 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJPDS-NN: Reinforcement Learning-Based Dynamic Task Allocation for Agricultural Vehicle Routing Optimization
Mar 04, 2025
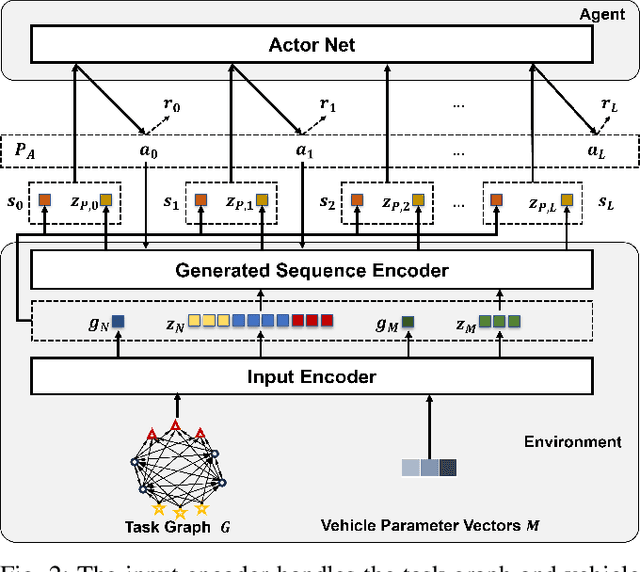


The Entrance Dependent Vehicle Routing Problem (EDVRP) is a variant of the Vehicle Routing Problem (VRP) where the scale of cities influences routing outcomes, necessitating consideration of their entrances. This paper addresses EDVRP in agriculture, focusing on multi-parameter vehicle planning for irregularly shaped fields. To address the limitations of traditional methods, such as heuristic approaches, which often overlook field geometry and entrance constraints, we propose a Joint Probability Distribution Sampling Neural Network (JPDS-NN) to effectively solve the EDVRP. The network uses an encoder-decoder architecture with graph transformers and attention mechanisms to model routing as a Markov Decision Process, and is trained via reinforcement learning for efficient and rapid end-to-end planning. Experimental results indicate that JPDS-NN reduces travel distances by 48.4-65.4%, lowers fuel consumption by 14.0-17.6%, and computes two orders of magnitude faster than baseline methods, while demonstrating 15-25% superior performance in dynamic arrangement scenarios. Ablation studies validate the necessity of cross-attention and pre-training. The framework enables scalable, intelligent routing for large-scale farming under dynamic constraints.
Ordered Genetic Algorithm for Entrance Dependent Vehicle Routing Problem in Farms
Feb 26, 2025Vehicle Routing Problems (VRP) are widely studied issues that play important roles in many production scenarios. We have noticed that in some practical scenarios of VRP, the size of cities and their entrances can significantly influence the optimization process. To address this, we have constructed the Entrance Dependent VRP (EDVRP) to describe such problems. We provide a mathematical formulation for the EDVRP in farms and propose an Ordered Genetic Algorithm (OGA) to solve it. The effectiveness of OGA is demonstrated through our experiments, which involve a multitude of randomly generated cases. The results indicate that OGA offers certain advantages compared to a random strategy baseline and a genetic algorithm without ordering. Furthermore, the novel operators introduced in this paper have been validated through ablation experiments, proving their effectiveness in enhancing the performance of the algorithm.
Efficient Exploration Using Extra Safety Budget in Constrained Policy Optimization
Feb 28, 2023Reinforcement learning (RL) has achieved promising results on most robotic control tasks. Safety of learning-based controllers is an essential notion of ensuring the effectiveness of the controllers. Current methods adopt whole consistency constraints during the training, thus resulting in inefficient exploration in the early stage. In this paper, we propose a Constrained Policy Optimization with Extra Safety Budget (ESB-CPO) algorithm to strike a balance between the exploration and the constraints. In the early stage, our method loosens the practical constraints of unsafe transitions (adding extra safety budget) with the aid of a new metric we propose. With the training process, the constraints in our optimization problem become tighter. Meanwhile, theoretical analysis and practical experiments demonstrate that our method gradually meets the cost limit's demand in the final training stage. When evaluated on Safety-Gym and Bullet-Safety-Gym benchmarks, our method has shown its advantages over baseline algorithms in terms of safety and optimality. Remarkably, our method gains remarkable performance improvement under the same cost limit compared with CPO algorithm.