 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHuggingFace's Transformers: State-of-the-art Natural Language Processing
Oct 16, 2019
Recent advances in modern Natural Language Processing (NLP) research have been dominated by the combination of Transfer Learning methods with large-scale language models, in particular based on the Transformer architecture. With them came a paradigm shift in NLP with the starting point for training a model on a downstream task moving from a blank specific model to a general-purpose pretrained architecture. Still, creating these general-purpose models remains an expensive and time-consuming process restricting the use of these methods to a small sub-set of the wider NLP community. In this paper, we present HuggingFace's Transformers library, a library for state-of-the-art NLP, making these developments available to the community by gathering state-of-the-art general-purpose pretrained models under a unified API together with an ecosystem of libraries, examples, tutorials and scripts targeting many downstream NLP tasks. HuggingFace's Transformers library features carefully crafted model implementations and high-performance pretrained weights for two main deep learning frameworks, PyTorch and TensorFlow, while supporting all the necessary tools to analyze, evaluate and use these models in downstream tasks such as text/token classification, questions answering and language generation among others. The library has gained significant organic traction and adoption among both the researcher and practitioner communities. We are committed at HuggingFace to pursue the efforts to develop this toolkit with the ambition of creating the standard library for building NLP systems.
TransferTransfo: A Transfer Learning Approach for Neural Network Based Conversational Agents
Feb 04, 2019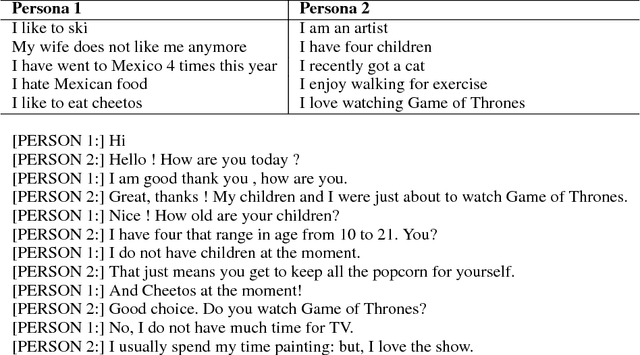

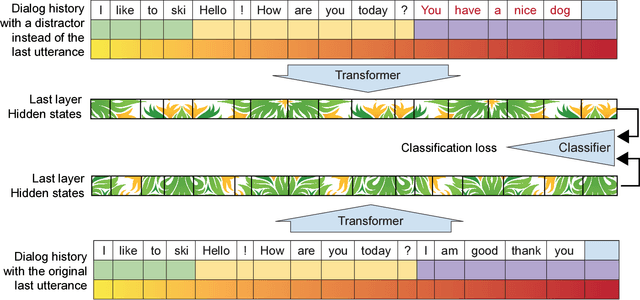
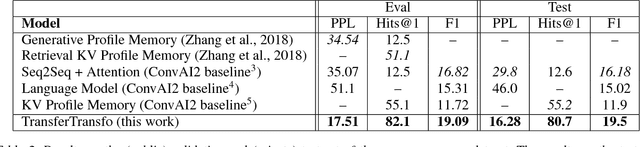
We introduce a new approach to generative data-driven dialogue systems (e.g. chatbots) called TransferTransfo which is a combination of a Transfer learning based training scheme and a high-capacity Transformer model. Fine-tuning is performed by using a multi-task objective which combines several unsupervised prediction tasks. The resulting fine-tuned model shows strong improvements over the current state-of-the-art end-to-end conversational models like memory augmented seq2seq and information-retrieval models. On the privately held PERSONA-CHAT dataset of the Conversational Intelligence Challenge 2, this approach obtains a new state-of-the-art, with respective perplexity, Hits@1 and F1 metrics of 16.28 (45 % absolute improvement), 80.7 (46 % absolute improvement) and 19.5 (20 % absolute improvement).
Continuous Learning in a Hierarchical Multiscale Neural Network
May 15, 2018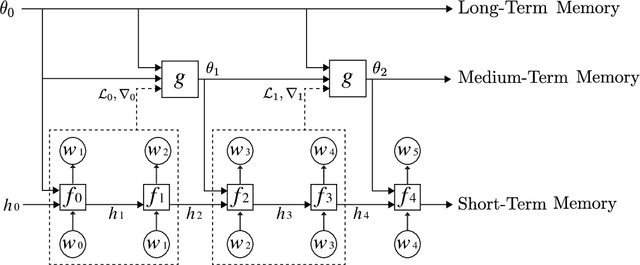
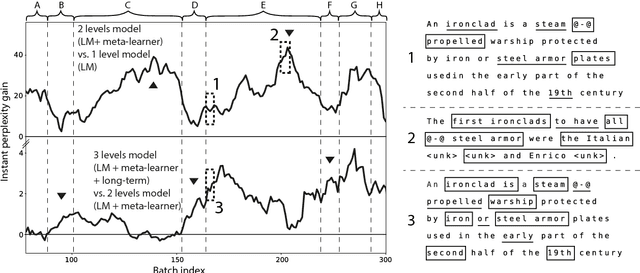
We reformulate the problem of encoding a multi-scale representation of a sequence in a language model by casting it in a continuous learning framework. We propose a hierarchical multi-scale language model in which short time-scale dependencies are encoded in the hidden state of a lower-level recurrent neural network while longer time-scale dependencies are encoded in the dynamic of the lower-level network by having a meta-learner update the weights of the lower-level neural network in an online meta-learning fashion. We use elastic weights consolidation as a higher-level to prevent catastrophic forgetting in our continuous learning framework.
Meta-Learning a Dynamical Language Model
Mar 28, 2018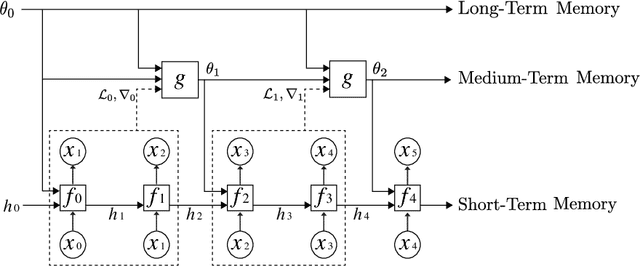
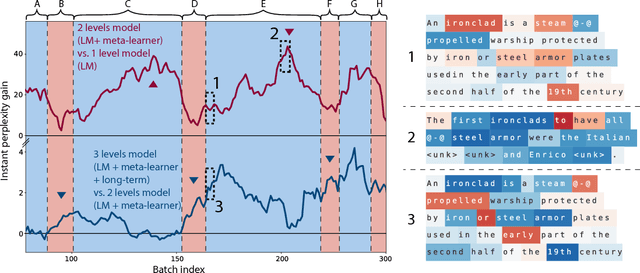
We consider the task of word-level language modeling and study the possibility of combining hidden-states-based short-term representations with medium-term representations encoded in dynamical weights of a language model. Our work extends recent experiments on language models with dynamically evolving weights by casting the language modeling problem into an online learning-to-learn framework in which a meta-learner is trained by gradient-descent to continuously update a language model weights.