 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTurning mechanistic models into forecasters by using machine learning
Feb 04, 2026The equations of complex dynamical systems may not be identified by expert knowledge, especially if the underlying mechanisms are unknown. Data-driven discovery methods address this challenge by inferring governing equations from time-series data using a library of functions constructed from the measured variables. However, these methods typically assume time-invariant coefficients, which limits their ability to capture evolving system dynamics. To overcome this limitation, we allow some of the parameters to vary over time, learn their temporal evolution directly from data, and infer a system of equations that incorporates both constant and time-varying parameters. We then transform this framework into a forecasting model by predicting the time-varying parameters and substituting these predictions into the learned equations. The model is validated using datasets for Susceptible-Infected-Recovered, Consumer--Resource, greenhouse gas concentration, and Cyanobacteria cell count. By dynamically adapting to temporal shifts, our proposed model achieved a mean absolute error below 3\% for learning a time series and below 6\% for forecasting up to a month ahead. We additionally compare forecasting performance against CNN-LSTM and Gradient Boosting Machine (GBM), and show that our model outperforms these methods across most datasets. Our findings demonstrate that integrating time-varying parameters into data-driven discovery of differential equations improves both modeling accuracy and forecasting performance.
Deep Learning for Disease Outbreak Prediction: A Robust Early Warning Signal for Transcritical Bifurcations
Jan 14, 2025



Early Warning Signals (EWSs) are vital for implementing preventive measures before a disease turns into a pandemic. While new diseases exhibit unique behaviors, they often share fundamental characteristics from a dynamical systems perspective. Moreover, measurements during disease outbreaks are often corrupted by different noise sources, posing challenges for Time Series Classification (TSC) tasks. In this study, we address the problem of having a robust EWS for disease outbreak prediction using a best-performing deep learning model in the domain of TSC. We employed two simulated datasets to train the model: one representing generated dynamical systems with randomly selected polynomial terms to model new disease behaviors, and another simulating noise-induced disease dynamics to account for noisy measurements. The model's performance was analyzed using both simulated data from different disease models and real-world data, including influenza and COVID-19. Results demonstrate that the proposed model outperforms previous models, effectively providing EWSs of impending outbreaks across various scenarios. This study bridges advancements in deep learning with the ability to provide robust early warning signals in noisy environments, making it highly applicable to real-world crises involving emerging disease outbreaks.
Website visits can predict angler presence using machine learning
Sep 25, 2024



Understanding and predicting recreational fishing activity is important for sustainable fisheries management. However, traditional methods of measuring fishing pressure, such as surveys, can be costly and limited in both time and spatial extent. Predictive models that relate fishing activity to environmental or economic factors typically rely on historical data, which often restricts their spatial applicability due to data scarcity. In this study, high-resolution angler-generated data from an online platform and easily accessible auxiliary data were tested to predict daily boat presence and aerial counts of boats at almost 200 lakes over five years in Ontario, Canada. Lake-information website visits alone enabled predicting daily angler boat presence with 78% accuracy. While incorporating additional environmental, socio-ecological, weather and angler-generated features into machine learning models did not remarkably improve prediction performance of boat presence, they were substantial for the prediction of boat counts. Models achieved an R2 of up to 0.77 at known lakes included in the model training, but they performed poorly for unknown lakes (R2 = 0.21). The results demonstrate the value of integrating angler-generated data from online platforms into predictive models and highlight the potential of machine learning models to enhance fisheries management.
