 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRecent Advances in Multi-Choice Machine Reading Comprehension: A Survey on Methods and Datasets
Aug 04, 2024This paper provides a thorough examination of recent developments in the field of multi-choice Machine Reading Comprehension (MRC). Focused on benchmark datasets, methodologies, challenges, and future trajectories, our goal is to offer researchers a comprehensive overview of the current landscape in multi-choice MRC. The analysis delves into 30 existing cloze-style and multiple-choice MRC benchmark datasets, employing a refined classification method based on attributes such as corpus style, domain, complexity, context style, question style, and answer style. This classification system enhances our understanding of each dataset's diverse attributes and categorizes them based on their complexity. Furthermore, the paper categorizes recent methodologies into Fine-tuned and Prompt-tuned methods. Fine-tuned methods involve adapting pre-trained language models (PLMs) to a specific task through retraining on domain-specific datasets, while prompt-tuned methods use prompts to guide PLM response generation, presenting potential applications in zero-shot or few-shot learning scenarios. By contributing to ongoing discussions, inspiring future research directions, and fostering innovations, this paper aims to propel multi-choice MRC towards new frontiers of achievement.
Integrating a Heterogeneous Graph with Entity-aware Self-attention using Relative Position Labels for Reading Comprehension Model
Jul 22, 2023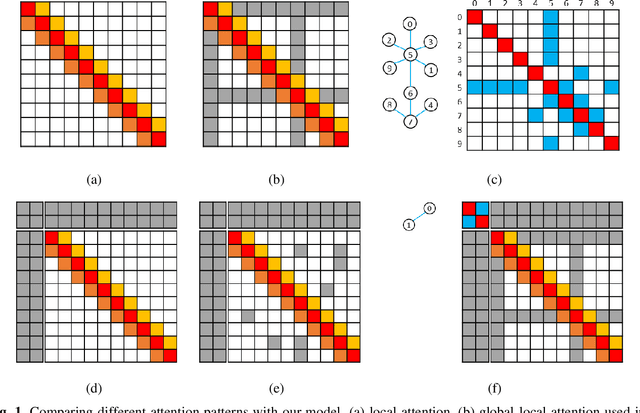
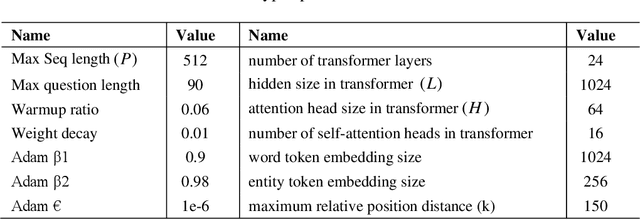
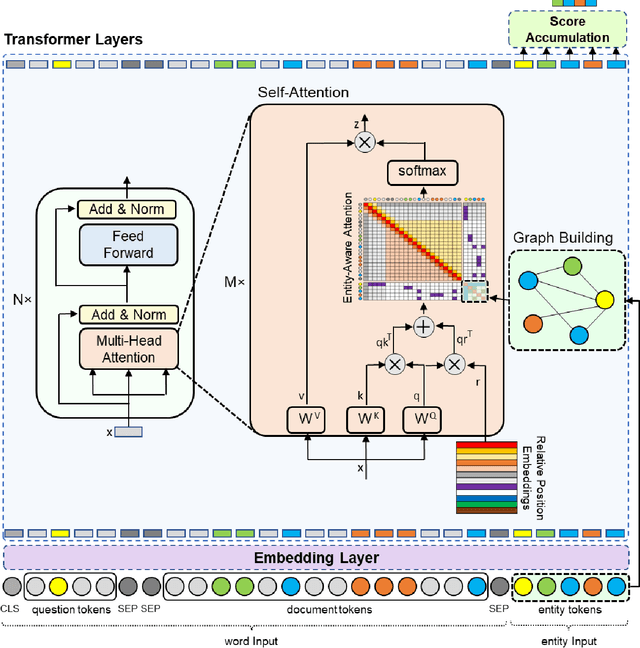
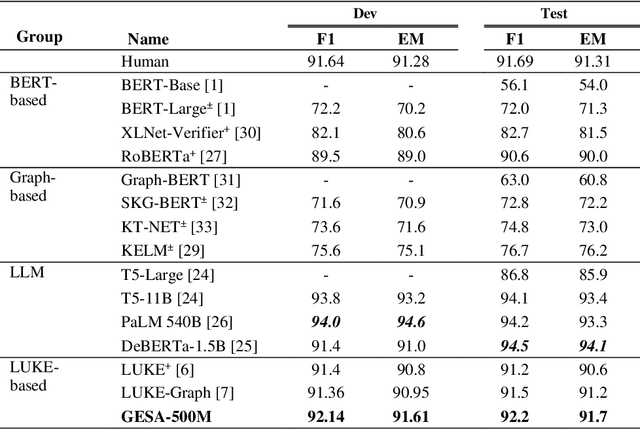
Despite the significant progress made by transformer models in machine reading comprehension tasks, they still fall short in handling complex reasoning tasks due to the absence of explicit knowledge in the input sequence. To address this limitation, many recent works have proposed injecting external knowledge into the model. However, selecting relevant external knowledge, ensuring its availability, and requiring additional processing steps remain challenging. In this paper, we introduce a novel attention pattern that integrates reasoning knowledge derived from a heterogeneous graph into the transformer architecture without relying on external knowledge. The proposed attention pattern comprises three key elements: global-local attention for word tokens, graph attention for entity tokens that exhibit strong attention towards tokens connected in the graph as opposed to those unconnected, and the consideration of the type of relationship between each entity token and word token. This results in optimized attention between the two if a relationship exists. The pattern is coupled with special relative position labels, allowing it to integrate with LUKE's entity-aware self-attention mechanism. The experimental findings corroborate that our model outperforms both the cutting-edge LUKE-Graph and the baseline LUKE model on the ReCoRD dataset that focuses on commonsense reasoning.
