 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep auxiliary learning for visual localization using colorization task
Jul 01, 2021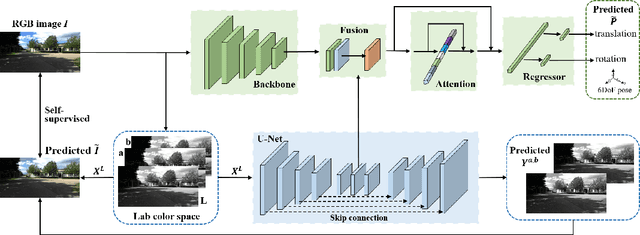
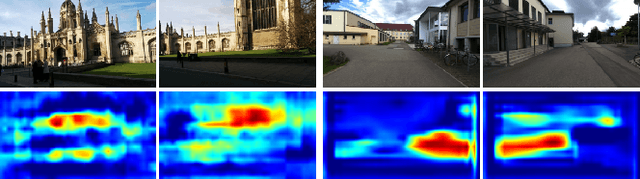
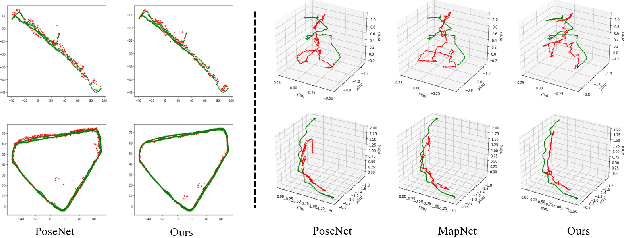

Visual localization is one of the most important components for robotics and autonomous driving. Recently, inspiring results have been shown with CNN-based methods which provide a direct formulation to end-to-end regress 6-DoF absolute pose. Additional information like geometric or semantic constraints is generally introduced to improve performance. Especially, the latter can aggregate high-level semantic information into localization task, but it usually requires enormous manual annotations. To this end, we propose a novel auxiliary learning strategy for camera localization by introducing scene-specific high-level semantics from self-supervised representation learning task. Viewed as a powerful proxy task, image colorization task is chosen as complementary task that outputs pixel-wise color version of grayscale photograph without extra annotations. In our work, feature representations from colorization network are embedded into localization network by design to produce discriminative features for pose regression. Meanwhile an attention mechanism is introduced for the benefit of localization performance. Extensive experiments show that our model significantly improve localization accuracy over state-of-the-arts on both indoor and outdoor datasets.