 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-site modelling and reconstruction of past extreme skew surges along the French Atlantic coast
May 01, 2025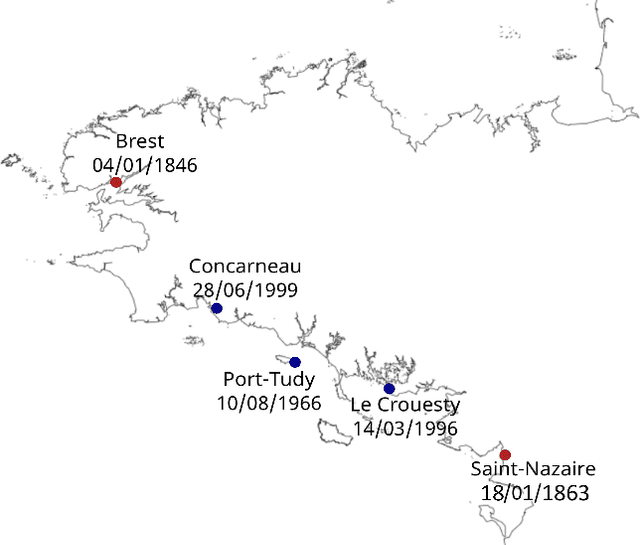
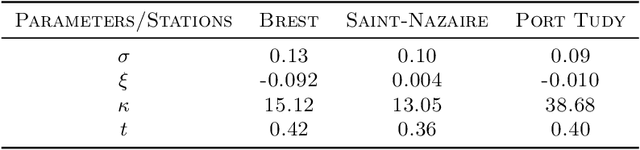
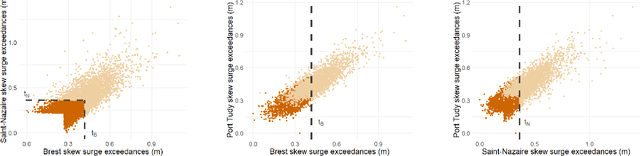
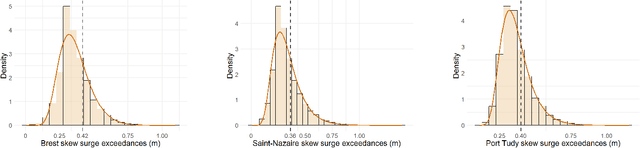
Appropriate modelling of extreme skew surges is crucial, particularly for coastal risk management. Our study focuses on modelling extreme skew surges along the French Atlantic coast, with a particular emphasis on investigating the extremal dependence structure between stations. We employ the peak-over-threshold framework, where a multivariate extreme event is defined whenever at least one location records a large value, though not necessarily all stations simultaneously. A novel method for determining an appropriate level (threshold) above which observations can be classified as extreme is proposed. Two complementary approaches are explored. First, the multivariate generalized Pareto distribution is employed to model extremes, leveraging its properties to derive a generative model that predicts extreme skew surges at one station based on observed extremes at nearby stations. Second, a novel extreme regression framework is assessed for point predictions. This specific regression framework enables accurate point predictions using only the "angle" of input variables, i.e. input variables divided by their norms. The ultimate objective is to reconstruct historical skew surge time series at stations with limited data. This is achieved by integrating extreme skew surge data from stations with longer records, such as Brest and Saint-Nazaire, which provide over 150 years of observations.
Distributional Regression U-Nets for the Postprocessing of Precipitation Ensemble Forecasts
Jul 02, 2024
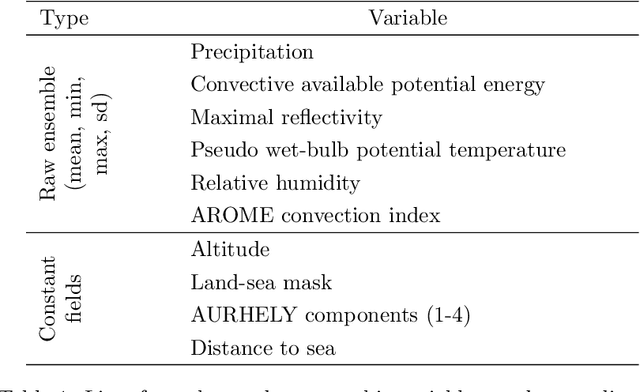
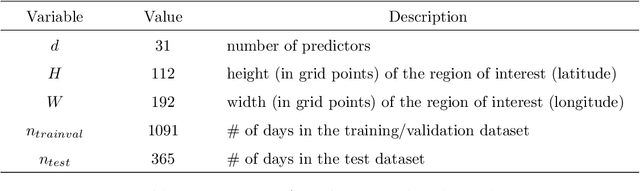

Accurate precipitation forecasts have a high socio-economic value due to their role in decision-making in various fields such as transport networks and farming. We propose a global statistical postprocessing method for grid-based precipitation ensemble forecasts. This U-Net-based distributional regression method predicts marginal distributions in the form of parametric distributions inferred by scoring rule minimization. Distributional regression U-Nets are compared to state-of-the-art postprocessing methods for daily 21-h forecasts of 3-h accumulated precipitation over the South of France. Training data comes from the M\'et\'eo-France weather model AROME-EPS and spans 3 years. A practical challenge appears when consistent data or reforecasts are not available. Distributional regression U-Nets compete favorably with the raw ensemble. In terms of continuous ranked probability score, they reach a performance comparable to quantile regression forests (QRF). However, they are unable to provide calibrated forecasts in areas associated with high climatological precipitation. In terms of predictive power for heavy precipitation events, they outperform both QRF and semi-parametric QRF with tail extensions.
