 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetecting Anomalies Using Rotated Isolation Forest
Jan 29, 2025



The Isolation Forest (iForest), proposed by Liu, Ting, and Zhou at TKDE 2012, has become a prominent tool for unsupervised anomaly detection. However, recent research by Hariri, Kind, and Brunner, published in TKDE 2021, has revealed issues with iForest. They identified the presence of axis-aligned ghost clusters that can be misidentified as normal clusters, leading to biased anomaly scores and inaccurate predictions. In response, they developed the Extended Isolation Forest (EIF), which effectively solves these issues by eliminating the ghost clusters introduced by iForest. This enhancement results in improved consistency of anomaly scores and superior performance. We reveal a previously overlooked problem in the Extended Isolation Forest (EIF), showing that it is vulnerable to ghost inter-clusters between normal clusters of data points. In this paper, we introduce the Rotated Isolation Forest (RIF) algorithm which effectively addresses both the axis-aligned ghost clusters observed in iForest and the ghost inter-clusters seen in EIF. RIF accomplishes this by randomly rotating the dataset (using random rotation matrices and QR decomposition) before feeding it into the iForest construction, thereby increasing dataset variation and eliminating ghost clusters. Our experiments conclusively demonstrate that the RIF algorithm outperforms iForest and EIF, as evidenced by the results obtained from both synthetic datasets and real-world datasets.
Image inpainting enhancement by replacing the original mask with a self-attended region from the input image
Nov 08, 2024Image inpainting, the process of restoring missing or corrupted regions of an image by reconstructing pixel information, has recently seen considerable advancements through deep learning-based approaches. In this paper, we introduce a novel deep learning-based pre-processing methodology for image inpainting utilizing the Vision Transformer (ViT). Our approach involves replacing masked pixel values with those generated by the ViT, leveraging diverse visual patches within the attention matrix to capture discriminative spatial features. To the best of our knowledge, this is the first instance of such a pre-processing model being proposed for image inpainting tasks. Furthermore, we show that our methodology can be effectively applied using the pre-trained ViT model with pre-defined patch size. To evaluate the generalization capability of the proposed methodology, we provide experimental results comparing our approach with four standard models across four public datasets, demonstrating the efficacy of our pre-processing technique in enhancing inpainting performance.
Recent Advances in Multi-Choice Machine Reading Comprehension: A Survey on Methods and Datasets
Aug 04, 2024This paper provides a thorough examination of recent developments in the field of multi-choice Machine Reading Comprehension (MRC). Focused on benchmark datasets, methodologies, challenges, and future trajectories, our goal is to offer researchers a comprehensive overview of the current landscape in multi-choice MRC. The analysis delves into 30 existing cloze-style and multiple-choice MRC benchmark datasets, employing a refined classification method based on attributes such as corpus style, domain, complexity, context style, question style, and answer style. This classification system enhances our understanding of each dataset's diverse attributes and categorizes them based on their complexity. Furthermore, the paper categorizes recent methodologies into Fine-tuned and Prompt-tuned methods. Fine-tuned methods involve adapting pre-trained language models (PLMs) to a specific task through retraining on domain-specific datasets, while prompt-tuned methods use prompts to guide PLM response generation, presenting potential applications in zero-shot or few-shot learning scenarios. By contributing to ongoing discussions, inspiring future research directions, and fostering innovations, this paper aims to propel multi-choice MRC towards new frontiers of achievement.
