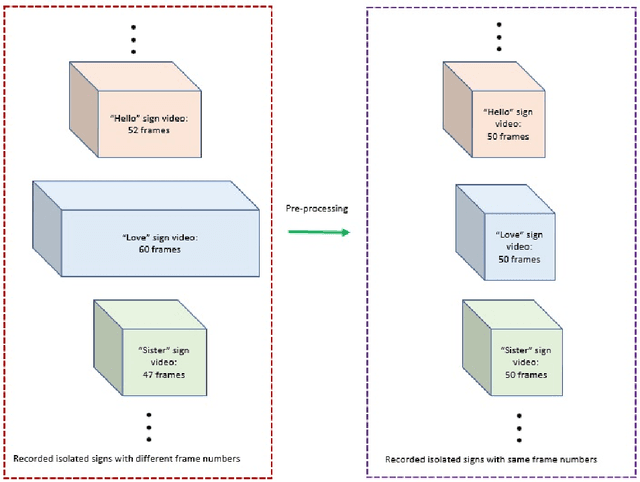

Continuous Sign Language Recognition (CSLR) is a long challenging task in Computer Vision due to the difficulties in detecting the explicit boundaries between the words in a sign sentence. To deal with this challenge, we propose a two-stage model. In the first stage, the predictor model, which includes a combination of CNN, SVD, and LSTM, is trained with the isolated signs. In the second stage, we apply a post-processing algorithm to the Softmax outputs obtained from the first part of the model in order to separate the isolated signs in the continuous signs. Due to the lack of a large dataset, including both the sign sequences and the corresponding isolated signs, two public datasets in Isolated Sign Language Recognition (ISLR), RKS-PERSIANSIGN and ASLVID, are used for evaluation. Results of the continuous sign videos confirm the efficiency of the proposed model to deal with isolated sign boundaries detection.
Deep-Disaster: Unsupervised Disaster Detection and Localization Using Visual Data
Jan 31, 2022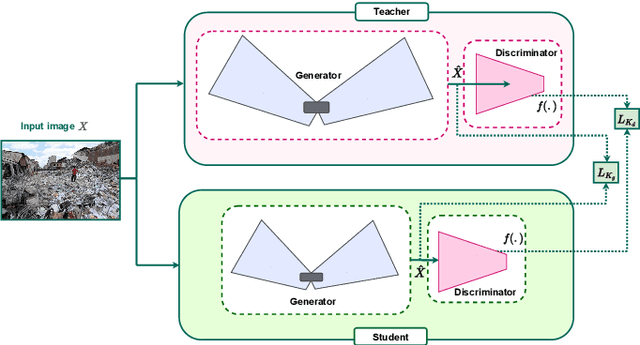
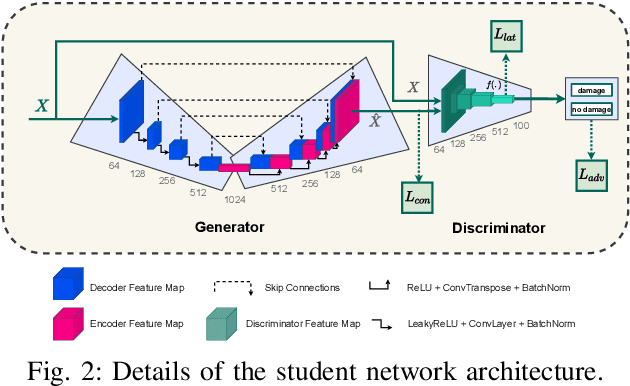
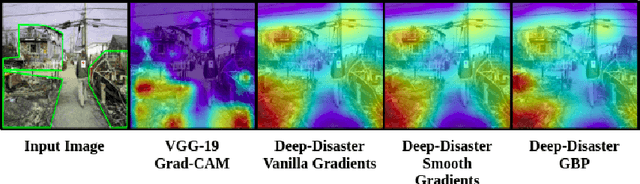
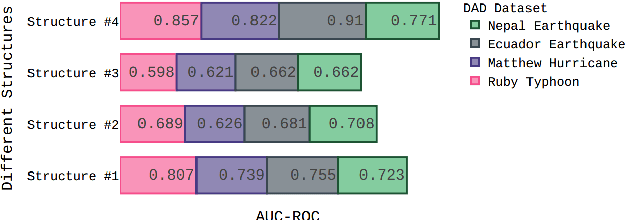
Social media plays a significant role in sharing essential information, which helps humanitarian organizations in rescue operations during and after disaster incidents. However, developing an efficient method that can provide rapid analysis of social media images in the early hours of disasters is still largely an open problem, mainly due to the lack of suitable datasets and the sheer complexity of this task. In addition, supervised methods can not generalize well to novel disaster incidents. In this paper, inspired by the success of Knowledge Distillation (KD) methods, we propose an unsupervised deep neural network to detect and localize damages in social media images. Our proposed KD architecture is a feature-based distillation approach that comprises a pre-trained teacher and a smaller student network, with both networks having similar GAN architecture containing a generator and a discriminator. The student network is trained to emulate the behavior of the teacher on training input samples, which, in turn, contain images that do not include any damaged regions. Therefore, the student network only learns the distribution of no damage data and would have different behavior from the teacher network-facing damages. To detect damage, we utilize the difference between features generated by two networks using a defined score function that demonstrates the probability of damages occurring. Our experimental results on the benchmark dataset confirm that our approach outperforms state-of-the-art methods in detecting and localizing the damaged areas, especially for novel disaster types.
All You Need In Sign Language Production
Jan 06, 2022
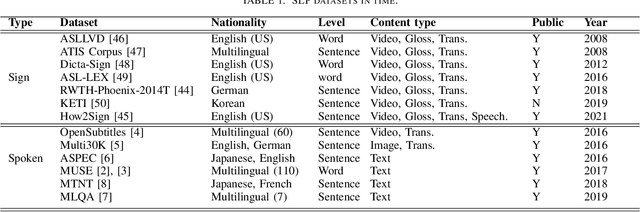
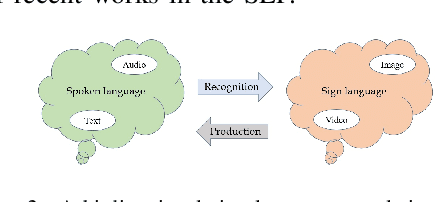

