 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSingle Microphone Own Voice Detection based on Simulated Transfer Functions for Hearing Aids
Mar 03, 2026This paper presents a simulation-based approach to own voice detection (OVD) in hearing aids using a single microphone. While OVD can significantly improve user comfort and speech intelligibility, existing solutions often rely on multiple microphones or additional sensors, increasing device complexity and cost. To enable ML-based OVD without requiring costly transfer-function measurements, we propose a data augmentation strategy based on simulated acoustic transfer functions (ATFs) that expose the model to a wide range of spatial propagation conditions. A transformer-based classifier is first trained on analytically generated ATFs and then progressively fine-tuned using numerically simulated ATFs, transitioning from a rigid-sphere model to a detailed head-and-torso representation. This hierarchical adaptation enabled the model to refine its spatial understanding while maintaining generalization. Experimental results show 95.52% accuracy on simulated head-and-torso test data. Under short-duration conditions, the model maintained 90.02% accuracy with one-second utterances. On real hearing aid recordings, the model achieved 80% accuracy without fine-tuning, aided by lightweight test-time feature compensation. This highlights the model's ability to generalize from simulated to real-world conditions, demonstrating practical viability and pointing toward a promising direction for future hearing aid design.
Genetic Programming for Explainable Manifold Learning
Mar 21, 2024
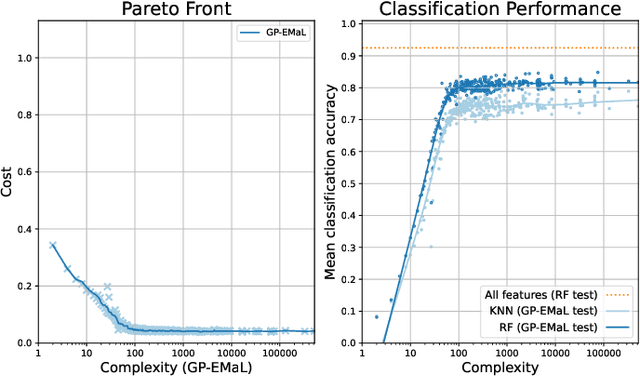
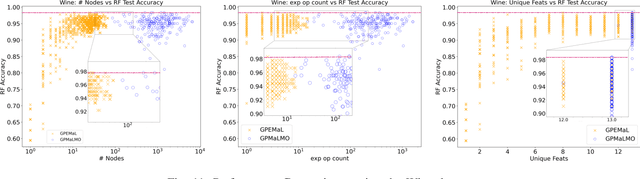
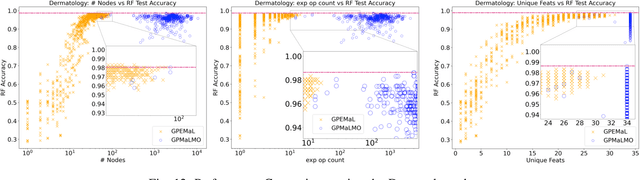
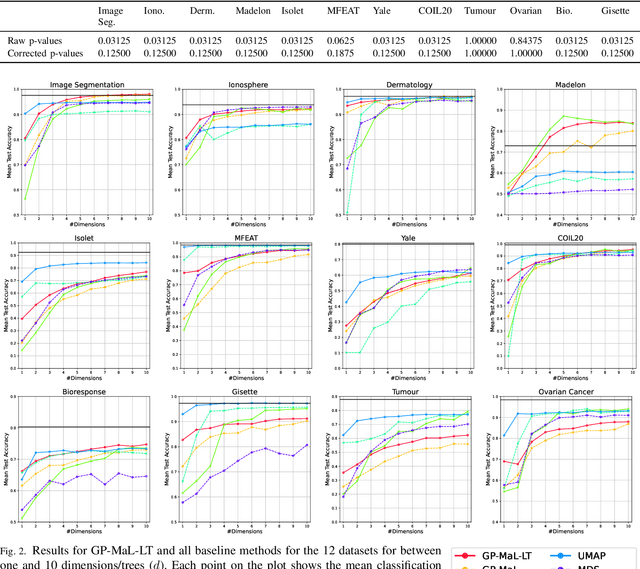
Manifold learning techniques play a pivotal role in machine learning by revealing lower-dimensional embeddings within high-dimensional data, thus enhancing both the efficiency and interpretability of data analysis by transforming the data into a lower-dimensional representation. However, a notable challenge with current manifold learning methods is their lack of explicit functional mappings, crucial for explainability in many real-world applications. Genetic programming, known for its interpretable functional tree-based models, has emerged as a promising approach to address this challenge. Previous research leveraged multi-objective GP to balance manifold quality against embedding dimensionality, producing functional mappings across a range of embedding sizes. Yet, these mapping trees often became complex, hindering explainability. In response, in this paper, we introduce Genetic Programming for Explainable Manifold Learning (GP-EMaL), a novel approach that directly penalises tree complexity. Our new method is able to maintain high manifold quality while significantly enhancing explainability and also allows customisation of complexity measures, such as symmetry balancing, scaling, and node complexity, catering to diverse application needs. Our experimental analysis demonstrates that GP-EMaL is able to match the performance of the existing approach in most cases, while using simpler, smaller, and more interpretable tree structures. This advancement marks a significant step towards achieving interpretable manifold learning.
Explaining Genetic Programming Trees using Large Language Models
Mar 06, 2024