A Transformer Model for Boundary Detection in Continuous Sign Language
Feb 22, 2024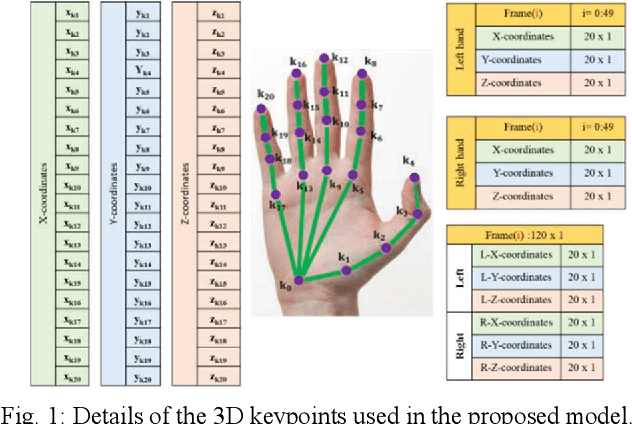
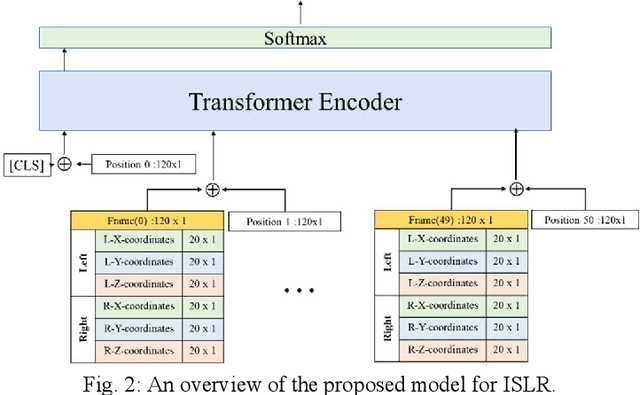
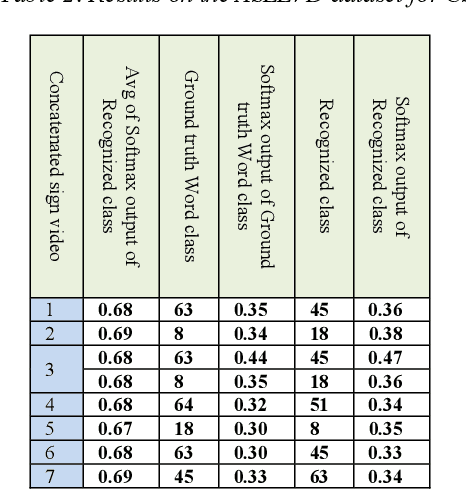
Sign Language Recognition (SLR) has garnered significant attention from researchers in recent years, particularly the intricate domain of Continuous Sign Language Recognition (CSLR), which presents heightened complexity compared to Isolated Sign Language Recognition (ISLR). One of the prominent challenges in CSLR pertains to accurately detecting the boundaries of isolated signs within a continuous video stream. Additionally, the reliance on handcrafted features in existing models poses a challenge to achieving optimal accuracy. To surmount these challenges, we propose a novel approach utilizing a Transformer-based model. Unlike traditional models, our approach focuses on enhancing accuracy while eliminating the need for handcrafted features. The Transformer model is employed for both ISLR and CSLR. The training process involves using isolated sign videos, where hand keypoint features extracted from the input video are enriched using the Transformer model. Subsequently, these enriched features are forwarded to the final classification layer. The trained model, coupled with a post-processing method, is then applied to detect isolated sign boundaries within continuous sign videos. The evaluation of our model is conducted on two distinct datasets, including both continuous signs and their corresponding isolated signs, demonstrates promising results.
Integrating a Heterogeneous Graph with Entity-aware Self-attention using Relative Position Labels for Reading Comprehension Model
Jul 22, 2023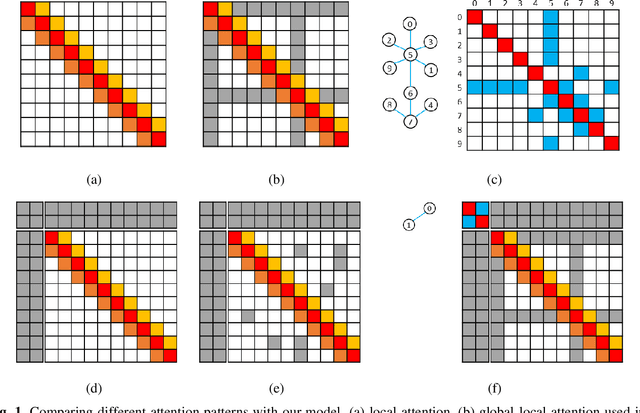
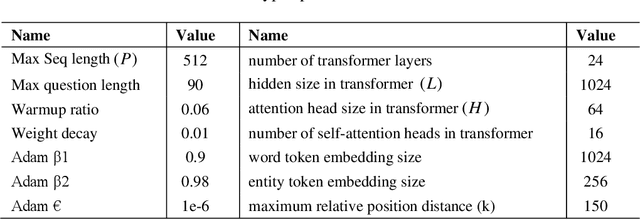
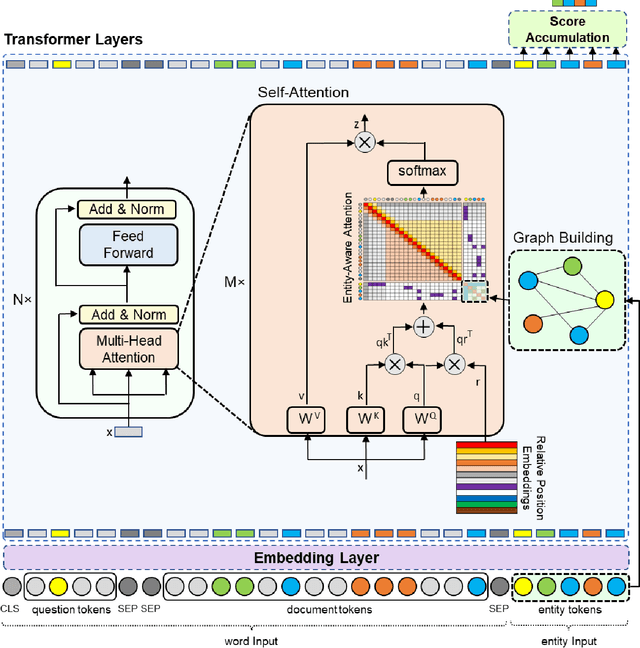
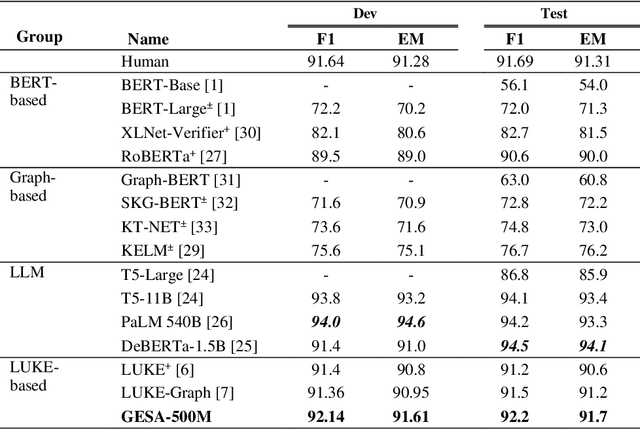
Despite the significant progress made by transformer models in machine reading comprehension tasks, they still fall short in handling complex reasoning tasks due to the absence of explicit knowledge in the input sequence. To address this limitation, many recent works have proposed injecting external knowledge into the model. However, selecting relevant external knowledge, ensuring its availability, and