 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSuicidal Comment Tree Dataset: Enhancing Risk Assessment and Prediction Through Contextual Analysis
Oct 16, 2025Suicide remains a critical global public health issue. While previous studies have provided valuable insights into detecting suicidal expressions in individual social media posts, limited attention has been paid to the analysis of longitudinal, sequential comment trees for predicting a user's evolving suicidal risk. Users, however, often reveal their intentions through historical posts and interactive comments over time. This study addresses this gap by investigating how the information in comment trees affects both the discrimination and prediction of users' suicidal risk levels. We constructed a high-quality annotated dataset, sourced from Reddit, which incorporates users' posting history and comments, using a refined four-label annotation framework based on the Columbia Suicide Severity Rating Scale (C-SSRS). Statistical analysis of the dataset, along with experimental results from Large Language Models (LLMs) experiments, demonstrates that incorporating comment trees data significantly enhances the discrimination and prediction of user suicidal risk levels. This research offers a novel insight to enhancing the detection accuracy of at-risk individuals, thereby providing a valuable foundation for early suicide intervention strategies.
New Boolean satisfiability problem heuristic strategy: Minimal Positive Negative Product Strategy
Oct 26, 2023This study presents a novel heuristic algorithm called the "Minimal Positive Negative Product Strategy" to guide the CDCL algorithm in solving the Boolean satisfiability problem. It provides a mathematical explanation for the superiority of this algorithm over widely used heuristics such as the Dynamic Largest Individual Sum (DLIS) and the Variable State Independent Decaying Sum (VSIDS). Experimental results further confirm the effectiveness of this heuristic strategy in problem-solving.
Interpretable machine learning optimization (InterOpt) for operational parameters: a case study of highly-efficient shale gas development
Jun 20, 2022



An algorithm named InterOpt for optimizing operational parameters is proposed based on interpretable machine learning, and is demonstrated via optimization of shale gas development. InterOpt consists of three parts: a neural network is used to construct an emulator of the actual drilling and hydraulic fracturing process in the vector space (i.e., virtual environment); the Sharpley value method in interpretable machine learning is applied to analyzing the impact of geological and operational parameters in each well (i.e., single well feature impact analysis); and ensemble randomized maximum likelihood (EnRML) is conducted to optimize the operational parameters to comprehensively improve the efficiency of shale gas development and reduce the average cost. In the experiment, InterOpt provides different drilling and fracturing plans for each well according to its specific geological conditions, and finally achieved an average cost reduction of 9.7% for a case study with 104 wells.
Applications of Social Media in Hydroinformatics: A Survey
May 01, 2019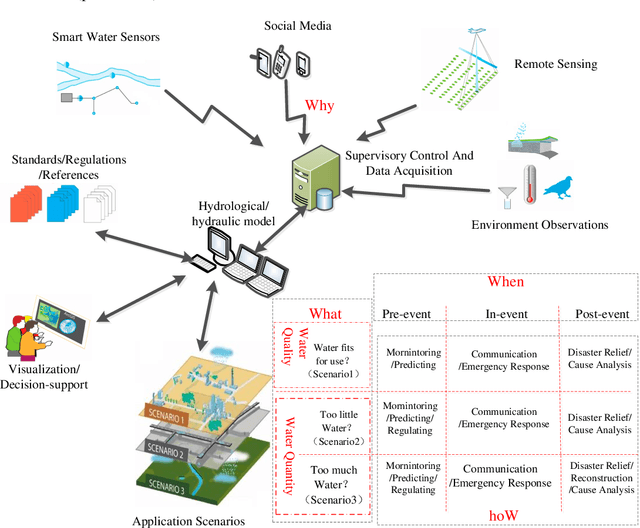
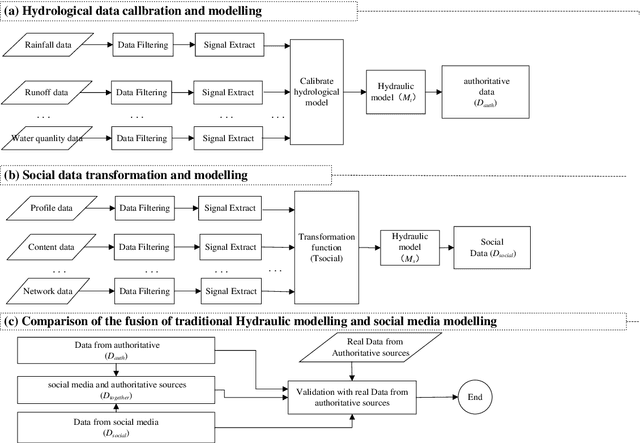
Floods of research and practical applications employ social media data for a wide range of public applications, including environmental monitoring, water resource managing, disaster and emergency response.Hydroinformatics can benefit from the social media technologies with newly emerged data, techniques and analytical tools to handle large datasets, from which creative ideas and new values could be mined.This paper first proposes a 4W (What, Why, When, hoW) model and a methodological structure to better understand and represent the application of social media to hydroinformatics, then provides an overview of academic research of applying social media to hydroinformatics such as water environment, water resources, flood, drought and water Scarcity management. At last,some advanced topics and suggestions of water related social media applications from data collection, data quality management, fake news detection, privacy issues, algorithms and platforms was present to hydroinformatics managers and researchers based on previous discussion.
