 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePushing the Envelope for Depth-Based Semi-Supervised 3D Hand Pose Estimation with Consistency Training
Mar 27, 2023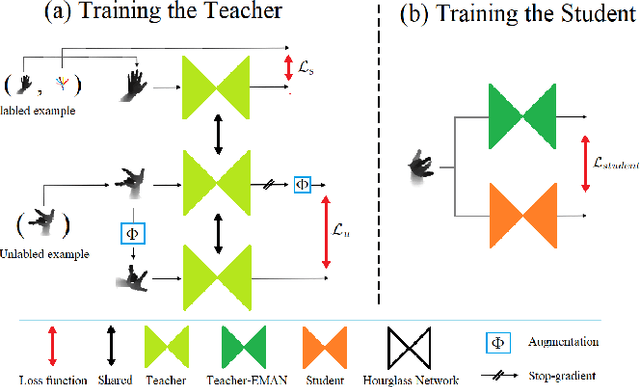
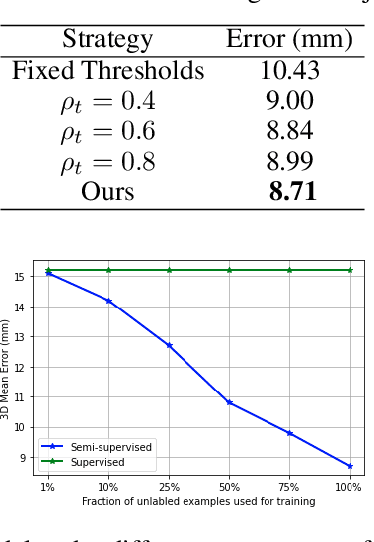

Despite the significant progress that depth-based 3D hand pose estimation methods have made in recent years, they still require a large amount of labeled training data to achieve high accuracy. However, collecting such data is both costly and time-consuming. To tackle this issue, we propose a semi-supervised method to significantly reduce the dependence on labeled training data. The proposed method consists of two identical networks trained jointly: a teacher network and a student network. The teacher network is trained using both the available labeled and unlabeled samples. It leverages the unlabeled samples via a loss formulation that encourages estimation equivariance under a set of affine transformations. The student network is trained using the unlabeled samples with their pseudo-labels provided by the teacher network. For inference at test time, only the student network is used. Extensive experiments demonstrate that the proposed method outperforms the state-of-the-art semi-supervised methods by large margins.
TriHorn-Net: A Model for Accurate Depth-Based 3D Hand Pose Estimation
Jun 14, 2022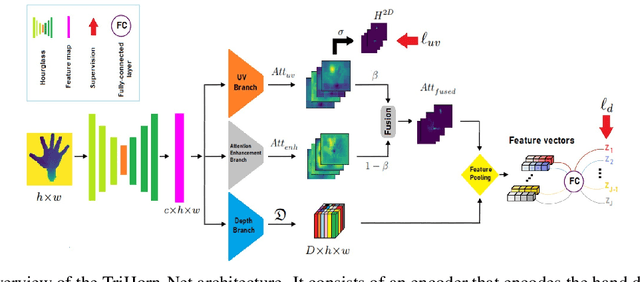

