 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMP3: Multi-Period Pattern Pre-training for Spatio-Temporal Forecasting
Jun 12, 2026Spatio-Temporal forecasting is crucial in diverse fields, such as transportation, climate, and energy. Urban spatio-temporal data exhibits temporal mirage: similar short-window inputs have divergent future trends, and vice versa. Existing spatio-temporal graph neural networks (STGNNs) cannot effectively identify such mirages. We argue that the core reason lies in the short-window inputs that have incomplete period observation, heterogeneous global spatial correlation, and cross-period superposition causality. To bridge this gap, we develop a novel Multi- Period Pattern Pre-training (MP3), a plug-and-play pre-training plugin for distinguishing temporal mirages. MP3 presents two core innovations: (1) The multi-period pattern learning is designed to learn multi-period patterns from long time series. Specifically, multi-period temporal modeling leverages edge convolution to identify different multi-period patterns. Multi-period spatial modeling uses a bottleneck project and a global memory bank to capture heterogeneous global spatial relations efficiently. Cross-period pattern interaction employs a causality-enhanced Transformer to capture dependencies across different period patterns. (2) This plugin can seamlessly integrate into existing STGNN backbones to strengthen their forecasting performance. The experiment on five STGNN baselines across five real-world datasets (including a large-scale dataset CA) verify the effectiveness, superior scalability and strong adaptability of MP3, which brings consistent and robust performance improvements across all evaluated baselines. On average, MP3 reduces the MAE 4.7% and the RMSE 5.0%. The code can be available at https://github.com/YAN-outlook/MP3.
MP3: Multi-Period Pattern Pre-training forSpatio-Temporal Forecasting
Jun 11, 2026Spatio-Temporal forecasting is crucial in diverse fields, such as transportation, climate, and energy. Urban spatio-temporal data exhibits temporal mirage: similar short-window inputs have divergent future trends, and vice versa. Existing spatio-temporal graph neural networks (STGNNs) cannot effectively identify such mirages. We argue that the core reason lies in the short-window inputs that have incomplete period observation, heterogeneous global spatial correlation, and cross-period superposition causality. To bridge this gap, we develop a novel Multi- Period Pattern Pre-training (MP3), a plug-and-play pre-training plugin for distinguishing temporal mirages. MP3 presents two core innovations: (1) The multi-period pattern learning is designed to learn multi-period patterns from long time series. Specifically, multi-period temporal modeling leverages edge convolution to identify different multi-period patterns. Multi-period spatial modeling uses a bottleneck project and a global memory bank to capture heterogeneous global spatial relations efficiently. Cross-period pattern interaction employs a causality-enhanced Transformer to capture dependencies across different period patterns. (2) This plugin can seamlessly integrate into existing STGNN backbones to strengthen their forecasting performance. The experiment on five STGNN baselines across five real-world datasets (including a large-scale dataset CA) verify the effectiveness, superior scalability and strong adaptability of MP3, which brings consistent and robust performance improvements across all evaluated baselines. On average, MP3 reduces the MAE 4.7% and the RMSE 5.0%. The code can be available at https://github.com/YAN-outlook/MP3.
TimeSage-MT: A Multi-Turn Benchmark for Evaluating Agentic Time Series Reasoning
May 31, 2026Time series data inform critical decisions across many real-world domains. While large language model (LLM) agents can analyze data through natural language and tools, it remains unclear whether they can conduct reliable time series analysis across multi-turn conversations. Existing benchmarks focus on single-step tasks such as forecasting and anomaly detection, overlooking practical workflows where user goals evolve, agents must build on prior analyses, and conclusions emerge from accumulated evidence. In this work, we introduce TimeSage-MT, a multi-turn benchmark for agentic time series reasoning with 240 tasks and 2,680 dialogue turns across 8 real-world domains, spanning basic exploration to decision-oriented analysis. TimeSage-MT is built through a reproducible pipeline that converts real-world time series data into multi-turn conversations with verifiable answers. It provides a unified evaluation protocol and public leaderboard for comparing time series agentic systems. To demonstrate the benchmark's utility, we evaluate frontier LLMs alongside TimeSage, a novel structured agent equipped with a comprehensive time series skill library. The results show sharp performance drops on decision-oriented tasks, driven by failures in memory, uncertainty handling, and domain-based decision making. TimeSage-MT exposes critical gaps in current agentic reasoning and provides a rigorous foundation for future development.