requiring additional processing steps remain challenging. In this paper, we introduce a novel attention pattern that integrates reasoning knowledge derived from a heterogeneous graph into the transformer architecture without relying on external knowledge. The proposed attention pattern comprises three key elements: global-local attention for word tokens, graph attention for entity tokens that exhibit strong attention towards tokens connected in the graph as opposed to those unconnected, and the consideration of the type of relationship between each entity token and word token. This results in optimized attention between the two if a relationship exists. The pattern is coupled with special relative position labels, allowing it to integrate with LUKE's entity-aware self-attention mechanism. The experimental findings corroborate that our model outperforms both the cutting-edge LUKE-Graph and the baseline LUKE model on the ReCoRD dataset that focuses on commonsense reasoning.
A Conditional Generative Chatbot using Transformer Model
Jun 03, 2023A Chatbot serves as a communication tool between a human user and a machine to achieve an appropriate answer based on the human input. In more recent approaches, a combination of Natural Language Processing and sequential models are used to build a generative Chatbot. The main challenge of these models is their sequential nature, which leads to less accurate results. To tackle this challenge, in this paper, a novel end-to-end architecture is proposed using conditional Wasserstein Generative Adversarial Networks and a transformer model for answer generation in Chatbots. While the generator of the proposed model consists of a full transformer model to generate an answer, the discriminator includes only the encoder part of a transformer model followed by a classifier. To the best of our knowledge, this is the first time that a generative Chatbot is proposed using the embedded transformer in both generator and discriminator models. Relying on the parallel computing of the transformer model, the results of the proposed model on the Cornell Movie-Dialog corpus and the Chit-Chat datasets confirm the superiority of the proposed model compared to state-of-the-art alternatives using different evaluation metrics.
