 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobustCalib: Robust Lidar-Camera Extrinsic Calibration with Consistency Learning
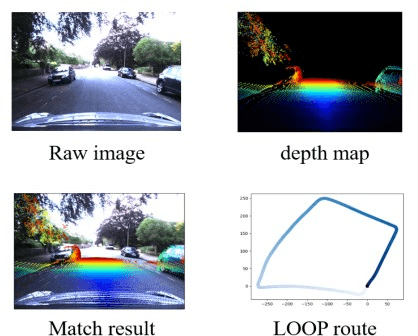
Dec 02, 2023Current traditional methods for LiDAR-camera extrinsics estimation depend on offline targets and human efforts, while learning-based approaches resort to iterative refinement for calibration results, posing constraints on their generalization and application in on-board systems. In this paper, we propose a novel approach to address the extrinsic calibration problem in a robust, automatic, and single-shot manner. Instead of directly optimizing extrinsics, we leverage the consistency learning between LiDAR and camera to implement implicit re-calibartion. Specially, we introduce an appearance-consistency loss and a geometric-consistency loss to minimizing the inconsitency between the attrbutes (e.g., intensity and depth) of projected LiDAR points and the predicted ones. This design not only enhances adaptability to various scenarios but also enables a simple and efficient formulation during inference. We conduct comprehensive experiments on different datasets, and the results demonstrate that our method achieves accurate and robust performance. To promote further research and development in this area, we will release our model and code.
Deep auxiliary learning for visual localization using colorization task
Jul 01, 2021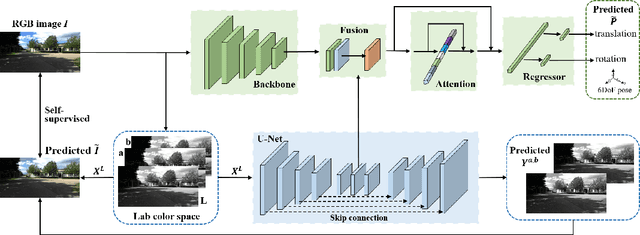
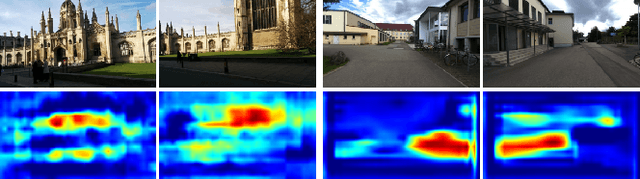
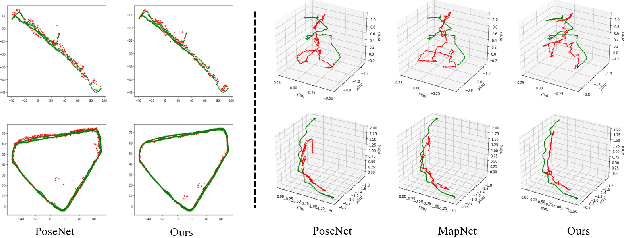

Visual localization is one of the most important components for robotics and autonomous driving. Recently, inspiring results have been shown with CNN-based methods which provide a direct formulation to end-to-end regress 6-DoF absolute pose. Additional information like geometric or semantic constraints is generally introduced to improve performance. Especially, the latter can aggregate high-level semantic information into localization task, but it usually requires enormous manual annotations. To this end, we propose a novel auxiliary learning strategy for camera localization by introducing scene-specific high-level semantics from self-supervised representation learning task. Viewed as a powerful proxy task, image colorization task is chosen as complementary task that outputs pixel-wise color version of grayscale photograph without extra annotations. In our work, feature representations from colorization network are embedded into localization network by design to produce discriminative features for pose regression. Meanwhile an attention mechanism is introduced for the benefit of localization performance. Extensive experiments show that our model significantly improve localization accuracy over state-of-the-arts on both indoor and outdoor datasets.