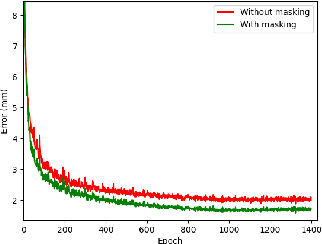
3D hand pose estimation methods have made significant progress recently. However, estimation accuracy is often far from sufficient for specific real-world applications, and thus there is significant room for improvement. This paper proposes TriHorn-Net, a novel model that uses specific innovations to improve hand pose estimation accuracy on depth images. The first innovation is the decomposition of the 3D hand pose estimation into the estimation of 2D joint locations in the depth image space (UV), and the estimation of their corresponding depths aided by two complementary attention maps. This decomposition prevents depth estimation, which is a more difficult task, from interfering with the UV estimations at both the prediction and feature levels. The second innovation is PixDropout, which is, to the best of our knowledge, the first appearance-based data augmentation method for hand depth images. Experimental results demonstrate that the proposed model outperforms the state-of-the-art methods on three public benchmark datasets.
Content-based image retrieval using Mix histogram
Sep 20, 2019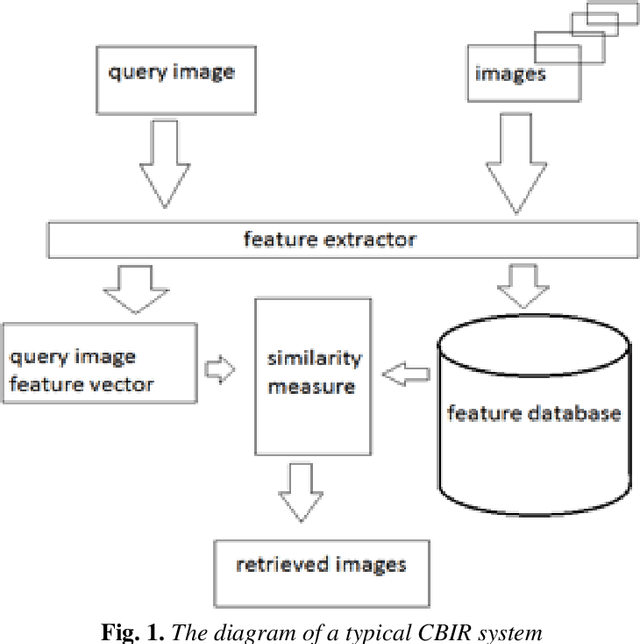
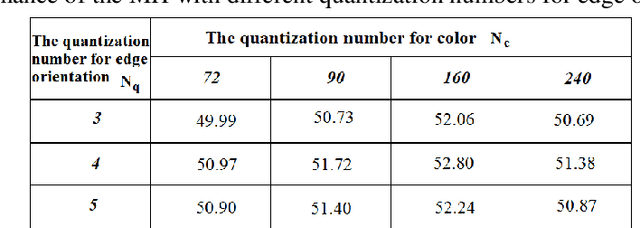
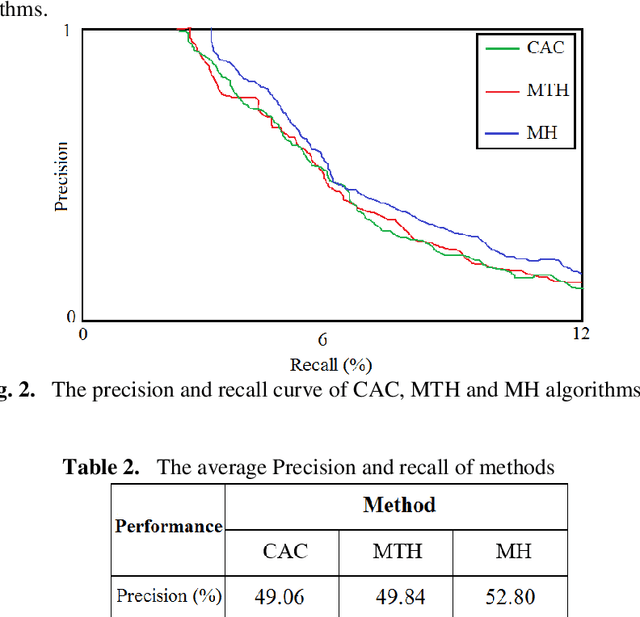

This paper presents a new method to extract image low-level features, namely mix histogram (MH), for content-based image retrieval. Since color and edge orientation features are important visual information which help the human visual system percept and discriminate different images, this method extracts and integrates color and edge orientation information in order to measure similarity between different images. Traditional color histograms merely focus on the global distribution of color in the image and therefore fail to extract other visual features. The MH is attempting to overcome this problem by extracting edge orientations as well as color feature. The unique characteristic of the MH is that it takes into consideration both color and edge orientation information in an effective manner. Experimental results show that it outperforms many existing methods which were originally developed for image retrieval purposes.
Persian Signature Verification using Fully Convolutional Networks
Sep 20, 2019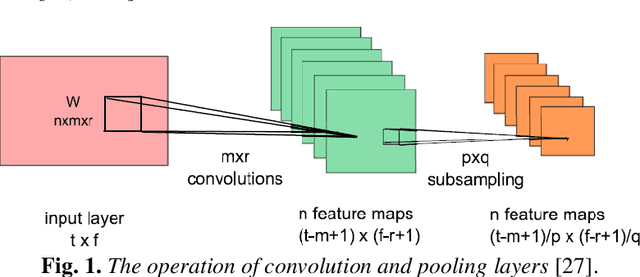


Fully convolutional networks (FCNs) have been recently used for feature extraction and classification in image and speech recognition, where their inputs have been raw signal or other complicated features. Persian signature verification is done using conventional convolutional neural networks (CNNs). In this paper, we propose to use FCN for learning a robust feature extraction from the raw signature images. FCN can be considered as a variant of CNN where its fully connected layers are replaced with a global pooling layer. In the proposed manner, FCN inputs are raw signature images and convolution filter size is fixed. Recognition accuracy on UTSig database, shows that FCN with a global average pooling outperforms CNN.