 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWord separation in continuous sign language using isolated signs and post-processing
Paper and Code
Apr 13, 2022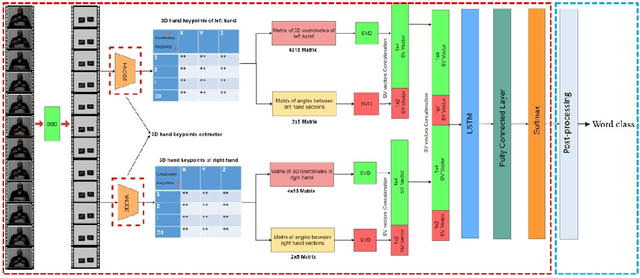

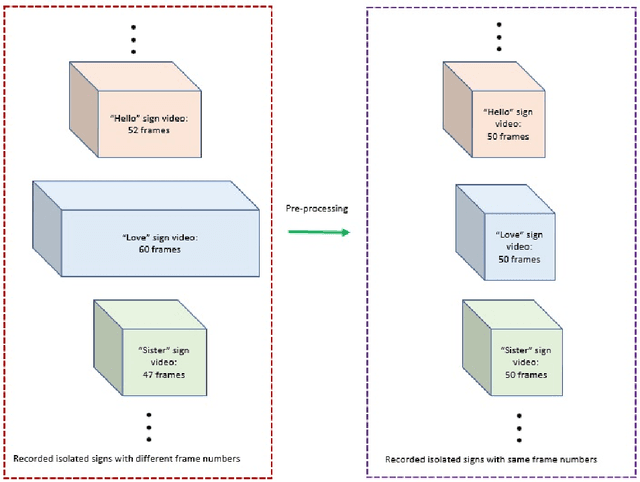

Continuous Sign Language Recognition (CSLR) is a long challenging task in Computer Vision due to the difficulties in detecting the explicit boundaries between the words in a sign sentence. To deal with this challenge, we propose a two-stage model. In the first stage, the predictor model, which includes a combination of CNN, SVD, and LSTM, is trained with the isolated signs. In the second stage, we apply a post-processing algorithm to the Softmax outputs obtained from the first part of the model in order to separate the isolated signs in the continuous signs. Due to the lack of a large dataset, including both the sign sequences and the corresponding isolated signs, two public datasets in Isolated Sign Language Recognition (ISLR), RKS-PERSIANSIGN and ASLVID, are used for evaluation. Results of the continuous sign videos confirm the efficiency of the proposed model to deal with isolated sign boundaries detection.