An early warning indicator trained on stochastic disease-spreading models with different noises
Mar 24, 2024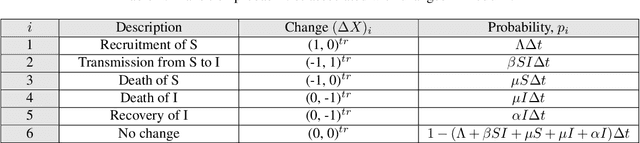
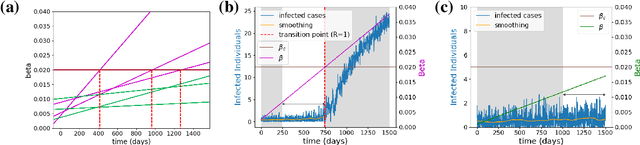
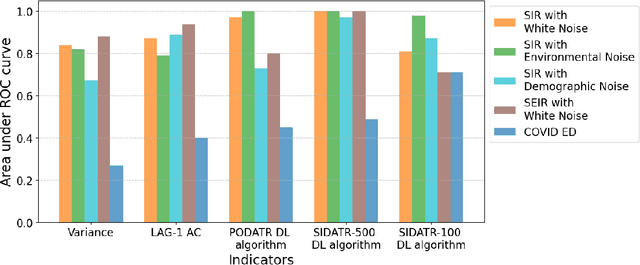
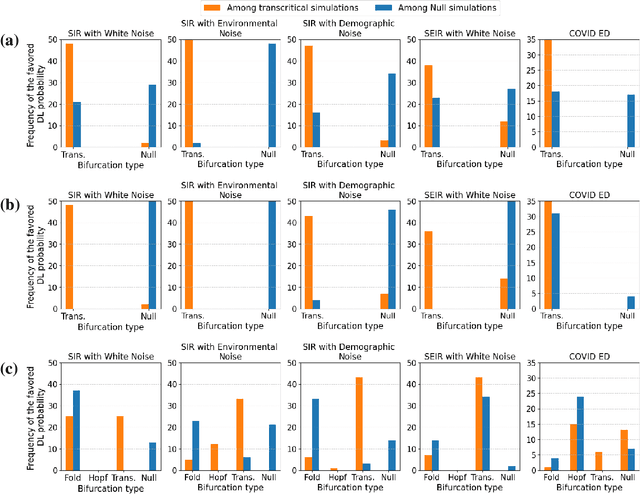
The timely detection of disease outbreaks through reliable early warning signals (EWSs) is indispensable for effective public health mitigation strategies. Nevertheless, the intricate dynamics of real-world disease spread, often influenced by diverse sources of noise and limited data in the early stages of outbreaks, pose a significant challenge in developing reliable EWSs, as the performance of existing indicators varies with extrinsic and intrinsic noises. Here, we address the challenge of modeling disease when the measurements are corrupted by additive white noise, multiplicative environmental noise, and demographic noise into a standard epidemic mathematical model. To navigate the complexities introduced by these noise sources, we employ a deep learning algorithm that provides EWS in infectious disease outbreak by training on noise-induced disease-spreading models. The indicator's effectiveness is demonstrated through its application to real-world COVID-19 cases in Edmonton and simulated time series derived from diverse disease spread models affected by noise. Notably, the indicator captures an impending transition in a time series of disease outbreaks and outperforms existing indicators. This study contributes to advancing early warning capabilities by addressing the intricate dynamics inherent in real-world disease spread, presenting a promising avenue for enhancing public health preparedness and response efforts.
Can machine learning predict citizen-reported angler behavior?
Feb 07, 2024Prediction of angler behaviors, such as catch rates and angler pressure, is essential to maintaining fish populations and ensuring angler satisfaction. Angler behavior can partly be tracked by online platforms and mobile phone applications that provide fishing activities reported by recreational anglers. Moreover, angler behavior is known to be driven by local site attributes. Here, the prediction of citizen-reported angler behavior was investigated by machine-learning methods using auxiliary data on the environment, socioeconomics, fisheries management objectives, and events at a freshwater body. The goal was to determine whether auxiliary data alone could predict the reported behavior. Different spatial and temporal extents and temporal resolutions were considered. Accuracy scores averaged 88% for monthly predictions at single water bodies and 86% for spatial predictions on a day in a specific region across Canada. At other resolutions and scales, the models only achieved low prediction accuracy of around 60%. The study represents a first attempt at predicting angler behavior in time and space at a large scale and establishes a foundation for potential future expansions in various directions.