3D Scene Geometry-Aware Constraint for Camera Localization with Deep Learning
May 13, 2020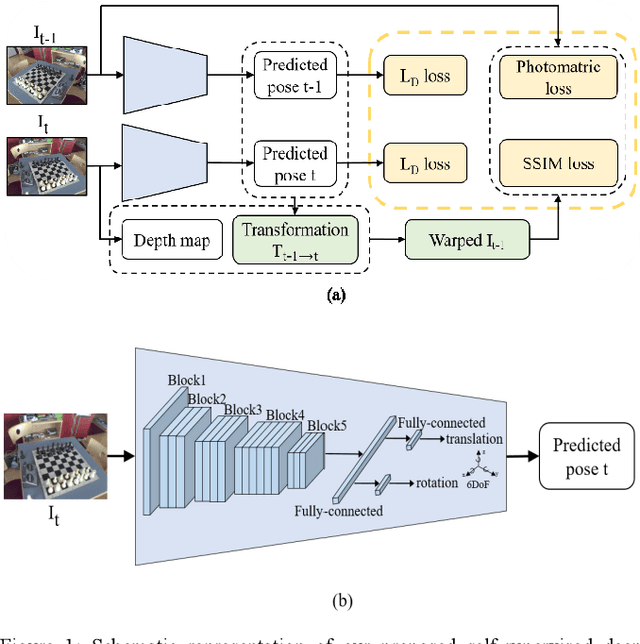
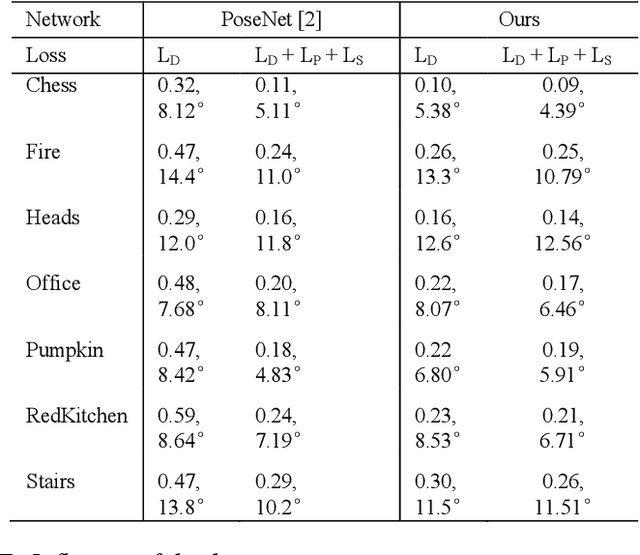
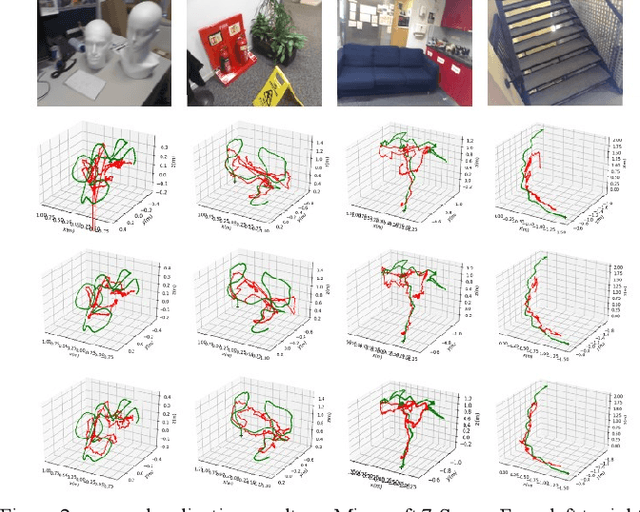
Camera localization is a fundamental and key component of autonomous driving vehicles and mobile robots to localize themselves globally for further environment perception, path planning and motion control. Recently end-to-end approaches based on convolutional neural network have been much studied to achieve or even exceed 3D-geometry based traditional methods. In this work, we propose a compact network for absolute camera pose regression. Inspired from those traditional methods, a 3D scene geometry-aware constraint is also introduced by exploiting all available information including motion, depth and image contents. We add this constraint as a regularization term to our proposed network by defining a pixel-level photometric loss and an image-level structural similarity loss. To benchmark our method, different challenging scenes including indoor and outdoor environment are tested with our proposed approach and state-of-the-arts. And the experimental results demonstrate significant performance improvement of our method on both prediction accuracy and convergence efficiency.