Genetic programming (GP) has the potential to generate explainable results, especially when used for dimensionality reduction. In this research, we investigate the potential of leveraging eXplainable AI (XAI) and large language models (LLMs) like ChatGPT to improve the interpretability of GP-based non-linear dimensionality reduction. Our study introduces a novel XAI dashboard named GP4NLDR, the first approach to combine state-of-the-art GP with an LLM-powered chatbot to provide comprehensive, user-centred explanations. We showcase the system's ability to provide intuitive and insightful narratives on high-dimensional data reduction processes through case studies. Our study highlights the importance of prompt engineering in eliciting accurate and pertinent responses from LLMs. We also address important considerations around data privacy, hallucinatory outputs, and the rapid advancements in generative AI. Our findings demonstrate its potential in advancing the explainability of GP algorithms. This opens the door for future research into explaining GP models with LLMs.
Differentiable Genetic Programming for High-dimensional Symbolic Regression
Apr 18, 2023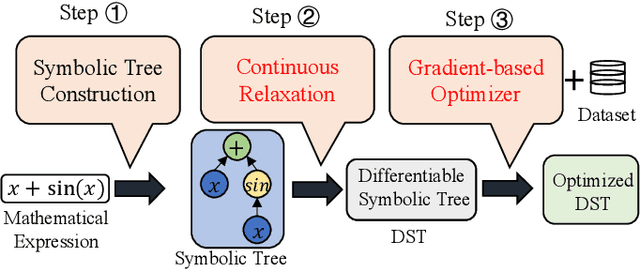



Symbolic regression (SR) is the process of discovering hidden relationships from data with mathematical expressions, which is considered an effective way to reach interpretable machine learning (ML). Genetic programming (GP) has been the dominator in solving SR problems. However, as the scale of SR problems increases, GP often poorly demonstrates and cannot effectively address the real-world high-dimensional problems. This limitation is mainly caused by the stochastic evolutionary nature of traditional GP in constructing the trees. In this paper, we propose a differentiable approach named DGP to construct GP trees towards high-dimensional SR for the first time. Specifically, a new data structure called differentiable symbolic tree is proposed to relax the discrete structure to be continuous, thus a gradient-based optimizer can be presented for the efficient optimization. In addition, a sampling method is proposed to eliminate the discrepancy caused by the above relaxation for valid symbolic expressions. Furthermore, a diversification mechanism is introduced to promote the optimizer escaping from local optima for globally better solutions. With these designs, the proposed DGP method can efficiently search for the GP trees with higher performance, thus being capable of dealing with high-dimensional SR. To demonstrate the effectiveness of DGP, we conducted various experiments against the state of the arts based on both GP and deep neural networks. The experiment results reveal that DGP can outperform these chosen peer competitors on high-dimensional regression benchmarks with dimensions varying from tens to thousands. In addition, on the synthetic SR problems, the proposed DGP method can also achieve the best recovery rate even with different noisy levels. It is believed this work can facilitate SR being a powerful alternative to interpretable ML for a broader range of real-world problems.
Feature-based Image Matching for Identifying Individual Kākā
Jan 24, 2023



