 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutoEval Done Right: Using Synthetic Data for Model Evaluation
Mar 09, 2024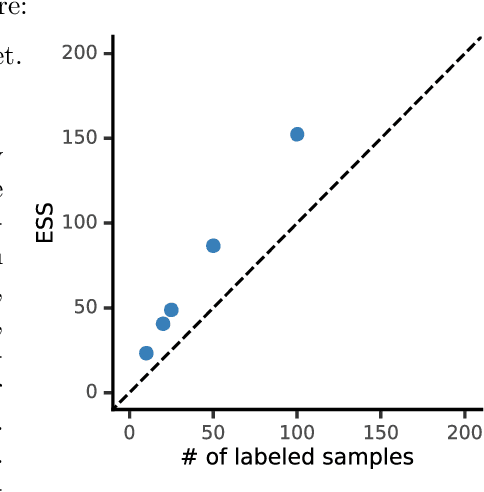
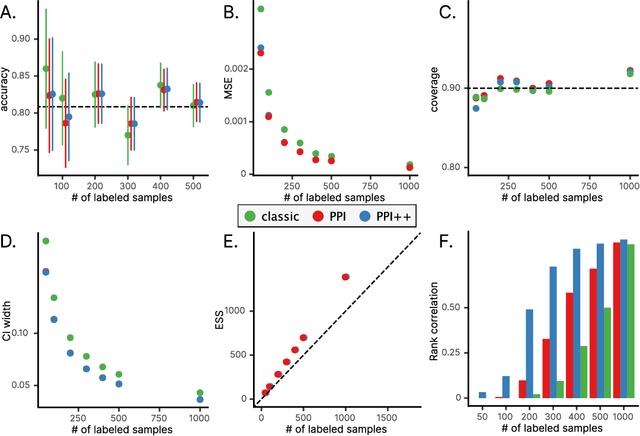
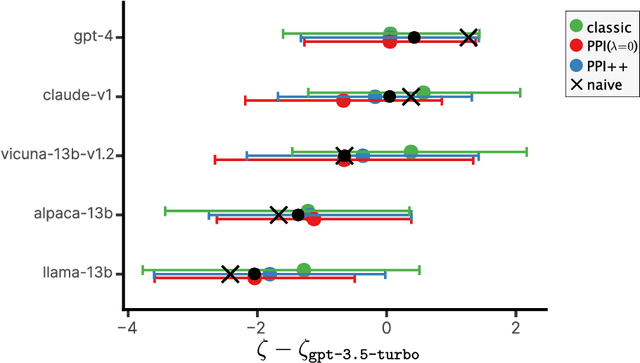
The evaluation of machine learning models using human-labeled validation data can be expensive and time-consuming. AI-labeled synthetic data can be used to decrease the number of human annotations required for this purpose in a process called autoevaluation. We suggest efficient and statistically principled algorithms for this purpose that improve sample efficiency while remaining unbiased. These algorithms increase the effective human-labeled sample size by up to 50% on experiments with GPT-4.
Decision-Making with Auto-Encoding Variational Bayes
Feb 17, 2020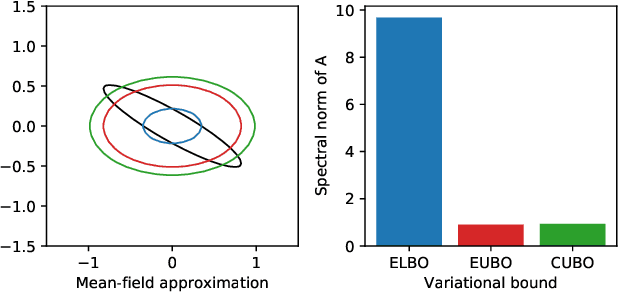

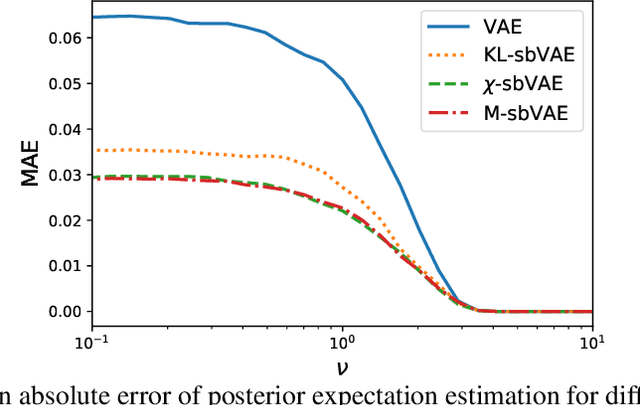

To make decisions based on a model fit by Auto-Encoding Variational Bayes (AEVB), practitioners typically use importance sampling to estimate a functional of the posterior distribution. The variational distribution found by AEVB serves as the proposal distribution for importance sampling. However, this proposal distribution may give unreliable (high variance) importance sampling estimates, thus leading to poor decisions. We explore how changing the objective function for learning the variational distribution, while continuing to learn the generative model based on the ELBO, affects the quality of downstream decisions. For a particular model, we characterize the error of importance sampling as a function of posterior variance and show that proposal distributions learned with evidence upper bounds are better. Motivated by these theoretical results, we propose a novel variant of the VAE. In addition to experimenting with MNIST, we present a full-fledged application of the proposed method to single-cell RNA sequencing. In this challenging instance of multiple hypothesis testing, the proposed method surpasses the current state of the art.