LUKE-Graph: A Transformer-based Approach with Gated Relational Graph Attention for Cloze-style Reading Comprehension
Mar 12, 2023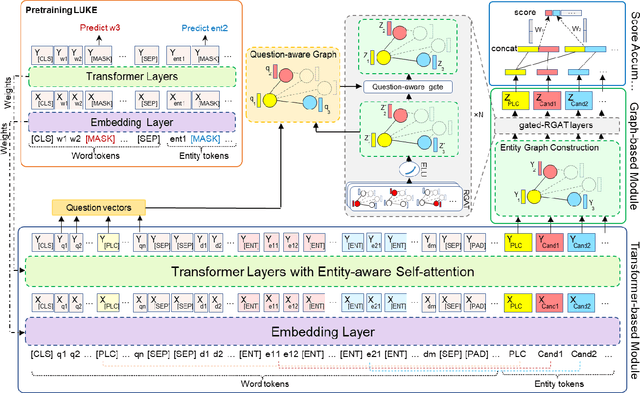
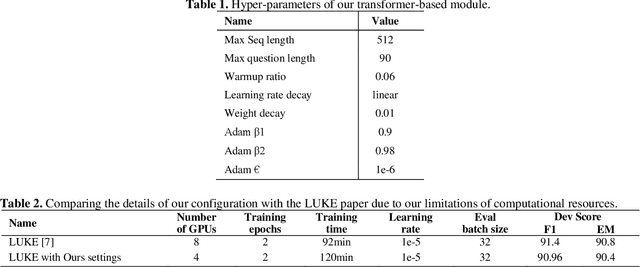
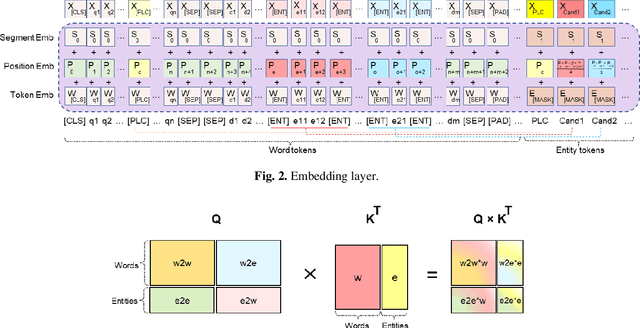
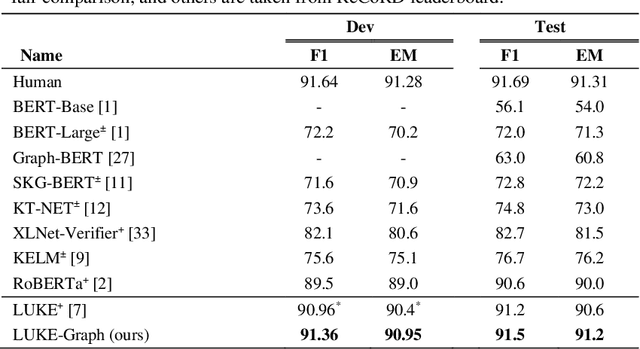
Incorporating prior knowledge can improve existing pre-training models in cloze-style machine reading and has become a new trend in recent studies. Notably, most of the existing models have integrated external knowledge graphs (KG) and transformer-based models, such as BERT into a unified data structure. However, selecting the most relevant ambiguous entities in KG and extracting the best subgraph remains a challenge. In this paper, we propose the LUKE-Graph, a model that builds a heterogeneous graph based on the intuitive relationships between entities in a document without using any external KG. We then use a Relational Graph Attention (RGAT) network to fuse the graph's reasoning information and the contextual representation encoded by the pre-trained LUKE model. In this way, we can take advantage of LUKE, to derive an entity-aware representation; and a graph model - to exploit relation-aware representation. Moreover, we propose Gated-RGAT by augmenting RGAT with a gating mechanism that regulates the question information for the graph convolution operation. This is very similar to human reasoning processing because they always choose the best entity candidate based on the question information. Experimental results demonstrate that the LUKE-Graph achieves state-of-the-art performance on the ReCoRD dataset with commonsense reasoning.