This report investigates an unsupervised, feature-based image matching pipeline for the novel application of identifying individual k\=ak\=a. Applied with a similarity network for clustering, this addresses a weakness of current supervised approaches to identifying individual birds which struggle to handle the introduction of new individuals to the population. Our approach uses object localisation to locate k\=ak\=a within images and then extracts local features that are invariant to rotation and scale. These features are matched between images with nearest neighbour matching techniques and mismatch removal to produce a similarity score for image match comparison. The results show that matches obtained via the image matching pipeline achieve high accuracy of true matches. We conclude that feature-based image matching could be used with a similarity network to provide a viable alternative to existing supervised approaches.
Explainable Artificial Intelligence for Assault Sentence Prediction in New Zealand
Aug 15, 2022

The judiciary has historically been conservative in its use of Artificial Intelligence, but recent advances in machine learning have prompted scholars to reconsider such use in tasks like sentence prediction. This paper investigates by experimentation the potential use of explainable artificial intelligence for predicting imprisonment sentences in assault cases in New Zealand's courts. We propose a proof-of-concept explainable model and verify in practice that it is fit for purpose, with predicted sentences accurate to within one year. We further analyse the model to understand the most influential phrases in sentence length prediction. We conclude the paper with an evaluative discussion of the future benefits and risks of different ways of using such an AI model in New Zealand's courts.
Genetic Programming for Manifold Learning: Preserving Local Topology
Aug 23, 2021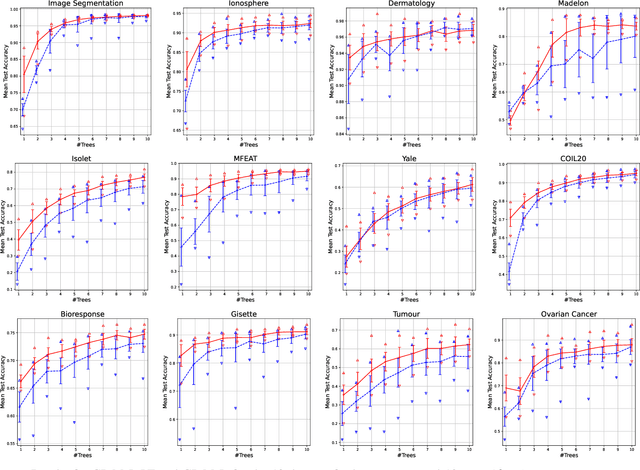

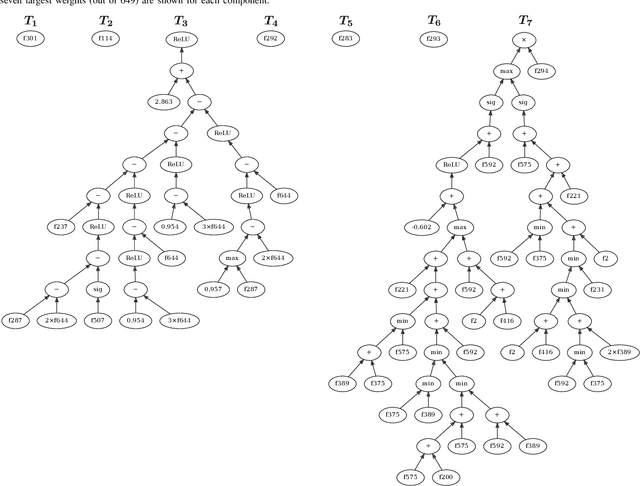
Manifold learning methods are an invaluable tool in today's world of increasingly huge datasets. Manifold learning algorithms can discover a much lower-dimensional representation (embedding) of a high-dimensional dataset through non-linear transformations that preserve the most important structure of the original data. State-of-the-art manifold learning methods directly optimise an embedding without mapping between the original space and the discovered embedded space. This makes interpretability - a key requirement in exploratory data analysis - nearly impossible. Recently, genetic programming has emerged as a very promising approach to manifold learning by evolving functional mappings from the original space to an embedding. However, genetic programming-based manifold learning has struggled to match the performance of other approaches. In this work, we propose a new approach to using genetic programming for manifold learning, which preserves local topology. This is expected to significantly improve performance on tasks where local neighbourhood structure (topology) is paramount. We compare our proposed approach with various baseline manifold learning methods and find that it often outperforms other methods, including a clear improvement over previous genetic programming approaches. These results are particularly promising, given the potential interpretability and reusability of the evolved mappings.
Mining Feature Relationships in Data
Feb 02, 2021