Sign Language is the dominant form of communication language used in the deaf and hearing-impaired community. To make an easy and mutual communication between the hearing-impaired and the hearing communities, building a robust system capable of translating the spoken language into sign language and vice versa is fundamental. To this end, sign language recognition and production are two necessary parts for making such a two-way system. Sign language recognition and production need to cope with some critical challenges. In this survey, we review recent advances in Sign Language Production (SLP) and related areas using deep learning. To have more realistic perspectives to sign language, we present an introduction to the Deaf culture, Deaf centers, psychological perspective of sign language, the main differences between spoken language and sign language. Furthermore, we present the fundamental components of a bi-directional sign language translation system, discussing the main challenges in this area. Also, the backbone architectures and methods in SLP are briefly introduced and the proposed taxonomy on SLP is presented. Finally, a general framework for SLP and performance evaluation, and also a discussion on the recent developments, advantages, and limitations in SLP, commenting on possible lines for future research are presented.
Multi-Modal Zero-Shot Sign Language Recognition
Sep 02, 2021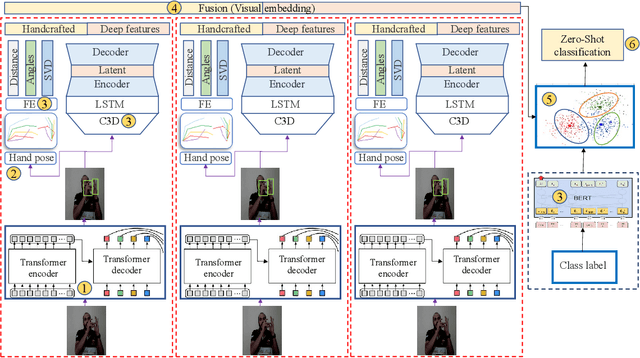
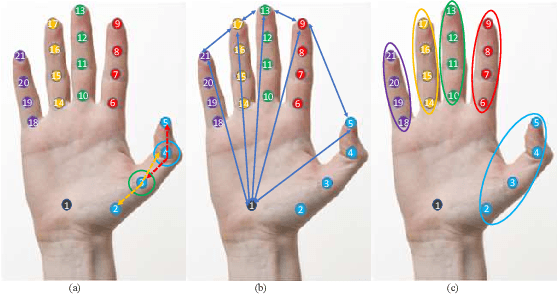


Zero-Shot Learning (ZSL) has rapidly advanced in recent years. Towards overcoming the annotation bottleneck in the Sign Language Recognition (SLR), we explore the idea of Zero-Shot Sign Language Recognition (ZS-SLR) with no annotated visual examples, by leveraging their textual descriptions. In this way, we propose a multi-modal Zero-Shot Sign Language Recognition (ZS-SLR) model harnessing from the complementary capabilities of deep features fused with the skeleton-based ones. A Transformer-based model along with a C3D model is used for hand detection and deep features extraction, respectively. To make a trade-off between the dimensionality of the skeletonbased and deep features, we use an Auto-Encoder (AE) on top of the Long Short Term Memory (LSTM) network. Finally, a semantic space is used to map the visual features to the lingual embedding of the class labels, achieved via the Bidirectional Encoder Representations from Transformers (BERT) model. Results on four large-scale datasets, RKS-PERSIANSIGN, First-Person, ASLVID, and isoGD, show the superiority of the proposed model compared to state-of-the-art alternatives in ZS-SLR.