LUKE-Graph: A Transformer-based Approach with Gated Relational Graph Attention for Cloze-style Reading Comprehension
Mar 12, 2023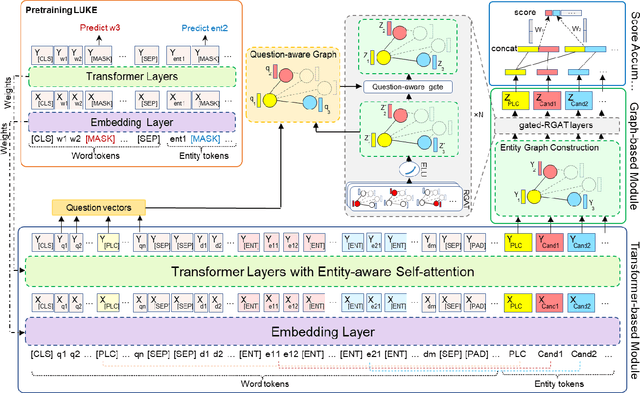
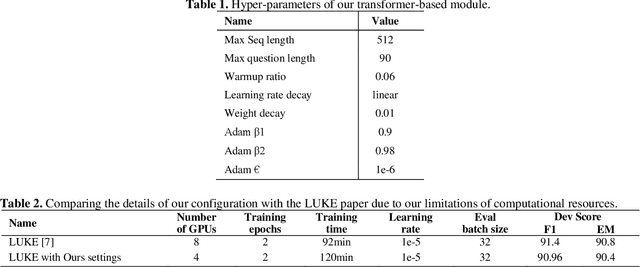
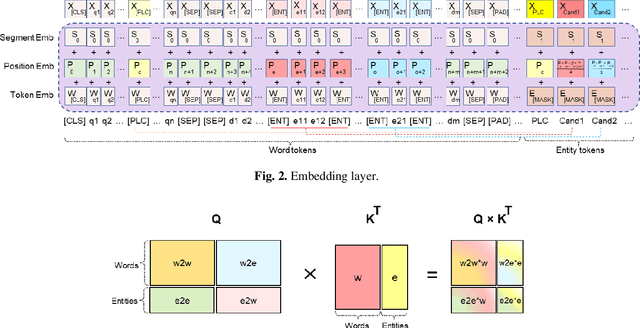
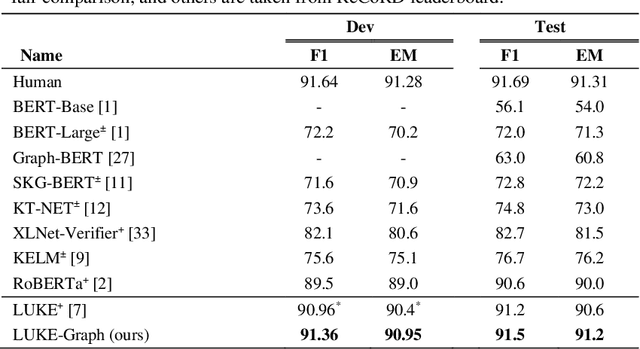
Incorporating prior knowledge can improve existing pre-training models in cloze-style machine reading and has become a new trend in recent studies. Notably, most of the existing models have integrated external knowledge graphs (KG) and transformer-based models, such as BERT into a unified data structure. However, selecting the most relevant ambiguous entities in KG and extracting the best subgraph remains a challenge. In this paper, we propose the LUKE-Graph, a model that builds a heterogeneous graph based on the intuitive relationships between entities in a document without using any external KG. We then use a Relational Graph Attention (RGAT) network to fuse the graph's reasoning information and the contextual representation encoded by the pre-trained LUKE model. In this way, we can take advantage of LUKE, to derive an entity-aware representation; and a graph model - to exploit relation-aware representation. Moreover, we propose Gated-RGAT by augmenting RGAT with a gating mechanism that regulates the question information for the graph convolution operation. This is very similar to human reasoning processing because they always choose the best entity candidate based on the question information. Experimental results demonstrate that the LUKE-Graph achieves state-of-the-art performance on the ReCoRD dataset with commonsense reasoning.
