 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Generalizable Neuro-Symbolic Systems for Commonsense Question Answering
Oct 30, 2019
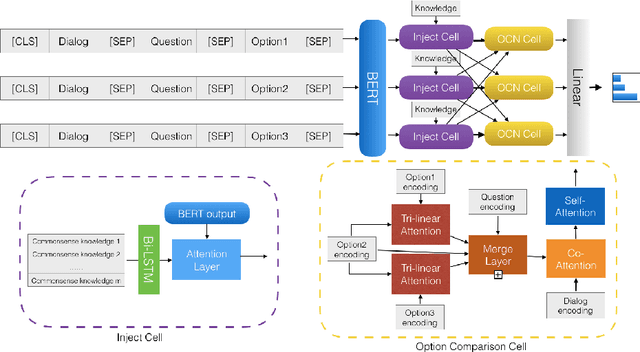


Non-extractive commonsense QA remains a challenging AI task, as it requires systems to reason about, synthesize, and gather disparate pieces of information, in order to generate responses to queries. Recent approaches on such tasks show increased performance, only when models are either pre-trained with additional information or when domain-specific heuristics are used, without any special consideration regarding the knowledge resource type. In this paper, we perform a survey of recent commonsense QA methods and we provide a systematic analysis of popular knowledge resources and knowledge-integration methods, across benchmarks from multiple commonsense datasets. Our results and analysis show that attention-based injection seems to be a preferable choice for knowledge integration and that the degree of domain overlap, between knowledge bases and datasets, plays a crucial role in determining model success.
On Leveraging the Visual Modality for Neural Machine Translation
Oct 07, 2019


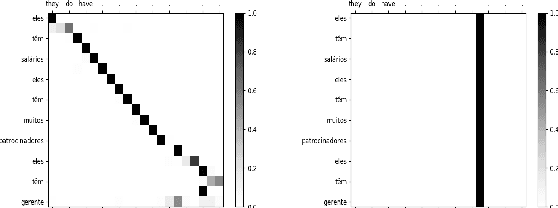
Leveraging the visual modality effectively for Neural Machine Translation (NMT) remains an open problem in computational linguistics. Recently, Caglayan et al. posit that the observed gains are limited mainly due to the very simple, short, repetitive sentences of the Multi30k dataset (the only multimodal MT dataset available at the time), which renders the source text sufficient for context. In this work, we further investigate this hypothesis on a new large scale multimodal Machine Translation (MMT) dataset, How2, which has 1.57 times longer mean sentence length than Multi30k and no repetition. We propose and evaluate three novel fusion techniques, each of which is designed to ensure the utilization of visual context at different stages of the Sequence-to-Sequence transduction pipeline, even under full linguistic context. However, we still obtain only marginal gains under full linguistic context and posit that visual embeddings extracted from deep vision models (ResNet for Multi30k, ResNext for How2) do not lend themselves to increasing the discriminativeness between the vocabulary elements at token level prediction in NMT. We demonstrate this qualitatively by analyzing attention distribution and quantitatively through Principal Component Analysis, arriving at the conclusion that it is the quality of the visual embeddings rather than the length of sentences, which need to be improved in existing MMT datasets.