 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExtrapolating Expected Accuracies for Large Multi-Class Problems
Dec 27, 2017

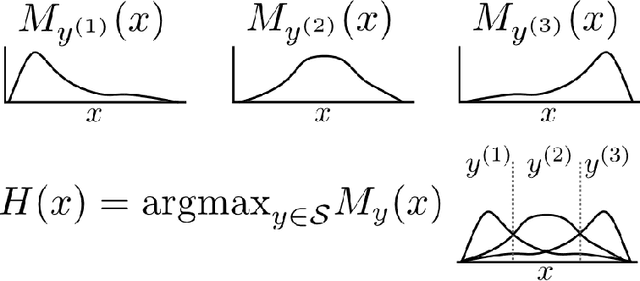
The difficulty of multi-class classification generally increases with the number of classes. Using data from a subset of the classes, can we predict how well a classifier will scale with an increased number of classes? Under the assumptions that the classes are sampled identically and independently from a population, and that the classifier is based on independently learned scoring functions, we show that the expected accuracy when the classifier is trained on k classes is the (k-1)st moment of a certain distribution that can be estimated from data. We present an unbiased estimation method based on the theory, and demonstrate its application on a facial recognition example.
Telugu OCR Framework using Deep Learning
Feb 15, 2017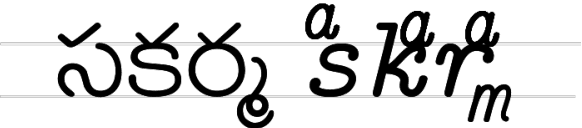
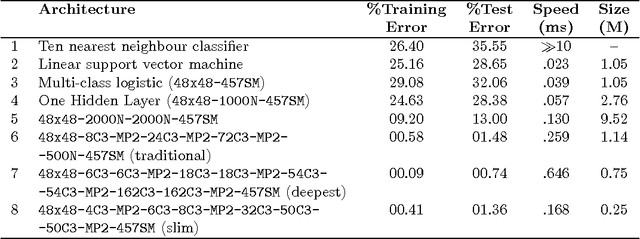


In this paper, we address the task of Optical Character Recognition(OCR) for the Telugu script. We present an end-to-end framework that segments the text image, classifies the characters and extracts lines using a language model. The segmentation is based on mathematical morphology. The classification module, which is the most challenging task of the three, is a deep convolutional neural network. The language is modelled as a third degree markov chain at the glyph level. Telugu script is a complex alphasyllabary and the language is agglutinative, making the problem hard. In this paper we apply the latest advances in neural networks to achieve state-of-the-art error rates. We also review convolutional neural networks in great detail and expound the statistical justification behind the many tricks needed to make Deep Learning work.
How many faces can be recognized? Performance extrapolation for multi-class classification
Jun 16, 2016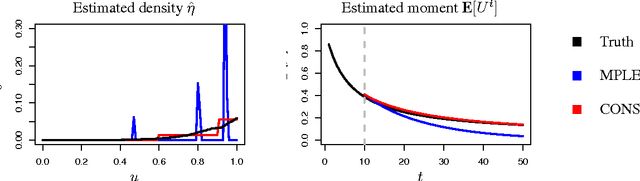

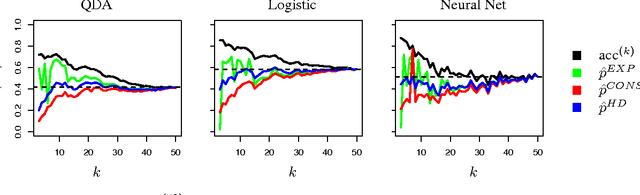
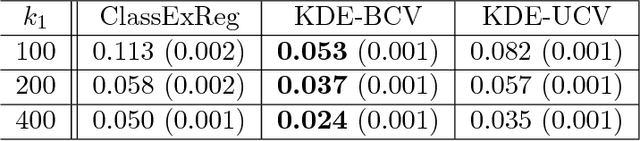
The difficulty of multi-class classification generally increases with the number of classes. Using data from a subset of the classes, can we predict how well a classifier will scale with an increased number of classes? Under the assumption that the classes are sampled exchangeably, and under the assumption that the classifier is generative (e.g. QDA or Naive Bayes), we show that the expected accuracy when the classifier is trained on $k$ classes is the $k-1$st moment of a \emph{conditional accuracy distribution}, which can be estimated from data. This provides the theoretical foundation for performance extrapolation based on pseudolikelihood, unbiased estimation, and high-dimensional asymptotics. We investigate the robustness of our methods to non-generative classifiers in simulations and one optical character recognition example.