A Non-Anatomical Graph Structure for isolated hand gesture separation in continuous gesture sequences
Jul 15, 2022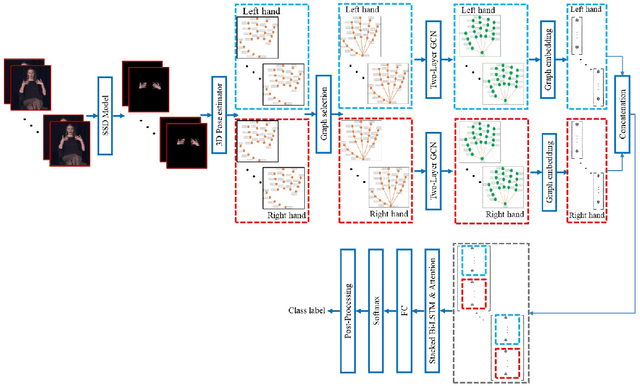
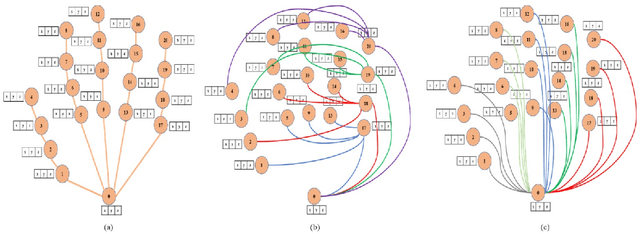
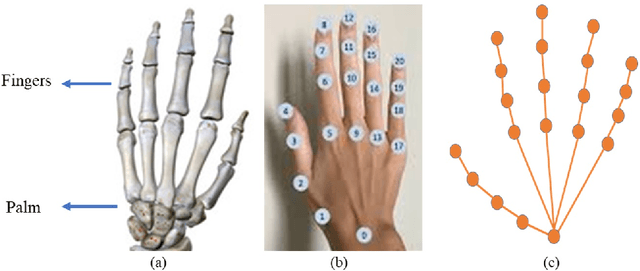
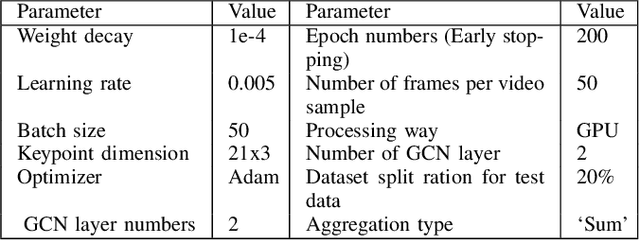
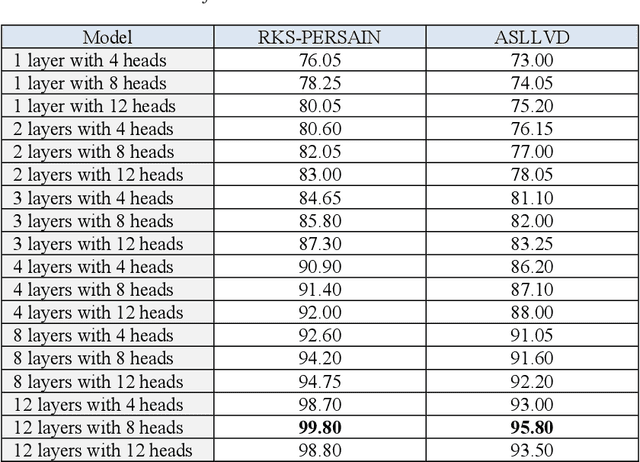
Continuous Hand Gesture Recognition (CHGR) has been extensively studied by researchers in the last few decades. Recently, one model has been presented to deal with the challenge of the boundary detection of isolated gestures in a continuous gesture video [17]. To enhance the model performance and also replace the handcrafted feature extractor in the presented model in [17], we propose a GCN model and combine it with the stacked Bi-LSTM and Attention modules to push the temporal information in the video stream. Considering the breakthroughs of GCN models for skeleton modality, we propose a two-layer GCN model to empower the 3D hand skeleton features. Finally, the class probabilities of each isolated gesture are fed to the post-processing module, borrowed from [17]. Furthermore, we replace the anatomical graph structure with some non-anatomical graph structures. Due to the lack of a large dataset, including both the continuous gesture sequences and the corresponding isolated gestures, three public datasets in Dynamic Hand Gesture Recognition (DHGR), RKS-PERSIANSIGN, and ASLVID, are used for evaluation. Experimental results show the superiority of the proposed model in dealing with isolated gesture boundaries detection in continuous gesture sequences
Word separation in continuous sign language using isolated signs and post-processing
Apr 13, 2022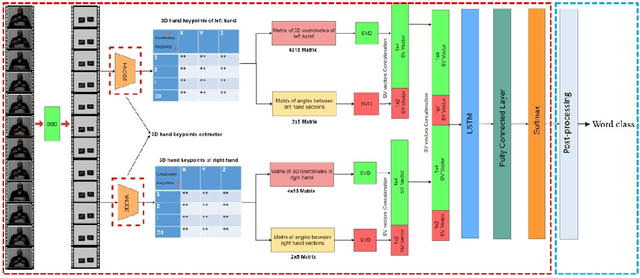

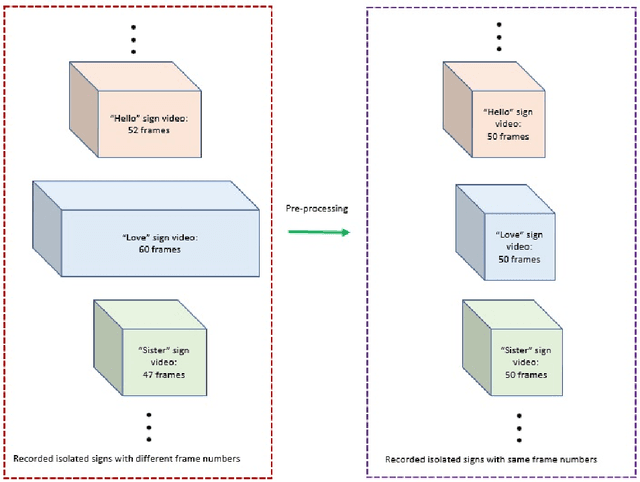

