 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVegaChat: A Robust Framework for LLM-Based Chart Generation and Assessment
Jan 21, 2026Natural-language-to-visualization (NL2VIS) systems based on large language models (LLMs) have substantially improved the accessibility of data visualization. However, their further adoption is hindered by two coupled challenges: (i) the absence of standardized evaluation metrics makes it difficult to assess progress in the field and compare different approaches; and (ii) natural language descriptions are inherently underspecified, so multiple visualizations may be valid for the same query. To address these issues, we introduce VegaChat, a framework for generating, validating, and assessing declarative visualizations from natural language. We propose two complementary metrics: Spec Score, a deterministic metric that measures specification-level similarity without invoking an LLM, and Vision Score, a library-agnostic, image-based metric that leverages a multimodal LLM to assess chart similarity and prompt compliance. We evaluate VegaChat on the NLV Corpus and on the annotated subset of ChartLLM. VegaChat achieves near-zero rates of invalid or empty visualizations, while Spec Score and Vision Score exhibit strong correlation with human judgments (Pearson 0.65 and 0.71, respectively), indicating that the proposed metrics support consistent, cross-library comparison. The code and evaluation artifacts are available at https://zenodo.org/records/17062309.
Molecular Sets (MOSES): A Benchmarking Platform for Molecular Generation Models
Nov 29, 2018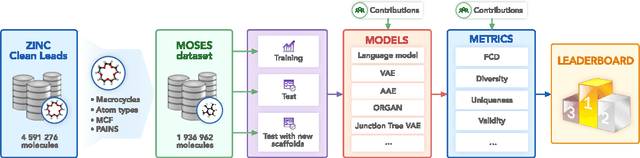


Deep generative models such as generative adversarial networks, variational autoencoders, and autoregressive models are rapidly growing in popularity for the discovery of new molecules and materials. In this work, we introduce MOlecular SEtS (MOSES), a benchmarking platform to support research on machine learning for drug discovery. MOSES implements several popular molecular generation models and includes a set of metrics that evaluate the diversity and quality of generated molecules. MOSES is meant to standardize the research on the molecular generation and facilitate the sharing and comparison of new models. Additionally, we provide a large-scale comparison of existing state of the art models and elaborate on current challenges for generative models that might prove fertile ground for new research. Our platform and source code are freely available at https://github.com/molecularsets/