When faced with a new dataset, most practitioners begin by performing exploratory data analysis to discover interesting patterns and characteristics within data. Techniques such as association rule mining are commonly applied to uncover relationships between features (attributes) of the data. However, association rules are primarily designed for use on binary or categorical data, due to their use of rule-based machine learning. A large proportion of real-world data is continuous in nature, and discretisation of such data leads to inaccurate and less informative association rules. In this paper, we propose an alternative approach called feature relationship mining (FRM), which uses a genetic programming approach to automatically discover symbolic relationships between continuous or categorical features in data. To the best of our knowledge, our proposed approach is the first such symbolic approach with the goal of explicitly discovering relationships between features. Empirical testing on a variety of real-world datasets shows the proposed method is able to find high-quality, simple feature relationships which can be easily interpreted and which provide clear and non-trivial insight into data.
Genetic Programming for Evolving a Front of Interpretable Models for Data Visualisation
Jan 27, 2020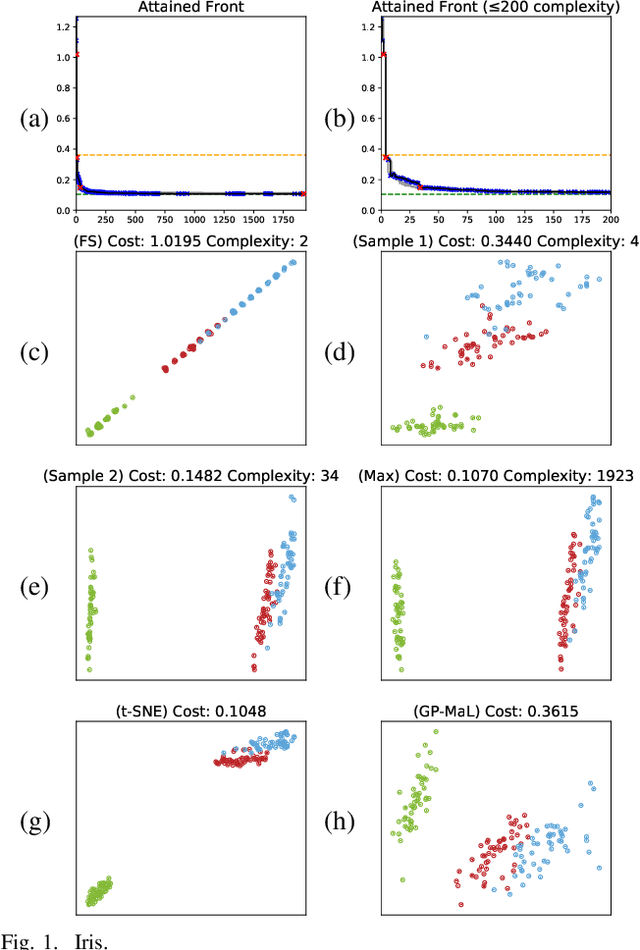
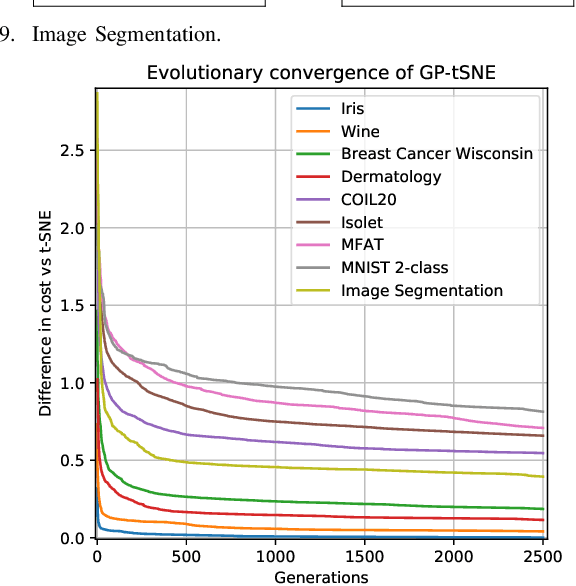
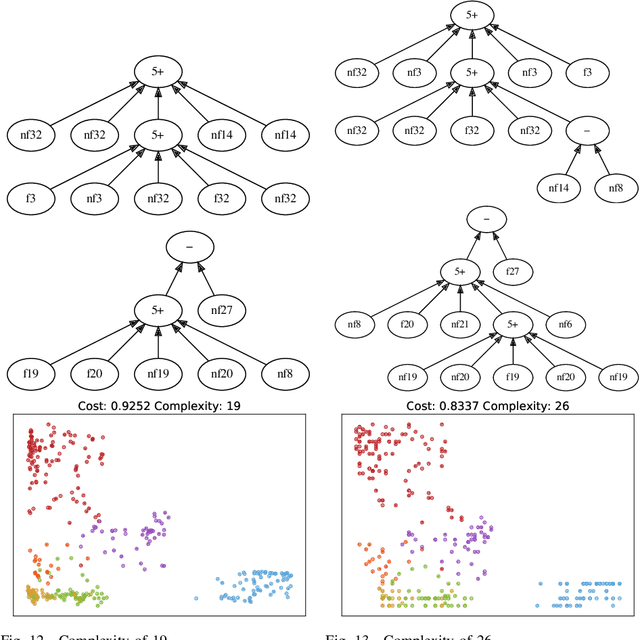

