 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLoRA-Squeeze: Simple and Effective Post-Tuning and In-Tuning Compression of LoRA Modules
Feb 11, 2026Despite its huge number of variants, standard Low-Rank Adaptation (LoRA) is still a dominant technique for parameter-efficient fine-tuning (PEFT). Nonetheless, it faces persistent challenges, including the pre-selection of an optimal rank and rank-specific hyper-parameters, as well as the deployment complexity of heterogeneous-rank modules and more sophisticated LoRA derivatives. In this work, we introduce LoRA-Squeeze, a simple and efficient methodology that aims to improve standard LoRA learning by changing LoRA module ranks either post-hoc or dynamically during training}. Our approach posits that it is better to first learn an expressive, higher-rank solution and then compress it, rather than learning a constrained, low-rank solution directly. The method involves fine-tuning with a deliberately high(er) source rank, reconstructing or efficiently approximating the reconstruction of the full weight update matrix, and then using Randomized Singular Value Decomposition (RSVD) to create a new, compressed LoRA module at a lower target rank. Extensive experiments across 13 text and 10 vision-language tasks show that post-hoc compression often produces lower-rank adapters that outperform those trained directly at the target rank, especially if a small number of fine-tuning steps at the target rank is allowed. Moreover, a gradual, in-tuning rank annealing variant of LoRA-Squeeze consistently achieves the best LoRA size-performance trade-off.
Parameter-Efficient Transfer Learning for NLP
Feb 02, 2019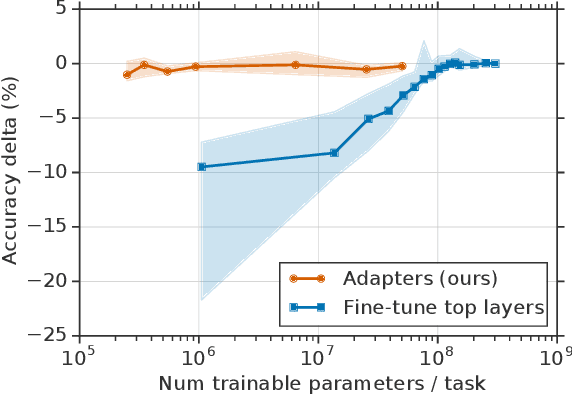

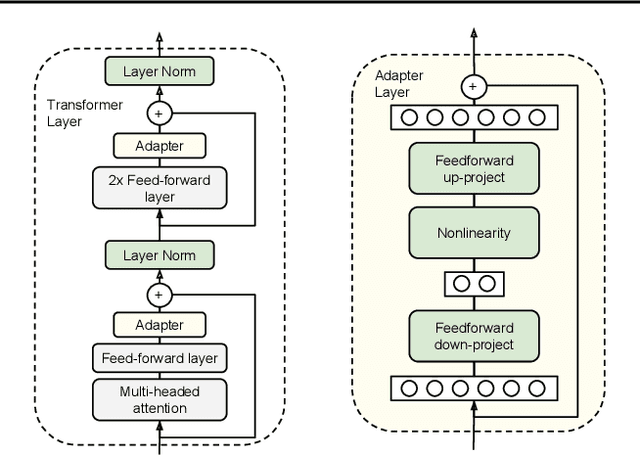

Fine-tuning large pre-trained models is an effective transfer mechanism in NLP. However, in the presence of many downstream tasks, fine-tuning is parameter inefficient: an entire new model is required for every task. As an alternative, we propose transfer with adapter modules. Adapter modules yield a compact and extensible model; they add only a few trainable parameters per task, and new tasks can be added without revisiting previous ones. The parameters of the original network remain fixed, yielding a high degree of parameter sharing. To demonstrate adapter's effectiveness, we transfer the recently proposed BERT Transformer model to 26 diverse text classification tasks, including the GLUE benchmark. Adapters attain near state-of-the-art performance, whilst adding only a few parameters per task. On GLUE, we attain within 0.4% of the performance of full fine-tuning, adding only 3.6% parameters per task. By contrast, fine-tuning trains 100% of the parameters per task.
Neural Architecture Search Over a Graph Search Space
Dec 27, 2018