Continuous Sign Language Recognition (CSLR) is a long challenging task in Computer Vision due to the difficulties in detecting the explicit boundaries between the words in a sign sentence. To deal with this challenge, we propose a two-stage model. In the first stage, the predictor model, which includes a combination of CNN, SVD, and LSTM, is trained with the isolated signs. In the second stage, we apply a post-processing algorithm to the Softmax outputs obtained from the first part of the model in order to separate the isolated signs in the continuous signs. Due to the lack of a large dataset, including both the sign sequences and the corresponding isolated signs, two public datasets in Isolated Sign Language Recognition (ISLR), RKS-PERSIANSIGN and ASLVID, are used for evaluation. Results of the continuous sign videos confirm the efficiency of the proposed model to deal with isolated sign boundaries detection.
All You Need In Sign Language Production
Jan 06, 2022
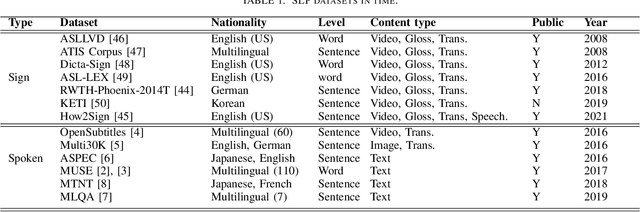

Sign Language is the dominant form of communication language used in the deaf and hearing-impaired community. To make an easy and mutual communication between the hearing-impaired and the hearing communities, building a robust system capable of translating the spoken language into sign language and vice versa is fundamental. To this end, sign language recognition and production are two necessary parts for making such a two-way system. Sign language recognition and production need to cope with some critical challenges. In this survey, we review recent advances in Sign Language Production (SLP) and related areas using deep learning. To have more realistic perspectives to sign language, we present an introduction to the Deaf culture, Deaf centers, psychological perspective of sign language, the main differences between spoken language and sign language. Furthermore, we present the fundamental components of a bi-directional sign language translation system, discussing the main challenges in this area. Also, the backbone architectures and methods in SLP are briefly introduced and the proposed taxonomy on SLP is presented. Finally, a general framework for SLP and performance evaluation, and also a discussion on the recent developments, advantages, and limitations in SLP, commenting on possible lines for future research are presented.