 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStatistical Inference in Classification of High-dimensional Gaussian Mixture
Oct 25, 2024We consider the classification problem of a high-dimensional mixture of two Gaussians with general covariance matrices. Using the replica method from statistical physics, we investigate the asymptotic behavior of a general class of regularized convex classifiers in the high-dimensional limit, where both the sample size $n$ and the dimension $p$ approach infinity while their ratio $\alpha=n/p$ remains fixed. Our focus is on the generalization error and variable selection properties of the estimators. Specifically, based on the distributional limit of the classifier, we construct a de-biased estimator to perform variable selection through an appropriate hypothesis testing procedure. Using $L_1$-regularized logistic regression as an example, we conducted extensive computational experiments to confirm that our analytical findings are consistent with numerical simulations in finite-sized systems. We also explore the influence of the covariance structure on the performance of the de-biased estimator.
Differentiable Genetic Programming for High-dimensional Symbolic Regression
Apr 18, 2023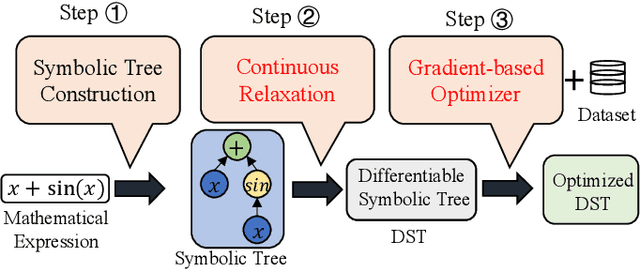



Symbolic regression (SR) is the process of discovering hidden relationships from data with mathematical expressions, which is considered an effective way to reach interpretable machine learning (ML). Genetic programming (GP) has been the dominator in solving SR problems. However, as the scale of SR problems increases, GP often poorly demonstrates and cannot effectively address the real-world high-dimensional problems. This limitation is mainly caused by the stochastic evolutionary nature of traditional GP in constructing the trees. In this paper, we propose a differentiable approach named DGP to construct GP trees towards high-dimensional SR for the first time. Specifically, a new data structure called differentiable symbolic tree is proposed to relax the discrete structure to be continuous, thus a gradient-based optimizer can be presented for the efficient optimization. In addition, a sampling method is proposed to eliminate the discrepancy caused by the above relaxation for valid symbolic expressions. Furthermore, a diversification mechanism is introduced to promote the optimizer escaping from local optima for globally better solutions. With these designs, the proposed DGP method can efficiently search for the GP trees with higher performance, thus being capable of dealing with high-dimensional SR. To demonstrate the effectiveness of DGP, we conducted various experiments against the state of the arts based on both GP and deep neural networks. The experiment results reveal that DGP can outperform these chosen peer competitors on high-dimensional regression benchmarks with dimensions varying from tens to thousands. In addition, on the synthetic SR problems, the proposed DGP method can also achieve the best recovery rate even with different noisy levels. It is believed this work can facilitate SR being a powerful alternative to interpretable ML for a broader range of real-world problems.
Contrastive Learning with Temporal Correlated Medical Images: A Case Study using Lung Segmentation in Chest X-Rays
Sep 16, 2021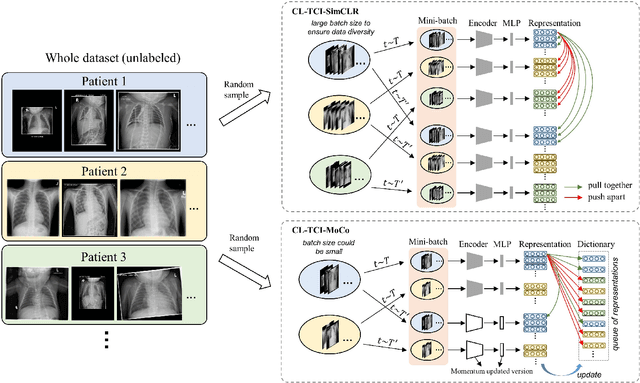
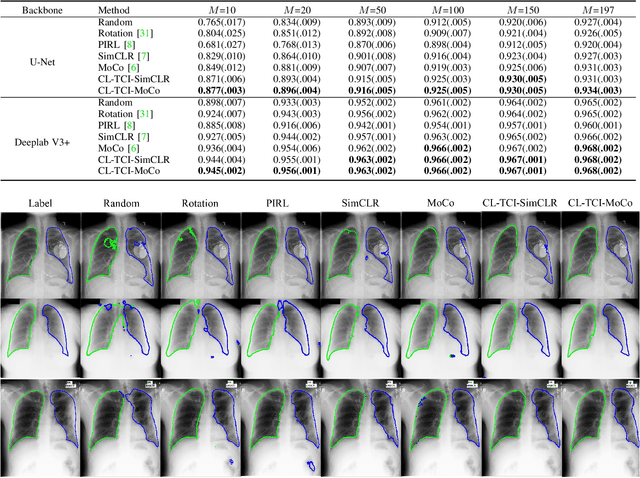
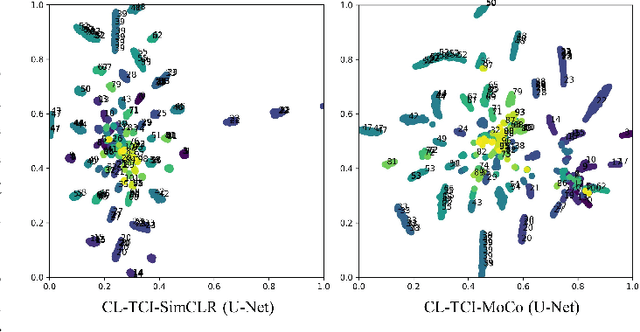
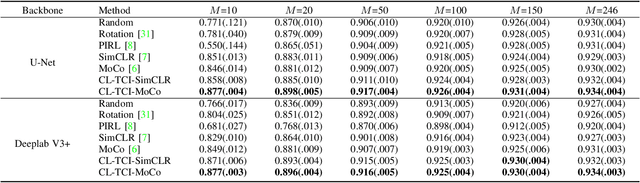
Contrastive learning has been proved to be a promising technique for image-level representation learning from unlabeled data. Many existing works have demonstrated improved results by applying contrastive learning in classification and object detection tasks for either natural images or medical images. However, its application to medical image segmentation tasks has been limited. In this work, we use lung segmentation in chest X-rays as a case study and propose a contrastive learning framework with temporal correlated medical images, named CL-TCI, to learn superior encoders for initializing the segmentation network. We adapt CL-TCI from two state-of-the-art contrastive learning methods-MoCo and SimCLR. Experiment results on three chest X-ray datasets show that under two different segmentation backbones, U-Net and Deeplab-V3, CL-TCI can outperform all baselines that do not incorporate any temporal correlation in both semi-supervised learning setting and transfer learning setting with limited annotation. This suggests that information among temporal correlated medical images can indeed improve contrastive learning performance. Between the two variations of CL-TCI, CL-TCI adapted from MoCo outperforms CL-TCI adapted from SimCLR in most settings, indicating that more contrastive samples can benefit the learning process and help the network learn high-quality representations.