A VAE Approach to Sample Multivariate Extremes
Jun 19, 2023

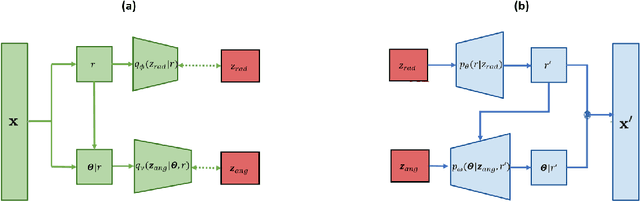

Generating accurate extremes from an observational data set is crucial when seeking to estimate risks associated with the occurrence of future extremes which could be larger than those already observed. Applications range from the occurrence of natural disasters to financial crashes. Generative approaches from the machine learning community do not apply to extreme samples without careful adaptation. Besides, asymptotic results from extreme value theory (EVT) give a theoretical framework to model multivariate extreme events, especially through the notion of multivariate regular variation. Bridging these two fields, this paper details a variational autoencoder (VAE) approach for sampling multivariate heavy-tailed distributions, i.e., distributions likely to have extremes of particularly large intensities. We illustrate the relevance of our approach on a synthetic data set and on a real data set of discharge measurements along the Danube river network. The latter shows the potential of our approach for flood risks' assessment. In addition to outperforming the standard VAE for the tested data sets, we also provide a comparison with a competing EVT-based generative approach. On the tested cases, our approach improves the learning of the dependency structure between extremes.
Mathematical Properties of Continuous Ranked Probability Score Forecasting
May 09, 2022The theoretical advances on the properties of scoring rules over the past decades have broaden the use of scoring rules in probabilistic forecasting. In meteorological forecasting, statistical postprocessing techniques are essential to improve the forecasts made by deterministic physical models. Numerous state-of-the-art statistical postprocessing techniques are based on distributional regression evaluated with the Continuous Ranked Probability Score (CRPS). However, theoretical properties of such minimization of the CRPS have mostly considered the unconditional framework (i.e. without covariables) and infinite sample sizes. We circumvent these limitations and study the rate of convergence in terms of CRPS of distributional regression methods We find the optimal minimax rate of convergence for a given class of distributions. Moreover, we show that the k-nearest neighbor method and the kernel method for the distributional regression reach the optimal rate of convergence in dimension $d\geq2$ and in any dimension, respectively.