Kindness in Multi-Agent Reinforcement Learning
Nov 06, 2023In human societies, people often incorporate fairness in their decisions and treat reciprocally by being kind to those who act kindly. They evaluate the kindness of others' actions not only by monitoring the outcomes but also by considering the intentions. This behavioral concept can be adapted to train cooperative agents in Multi-Agent Reinforcement Learning (MARL). We propose the KindMARL method, where agents' intentions are measured by counterfactual reasoning over the environmental impact of the actions that were available to the agents. More specifically, the current environment state is compared with the estimation of the current environment state provided that the agent had chosen another action. The difference between each agent's reward, as the outcome of its action, with that of its fellow, multiplied by the intention of the fellow is then taken as the fellow's "kindness". If the result of each reward-comparison confirms the agent's superiority, it perceives the fellow's kindness and reduces its own reward. Experimental results in the Cleanup and Harvest environments show that training based on the KindMARL method enabled the agents to earn 89\% (resp. 37\%) and 44% (resp. 43\%) more total rewards than training based on the Inequity Aversion and Social Influence methods. The effectiveness of KindMARL is further supported by experiments in a traffic light control problem.
Environmental-Impact Based Multi-Agent Reinforcement Learning
Nov 06, 2023To promote cooperation and strengthen the individual impact on the collective outcome in social dilemmas, we propose the Environmental-impact Multi-Agent Reinforcement Learning (EMuReL) method where each agent estimates the "environmental impact" of every other agent, that is, the difference in the current environment state compared to the hypothetical environment in the absence of that other agent. Inspired by the Inequity Aversion model, the agent then compares its own reward with those of its fellows multiplied by their environmental impacts. If its reward exceeds the scaled reward of one of its fellows, the agent takes "social responsibility" toward that fellow by reducing its own reward. Therefore, the less influential an agent is in reaching the current state, the more social responsibility is taken by other agents. Experiments in the Cleanup (resp. Harvest) test environment demonstrate that agents trained based on EMuReL learn to cooperate more effectively and obtain $54\%$ ($39\%$) and $20\%$ ($44\%$) more total rewards while preserving the same cooperation levels compared to when they are trained based on the two state-of-the-art reward reshaping methods inequity aversion and social influence.
Detecting individual-level infections using sparse group-testing through graph-coupled hidden Markov models