A Novel Trend Symbolic Aggregate Approximation for Time Series
May 01, 2019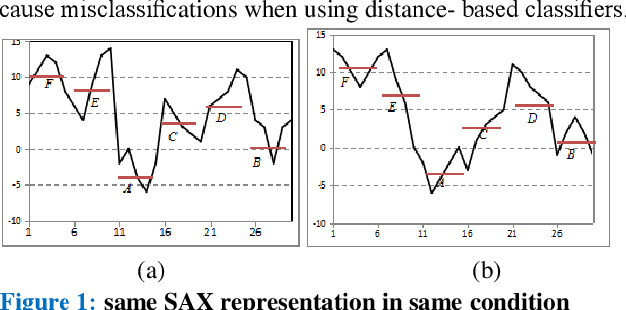
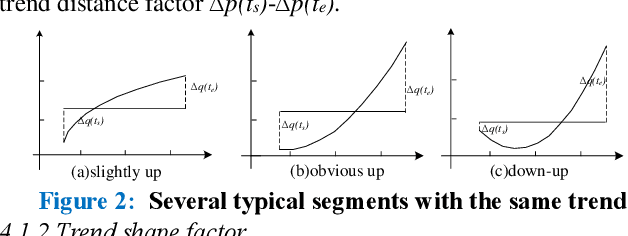
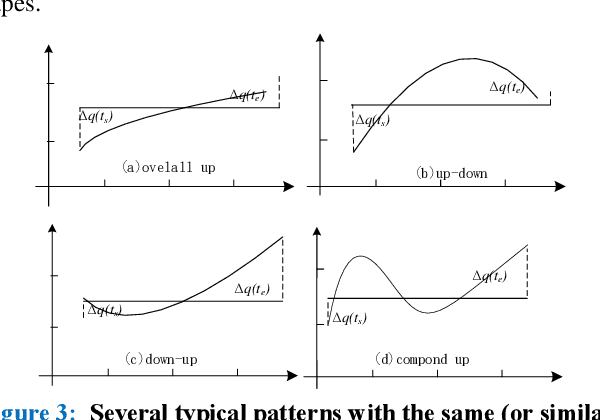
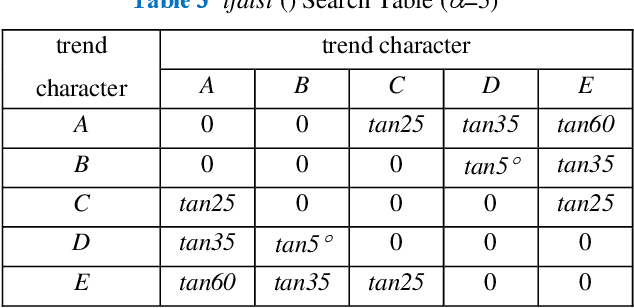
Symbolic Aggregate approximation (SAX) is a classical symbolic approach in many time series data mining applications. However, SAX only reflects the segment mean value feature and misses important information in a segment, namely the trend of the value change in the segment. Such a miss may cause a wrong classification in some cases, since the SAX representation cannot distinguish different time series with similar average values but different trends. In this paper, we present Trend Feature Symbolic Aggregate approximation (TFSAX) to solve this problem. First, we utilize Piecewise Aggregate Approximation (PAA) approach to reduce dimensionality and discretize the mean value of each segment by SAX. Second, extract trend feature in each segment by using trend distance factor and trend shape factor. Then, design multi-resolution symbolic mapping rules to discretize trend information into symbols. We also propose a modified distance measure by integrating the SAX distance with a weighted trend distance. We show that our distance measure has a tighter lower bound to the Euclidean distance than that of the original SAX. The experimental results on diverse time series data sets demonstrate that our proposed representation significantly outperforms the original SAX representation and an improved SAX representation for classification.