 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe layer-wise L1 Loss Landscape of Neural Nets is more complex around local minima
Paper and Code
May 06, 2021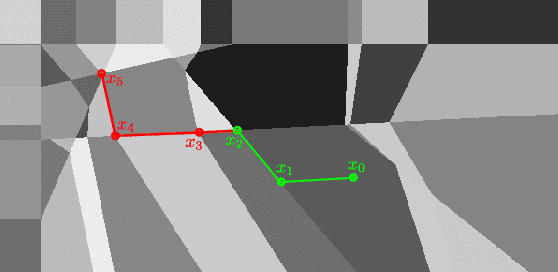

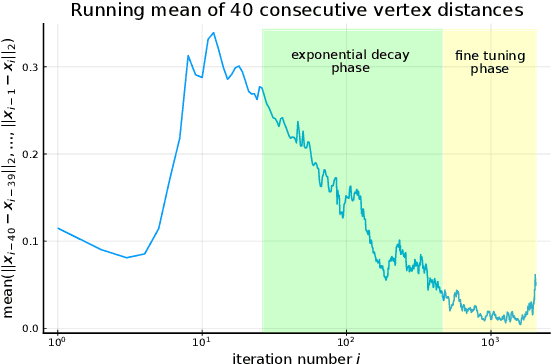
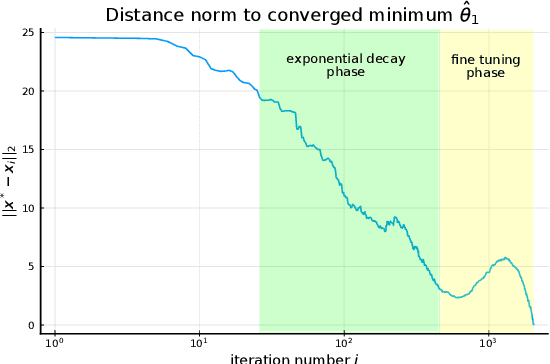
For fixed training data and network parameters in the other layers the L1 loss of a ReLU neural network as a function of the first layer's parameters is a piece-wise affine function. We use the Deep ReLU Simplex algorithm to iteratively minimize the loss monotonically on adjacent vertices and analyze the trajectory of these vertex positions. We empirically observe that in a neighbourhood around a local minimum, the iterations behave differently such that conclusions on loss level and proximity of the local minimum can be made before it has been found: Firstly the loss seems to decay exponentially slow at iterated adjacent vertices such that the loss level at the local minimum can be estimated from the loss levels of subsequently iterated vertices, and secondly we observe a strong increase of the vertex density around local minima. This could have far-reaching consequences for the design of new gradient-descent algorithms that might improve convergence rate by exploiting these facts.