 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConvergence bounds for nonlinear least squares for tensor recovery
Aug 23, 2022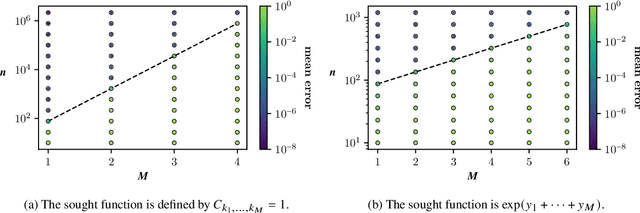
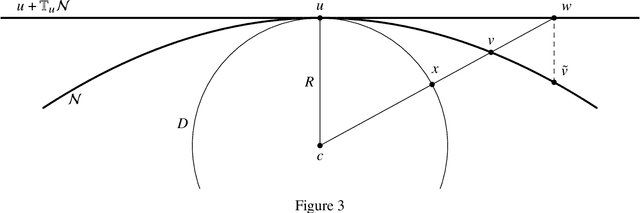

We consider the problem of approximating a function in general nonlinear subsets of L2 when only a weighted Monte Carlo estimate of the L2-norm can be computed. Of particular interest in this setting is the concept of sample complexity, the number of sample points that are necessary to achieve a prescribed error with high probability. Reasonable worst-case bounds for this quantity exist only for particular subsets of L2, like linear spaces or sets of sparse vectors. For more general subsets, like tensor networks, the currently existing bounds are very pessimistic. By restricting the model class to a neighbourhood of the best approximation, we can derive improved worst-case bounds for the sample complexity. When the considered neighbourhood is a manifold with positive local reach, the sample complexity can be estimated by the sample complexity of the tangent space and the product of the sample complexity of the normal space and the manifold's curvature.
Convergence bounds for nonlinear least squares and applications to tensor recovery
Aug 11, 2021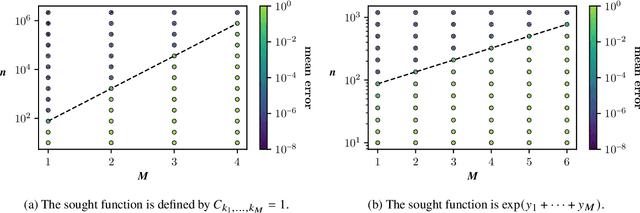

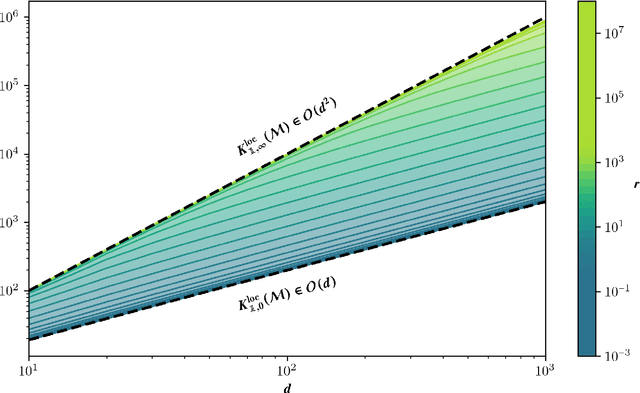

We consider the problem of approximating a function in general nonlinear subsets of $L^2$ when only a weighted Monte Carlo estimate of the $L^2$-norm can be computed. Of particular interest in this setting is the concept of sample complexity, the number of samples that are necessary to recover the best approximation. Bounds for this quantity have been derived in a previous work and depend primarily on the model class and are not influenced positively by the regularity of the sought function. This result however is only a worst-case bound and is not able to explain the remarkable performance of iterative hard thresholding algorithms that is observed in practice. We reexamine the results of the previous paper and derive a new bound that is able to utilize the regularity of the sought function. A critical analysis of our results allows us to derive a sample efficient algorithm for the model set of low-rank tensors. The viability of this algorithm is demonstrated by recovering quantities of interest for a classical high-dimensional random partial differential equation.
A block-sparse Tensor Train Format for sample-efficient high-dimensional Polynomial Regression
Apr 29, 2021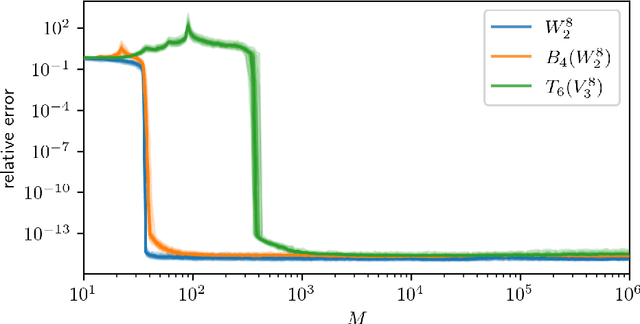
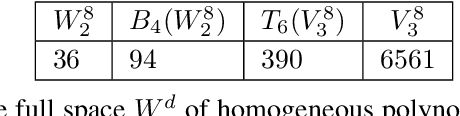
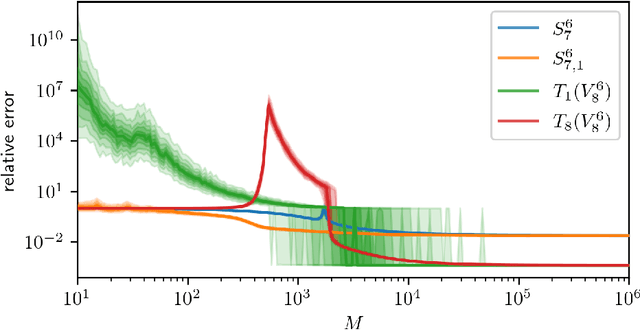
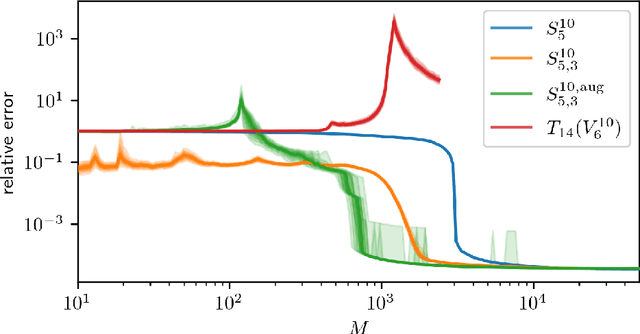
Low-rank tensors are an established framework for high-dimensional least-squares problems. We propose to extend this framework by including the concept of block-sparsity. In the context of polynomial regression each sparsity pattern corresponds to some subspace of homogeneous multivariate polynomials. This allows us to adapt the ansatz space to align better with known sample complexity results. The resulting method is tested in numerical experiments and demonstrates improved computational resource utilization and sample efficiency.
The Oracle of DLphi
Jan 27, 2019We present a novel technique based on deep learning and set theory which yields exceptional classification and prediction results. Having access to a sufficiently large amount of labelled training data, our methodology is capable of predicting the labels of the test data almost always even if the training data is entirely unrelated to the test data. In other words, we prove in a specific setting that as long as one has access to enough data points, the quality of the data is irrelevant.