Probability distributions for analog-to-target distances
Jan 26, 2021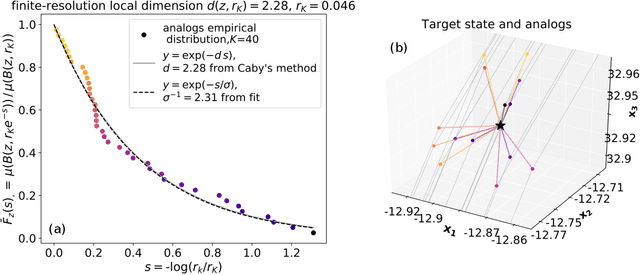
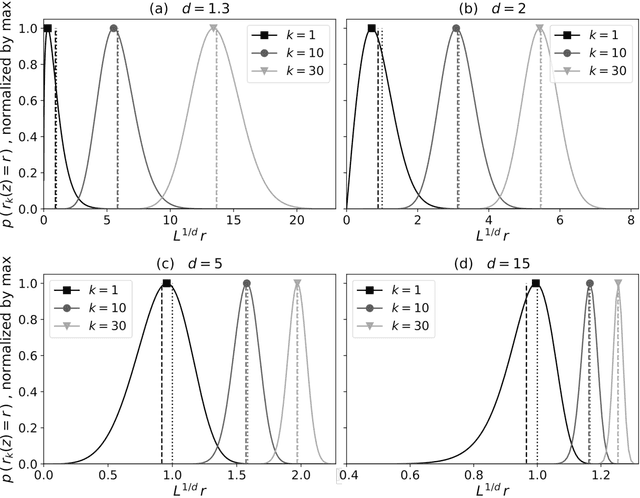
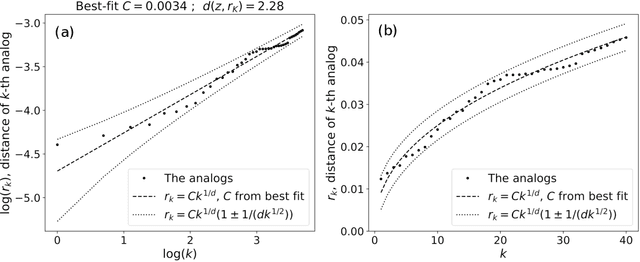
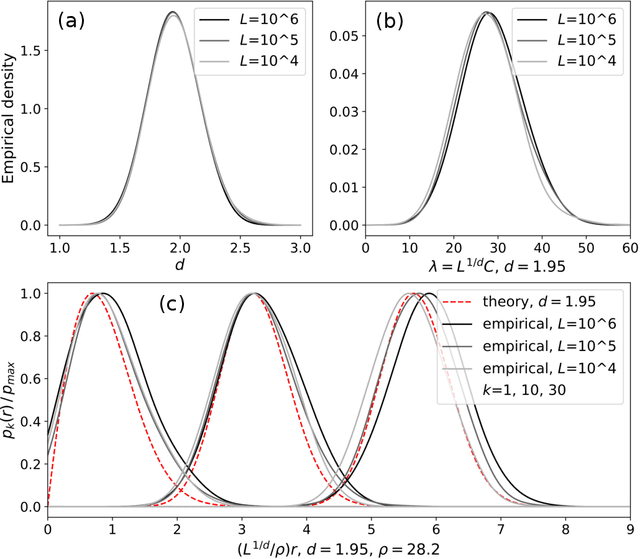
Some properties of chaotic dynamical systems can be probed through features of recurrences, also called analogs. In practice, analogs are nearest neighbours of the state of a system, taken from a large database called the catalog. Analogs have been used in many atmospheric applications including forecasts, downscaling, predictability estimation, and attribution of extreme events. The distances of the analogs to the target state condition the performances of analog applications. These distances can be viewed as random variables, and their probability distributions can be related to the catalog size and properties of the system at stake. A few studies have focused on the first moments of return time statistics for the best analog, fixing an objective of maximum distance from this analog to the target state. However, for practical use and to reduce estimation variance, applications usually require not just one, but many analogs. In this paper, we evaluate from a theoretical standpoint and with numerical experiments the probability distributions of the $K$-best analog-to-target distances. We show that dimensionality plays a role on the size of the catalog needed to find good analogs, and also on the relative means and variances of the $K$-best analogs. Our results are based on recently developed tools from dynamical systems theory. These findings are illustrated with numerical simulations of a well-known chaotic dynamical system and on 10m-wind reanalysis data in north-west France. A practical application of our derivations for the purpose of objective-based dimension reduction is shown using the same reanalysis data.
