 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTelugu OCR Framework using Deep Learning
Paper and Code
Feb 15, 2017
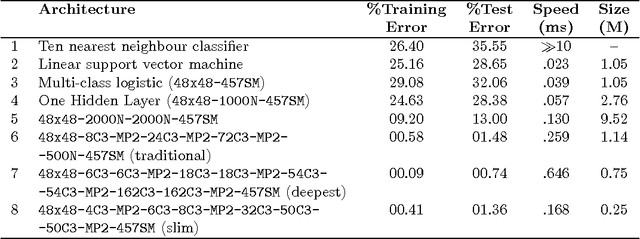


In this paper, we address the task of Optical Character Recognition(OCR) for the Telugu script. We present an end-to-end framework that segments the text image, classifies the characters and extracts lines using a language model. The segmentation is based on mathematical morphology. The classification module, which is the most challenging task of the three, is a deep convolutional neural network. The language is modelled as a third degree markov chain at the glyph level. Telugu script is a complex alphasyllabary and the language is agglutinative, making the problem hard. In this paper we apply the latest advances in neural networks to achieve state-of-the-art error rates. We also review convolutional neural networks in great detail and expound the statistical justification behind the many tricks needed to make Deep Learning work.