 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDatasets: A Community Library for Natural Language Processing
Sep 07, 2021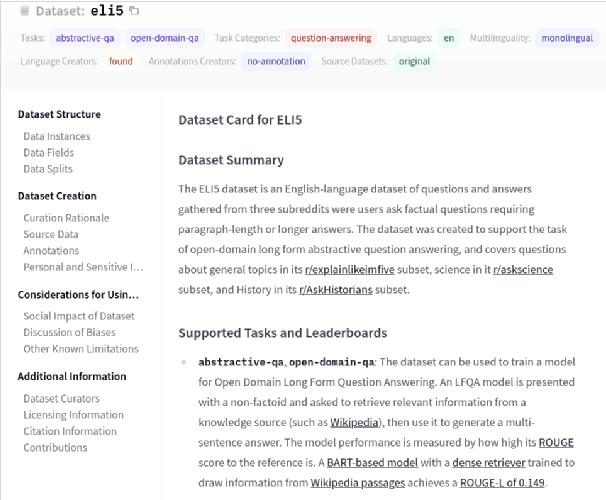
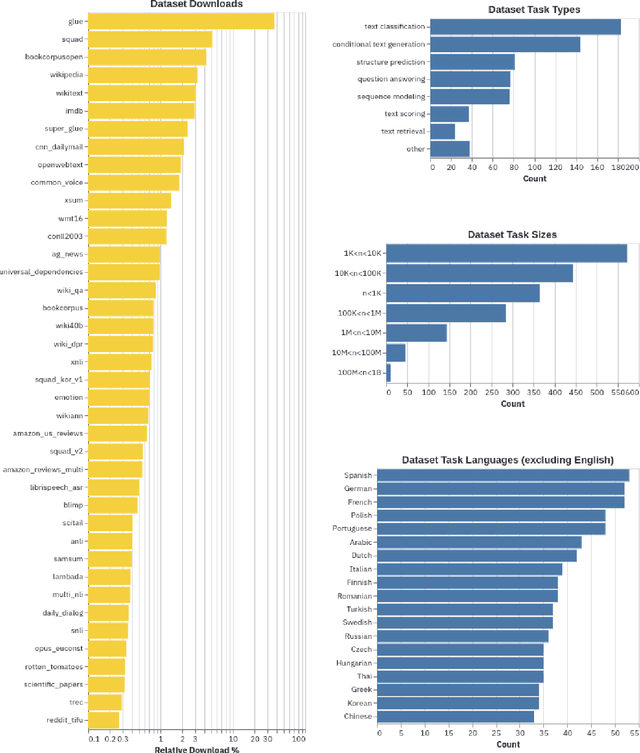
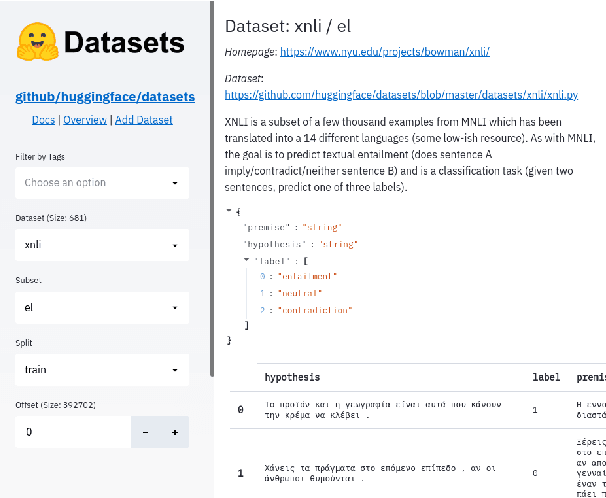
The scale, variety, and quantity of publicly-available NLP datasets has grown rapidly as researchers propose new tasks, larger models, and novel benchmarks. Datasets is a community library for contemporary NLP designed to support this ecosystem. Datasets aims to standardize end-user interfaces, versioning, and documentation, while providing a lightweight front-end that behaves similarly for small datasets as for internet-scale corpora. The design of the library incorporates a distributed, community-driven approach to adding datasets and documenting usage. After a year of development, the library now includes more than 650 unique datasets, has more than 250 contributors, and has helped support a variety of novel cross-dataset research projects and shared tasks. The library is available at https://github.com/huggingface/datasets.
HuggingFace's Transformers: State-of-the-art Natural Language Processing
Oct 16, 2019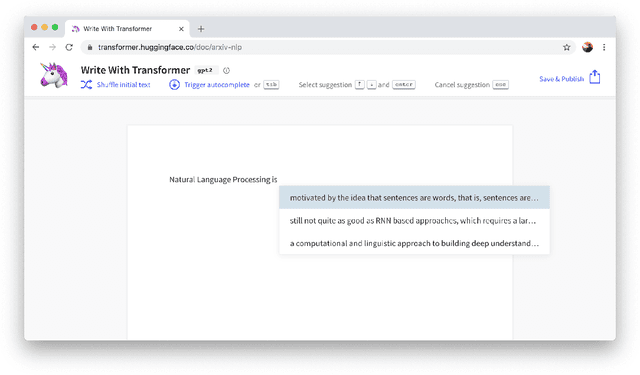
Recent advances in modern Natural Language Processing (NLP) research have been dominated by the combination of Transfer Learning methods with large-scale language models, in particular based on the Transformer architecture. With them came a paradigm shift in NLP with the starting point for training a model on a downstream task moving from a blank specific model to a general-purpose pretrained architecture. Still, creating these general-purpose models remains an expensive and time-consuming process restricting the use of these methods to a small sub-set of the wider NLP community. In this paper, we present HuggingFace's Transformers library, a library for state-of-the-art NLP, making these developments available to the community by gathering state-of-the-art general-purpose pretrained models under a unified API together with an ecosystem of libraries, examples, tutorials and scripts targeting many downstream NLP tasks. HuggingFace's Transformers library features carefully crafted model implementations and high-performance pretrained weights for two main deep learning frameworks, PyTorch and TensorFlow, while supporting all the necessary tools to analyze, evaluate and use these models in downstream tasks such as text/token classification, questions answering and language generation among others. The library has gained significant organic traction and adoption among both the researcher and practitioner communities. We are committed at HuggingFace to pursue the efforts to develop this toolkit with the ambition of creating the standard library for building NLP systems.