Data visualisation is a key tool in data mining for understanding big datasets. Many visualisation methods have been proposed, including the well-regarded state-of-the-art method t-Distributed Stochastic Neighbour Embedding. However, the most powerful visualisation methods have a significant limitation: the manner in which they create their visualisation from the original features of the dataset is completely opaque. Many domains require an understanding of the data in terms of the original features; there is hence a need for powerful visualisation methods which use understandable models. In this work, we propose a genetic programming approach named GPtSNE for evolving interpretable mappings from a dataset to highquality visualisations. A multi-objective approach is designed that produces a variety of visualisations in a single run which give different trade-offs between visual quality and model complexity. Testing against baseline methods on a variety of datasets shows the clear potential of GP-tSNE to allow deeper insight into data than that provided by existing visualisation methods. We further highlight the benefits of a multi-objective approach through an in-depth analysis of a candidate front, which shows how multiple models can
Multi-Objective Genetic Programming for Manifold Learning: Balancing Quality and Dimensionality
Jan 05, 2020

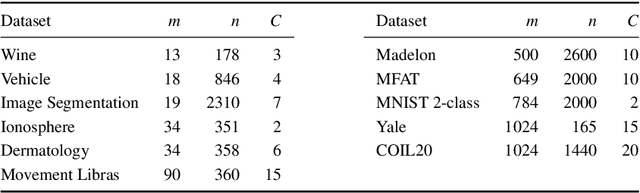

Manifold learning techniques have become increasingly valuable as data continues to grow in size. By discovering a lower-dimensional representation (embedding) of the structure of a dataset, manifold learning algorithms can substantially reduce the dimensionality of a dataset while preserving as much information as possible. However, state-of-the-art manifold learning algorithms are opaque in how they perform this transformation. Understanding the way in which the embedding relates to the original high-dimensional space is critical in exploratory data analysis. We previously proposed a Genetic Programming method that performed manifold learning by evolving mappings that are transparent and interpretable. This method required the dimensionality of the embedding to be known a priori, which makes it hard to use when little is known about a dataset. In this paper, we substantially extend our previous work, by introducing a multi-objective approach that automatically balances the competing objectives of manifold quality and dimensionality. Our proposed approach is competitive with a range of baseline and state-of-the-art manifold learning methods, while also providing a range (front) of solutions that give different trade-offs between quality and dimensionality. Furthermore, the learned models are shown to often be simple and efficient, utilising only a small number of features in an interpretable manner.