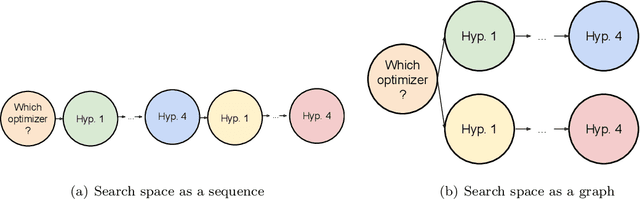

Neural architecture search (NAS) enabled the discovery of state-of-the-art architectures in many domains. However, the success of NAS depends on the definition of the search space, i.e. the set of the possible to generate neural architectures. State-of-the-art search spaces are defined as a static sequence of decisions and a set of available actions for each decision, where each possible sequence of actions defines an architecture. We propose a more expressive formulation of NAS, using a graph search space. Our search space is defined as a graph where each decision is a vertex and each action is an edge. Thus the sequence of decisions defining an architecture is not fixed but is determined dynamically by the actions selected. The proposed approach allows to model iterative and branching aspects of the architecture design process. In this form, stronger priors about the search can be induced. We demonstrate in simulation basic iterative and branching search structures and show that using the graph representation improves sample efficiency.
Evolutionary-Neural Hybrid Agents for Architecture Search
Nov 24, 2018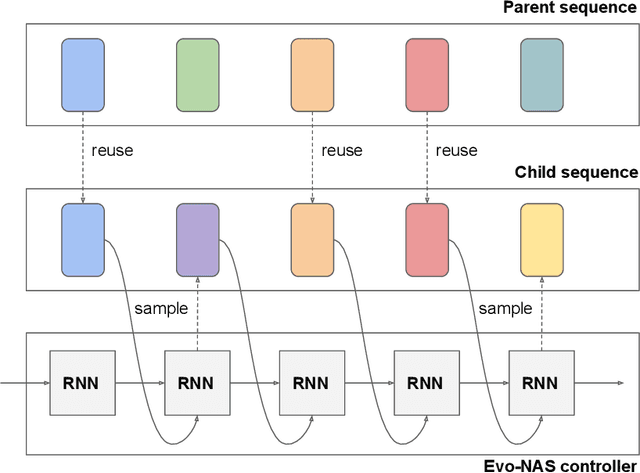
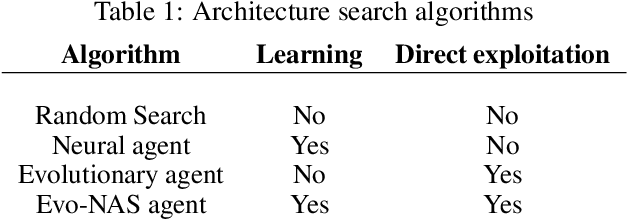
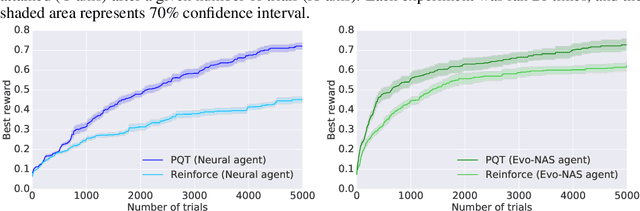

Neural Architecture Search has recently shown potential to automate the design of Neural Networks. The use of Neural Network agents trained with Reinforcement Learning can offer the possibility to learn complex patterns, as well as the ability to explore a vast and compositional search space. On the other hand, evolutionary algorithms offer the greediness and sample efficiency needed for such an application, as each sample requires a considerable amount of resources. We propose a class of Evolutionary-Neural hybrid agents (Evo-NAS), that retain the best qualities of the two approaches. We show that the Evo-NAS agent can outperform both Neural and Evolutionary agents, both on a synthetic task, and on architecture search for a suite of text classification datasets.