 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe layer-wise L1 Loss Landscape of Neural Nets is more complex around local minima
May 06, 2021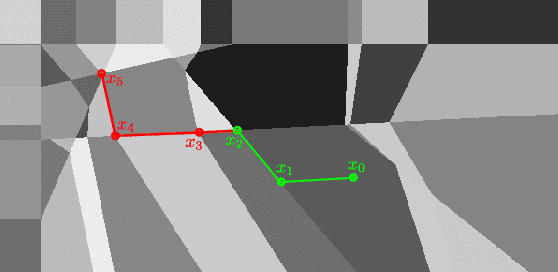

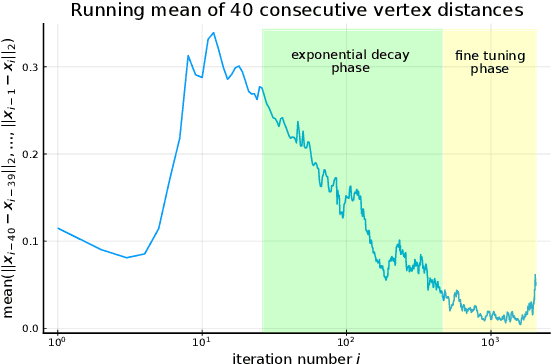
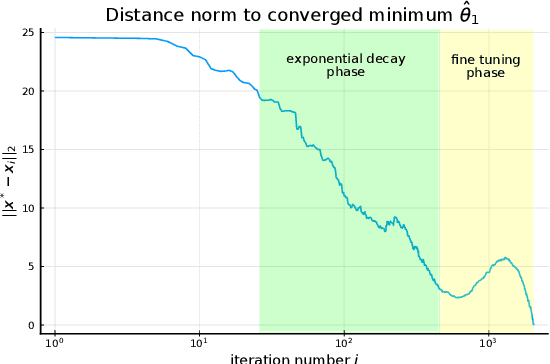
For fixed training data and network parameters in the other layers the L1 loss of a ReLU neural network as a function of the first layer's parameters is a piece-wise affine function. We use the Deep ReLU Simplex algorithm to iteratively minimize the loss monotonically on adjacent vertices and analyze the trajectory of these vertex positions. We empirically observe that in a neighbourhood around a local minimum, the iterations behave differently such that conclusions on loss level and proximity of the local minimum can be made before it has been found: Firstly the loss seems to decay exponentially slow at iterated adjacent vertices such that the loss level at the local minimum can be estimated from the loss levels of subsequently iterated vertices, and secondly we observe a strong increase of the vertex density around local minima. This could have far-reaching consequences for the design of new gradient-descent algorithms that might improve convergence rate by exploiting these facts.
Using activation histograms to bound the number of affine regions in ReLU feed-forward neural networks
Apr 08, 2021


Several current bounds on the maximal number of affine regions of a ReLU feed-forward neural network are special cases of the framework [1] which relies on layer-wise activation histogram bounds. We analyze and partially solve a problem in algebraic topology the solution of which would fully exploit this framework. Our partial solution already induces slightly tighter bounds and suggests insight in how parameter initialization methods can affect the number of regions. Furthermore, we extend the framework to allow the composition of subnetwork instead of layer-wise activation histogram bounds to reduce the number of required compositions which negatively affect the tightness of the resulting bound.
The Oracle of DLphi
Jan 27, 2019We present a novel technique based on deep learning and set theory which yields exceptional classification and prediction results. Having access to a sufficiently large amount of labelled training data, our methodology is capable of predicting the labels of the test data almost always even if the training data is entirely unrelated to the test data. In other words, we prove in a specific setting that as long as one has access to enough data points, the quality of the data is irrelevant.
A Framework for the construction of upper bounds on the number of affine linear regions of ReLU feed-forward neural networks
Aug 03, 2018
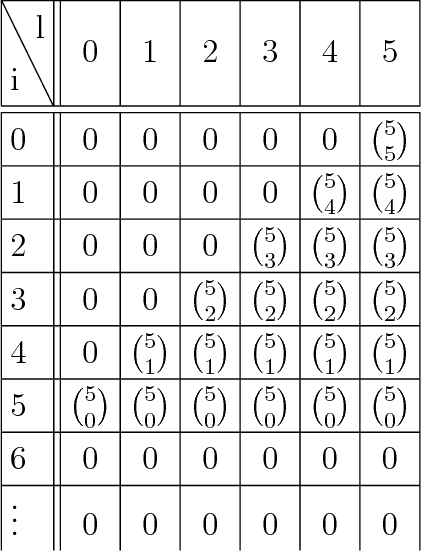
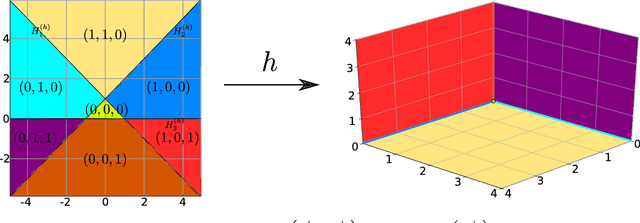

In this work we present a new framework to derive upper bounds on the number regions of feed-forward neural nets with ReLU activation functions. We derive all existing such bounds as special cases, however in a different representation in terms of matrices. This provides new insight and allows a more detailed analysis of the corresponding bounds. In particular, we provide a Jordan-like decomposition for the involved matrices and present new tighter results for an asymptotic setting. Moreover, new even stronger bounds may be obtained from our framework.