EIDOS: Latent-Space Predictive Learning for Time Series Foundation Models
Feb 15, 2026Most time series foundation models are pretrained by directly predicting future observations, which often yields weakly structured latent representations that capture surface noise rather than coherent and predictable temporal dynamics. In this work, we introduce EIDOS, a foundation model family that shifts pretraining from future value prediction to latent-space predictive learning. We train a causal Transformer to predict the evolution of latent representations, encouraging the emergence of structured and temporally coherent latent states. To ensure stable targets for latent-space learning, we design a lightweight aggregation branch to construct target representations. EIDOS is optimized via a joint objective that integrates latent-space alignment, observational grounding to anchor representations to the input signal, and direct forecasting supervision. On the GIFT-Eval benchmark, EIDOS mitigates structural fragmentation in the representation space and achieves state-of-the-art performance. These results demonstrate that constraining models to learn predictable latent dynamics is a principled step toward more robust and reliable time series foundation models.
Towards Neural Scaling Laws for Time Series Foundation Models
Oct 16, 2024
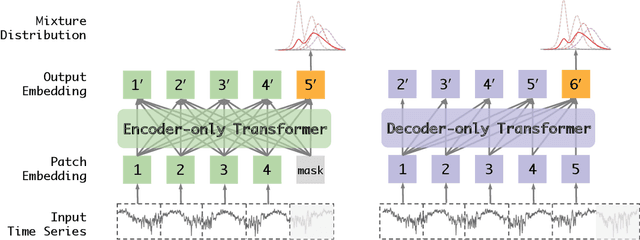
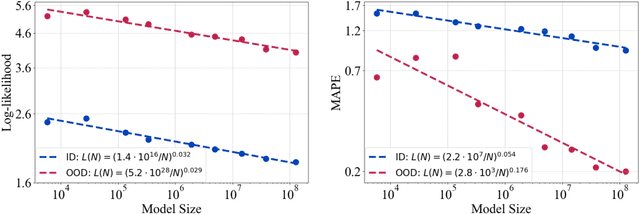

Scaling laws offer valuable insights into the design of time series foundation models (TSFMs). However, previous research has largely focused on the scaling laws of TSFMs for in-distribution (ID) data, leaving their out-of-distribution (OOD) scaling behavior and the influence of model architectures less explored. In this work, we examine two common TSFM architectures, encoder-only and decoder-only Transformers, and investigate their scaling behavior on both ID and OOD data. These models are trained and evaluated across varying parameter counts, compute budgets, and dataset sizes. Our experiments reveal that the log-likelihood loss of TSFMs exhibits similar scaling behavior in both OOD and ID settings. We further compare the scaling properties across different architectures, incorporating two state-of-the-art TSFMs as case studies, showing that model architecture plays a significant role in scaling. The encoder-only Transformers demonstrate better scalability than the decoder-only Transformers, while the architectural enhancements in the two advanced TSFMs primarily improve ID performance but reduce OOD scalability. While scaling up TSFMs is expected to drive performance breakthroughs, the lack of a comprehensive understanding of TSFM scaling laws has hindered the development of a robust framework to guide model scaling. We fill this gap in this work by synthesizing our findings and providing practical guidelines for designing and scaling larger TSFMs with enhanced model capabilities.
ES2Net: An Efficient Spectral-Spatial Network for Hyperspectral Image Change Detection
Jul 23, 2023Hyperspectral image change detection (HSI-CD) aims to identify the differences in bitemporal HSIs. To mitigate spectral redundancy and improve the discriminativeness of changing features, some methods introduced band selection technology to select bands conducive for CD. However, these methods are limited by the inability to end-to-end training with the deep learning-based feature extractor and lack considering the complex nonlinear relationship among bands. In this paper, we propose an end-to-end efficient spectral-spatial change detection network (ES2Net) to address these issues. Specifically, we devised a learnable band selection module to automatically select bands conducive to CD. It can be jointly optimized with a feature extraction network and capture the complex nonlinear relationships among bands. Moreover, considering the large spatial feature distribution differences among different bands, we design the cluster-wise spatial attention mechanism that assigns a spatial attention factor to each individual band to individually improve the feature discriminativeness for each band. Experiments on three widely used HSI-CD datasets demonstrate the effectiveness and superiority of this method compared with other state-of-the-art methods.