Jun 05, 2023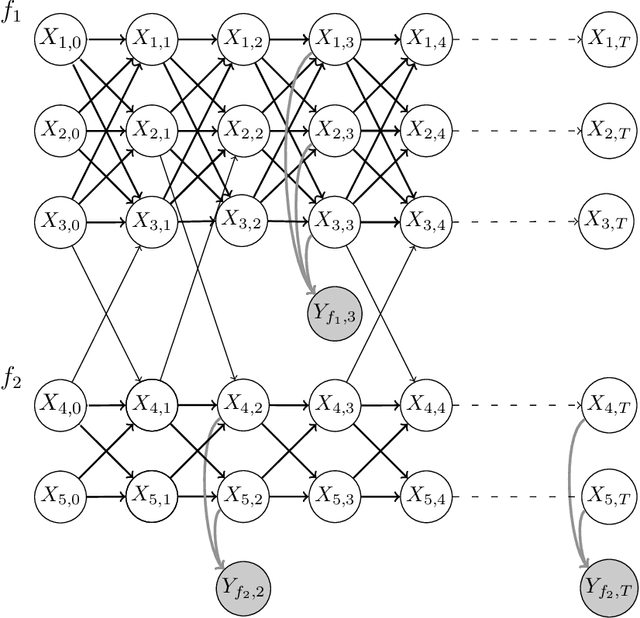

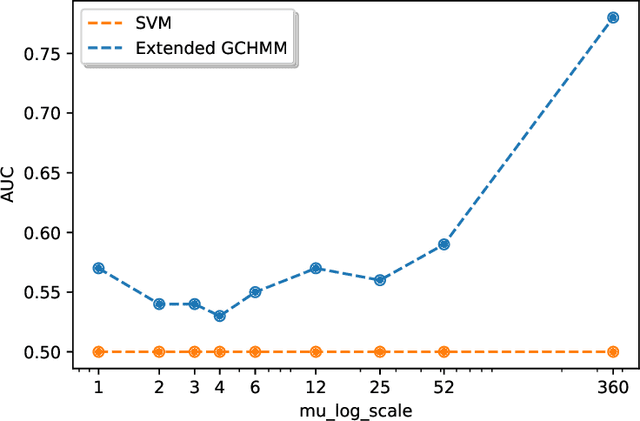
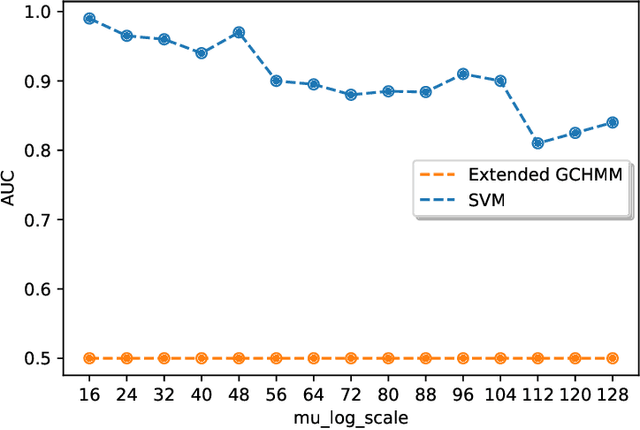
Identifying the infection status of each individual during infectious diseases informs public health management. However, performing frequent individual-level tests may not be feasible. Instead, sparse and sometimes group-level tests are performed. Determining the infection status of individuals using sparse group-level tests remains an open problem. We have tackled this problem by extending graph-coupled hidden Markov models with individuals infection statuses as the hidden states and the group test results as the observations. We fitted the model to simulation datasets using the Gibbs sampling method. The model performed about 0.55 AUC for low testing frequencies and increased to 0.80 AUC in the case where the groups were tested every day. The model was separately tested on a daily basis case to predict the statuses over time and after 15 days of the beginning of the spread, which resulted in 0.98 AUC at day 16 and remained above 0.80 AUC until day 128. Therefore, although dealing with sparse tests remains unsolved, the results open the possibility of using initial group screenings during pandemics to accurately estimate individuals infection statuses.
Modeling and Forecasting COVID-19 Cases using Latent Subpopulations
Feb 09, 2023Classical epidemiological models assume homogeneous populations. There have been important extensions to model heterogeneous populations, when the identity of the sub-populations is known, such as age group or geographical location. Here, we propose two new methods to model the number of people infected with COVID-19 over time, each as a linear combination of latent sub-populations -- i.e., when we do not know which person is in which sub-population, and the only available observations are the aggregates across all sub-populations. Method #1 is a dictionary-based approach, which begins with a large number of pre-defined sub-population models (each with its own starting time, shape, etc), then determines the (positive) weight of small (learned) number of sub-populations. Method #2 is a mixture-of-$M$ fittable curves, where $M$, the number of sub-populations to use, is given by the user. Both methods are compatible with any parametric model; here we demonstrate their use with first (a)~Gaussian curves and then (b)~SIR trajectories. We empirically show the performance of the proposed methods, first in (i) modeling the observed data and then in (ii) forecasting the number of infected people 1 to 4 weeks in advance. Across 187 countries, we show that the dictionary approach had the lowest mean absolute percentage error and also the lowest variance when compared with classical SIR models and moreover, it was a strong baseline that outperforms many of the models developed for COVID-19 forecasting.