Extreme events evaluation using CRPS distributions
May 10, 2019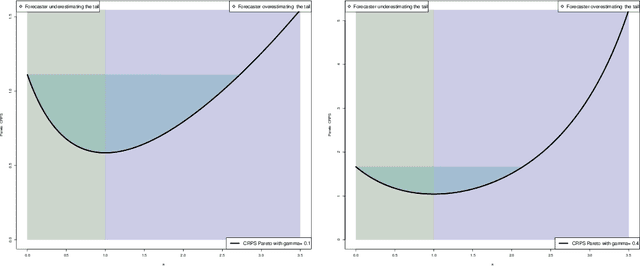
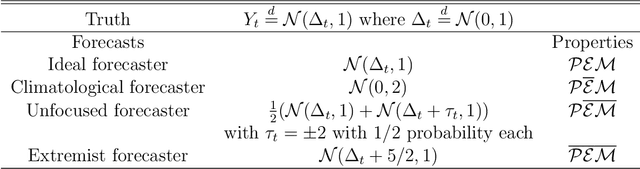
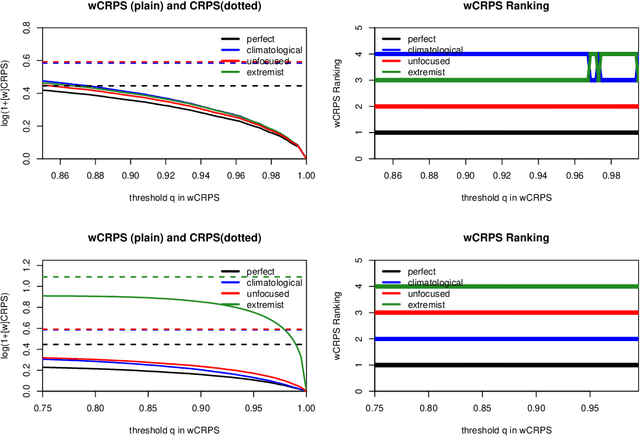
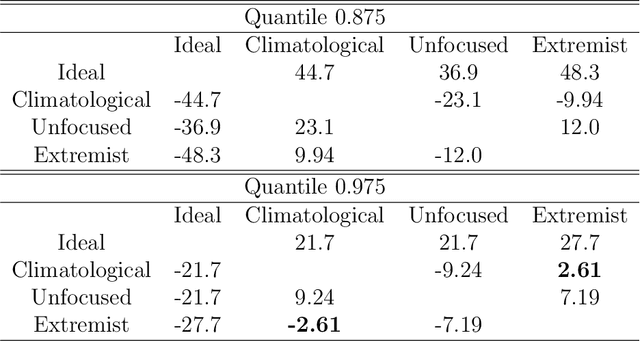
Verification of ensemble forecasts for extreme events remains a challenging question. The general public as well as the media naturely pay particular attention on extreme events and conclude about the global predictive performance of ensembles, which are often unskillful when they are needed. Ashing classical verification tools to focus on such events can lead to unexpected behaviors. To square up these effects, thresholded and weighted scoring rules have been developed. Most of them use derivations of the Continuous Ranked Probability Score (CRPS). However, some properties of the CRPS for extreme events generate undesirable effects on the quality of verification. Using theoretical arguments and simulation examples, we illustrate some pitfalls of conventional verification tools and propose a different direction to assess ensemble forecasts using extreme value theory, considering proper scores as random variables.
Forest-based methods and ensemble model output statistics for rainfall ensemble forecasting
Nov 29, 2017


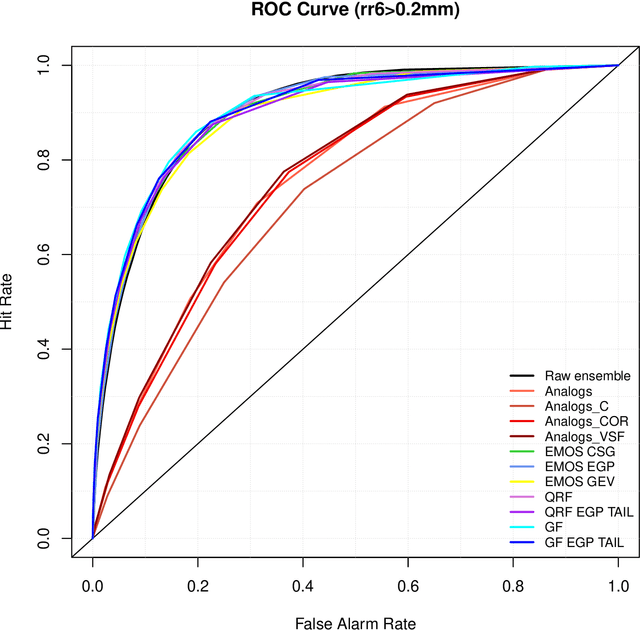
Rainfall ensemble forecasts have to be skillful for both low precipitation and extreme events. We present statistical post-processing methods based on Quantile Regression Forests (QRF) and Gradient Forests (GF) with a parametric extension for heavy-tailed distributions. Our goal is to improve ensemble quality for all types of precipitation events, heavy-tailed included, subject to a good overall performance. Our hybrid proposed methods are applied to daily 51-h forecasts of 6-h accumulated precipitation from 2012 to 2015 over France using the M{\'e}t{\'e}o-France ensemble prediction system called PEARP. They provide calibrated pre-dictive distributions and compete favourably with state-of-the-art methods like Analogs method or Ensemble Model Output Statistics. In particular, hybrid forest-based procedures appear to bring an added value to the forecast of heavy rainfall.