 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging Label Information for Multimodal Emotion Recognition
Sep 05, 2023Multimodal emotion recognition (MER) aims to detect the emotional status of a given expression by combining the speech and text information. Intuitively, label information should be capable of helping the model locate the salient tokens/frames relevant to the specific emotion, which finally facilitates the MER task. Inspired by this, we propose a novel approach for MER by leveraging label information. Specifically, we first obtain the representative label embeddings for both text and speech modalities, then learn the label-enhanced text/speech representations for each utterance via label-token and label-frame interactions. Finally, we devise a novel label-guided attentive fusion module to fuse the label-aware text and speech representations for emotion classification. Extensive experiments were conducted on the public IEMOCAP dataset, and experimental results demonstrate that our proposed approach outperforms existing baselines and achieves new state-of-the-art performance.
Gated Multimodal Fusion with Contrastive Learning for Turn-taking Prediction in Human-robot Dialogue
Apr 18, 2022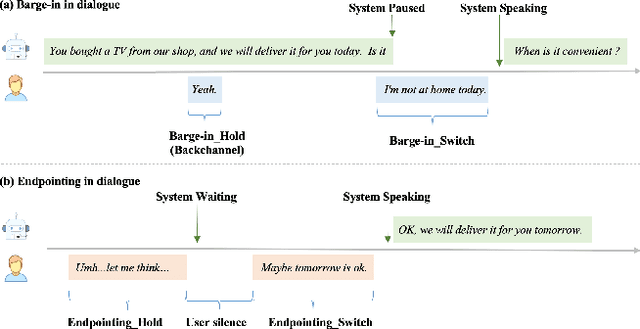
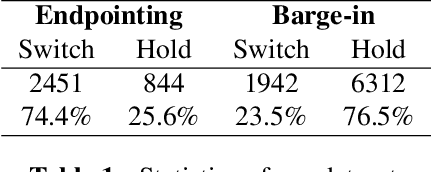
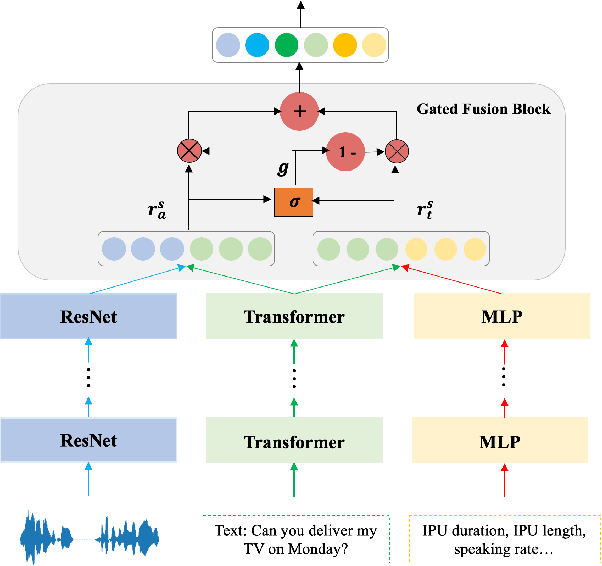

Turn-taking, aiming to decide when the next speaker can start talking, is an essential component in building human-robot spoken dialogue systems. Previous studies indicate that multimodal cues can facilitate this challenging task. However, due to the paucity of public multimodal datasets, current methods are mostly limited to either utilizing unimodal features or simplistic multimodal ensemble models. Besides, the inherent class imbalance in real scenario, e.g. sentence ending with short pause will be mostly regarded as the end of turn, also poses great challenge to the turn-taking decision. In this paper, we first collect a large-scale annotated corpus for turn-taking with over 5,000 real human-robot dialogues in speech and text modalities. Then, a novel gated multimodal fusion mechanism is devised to utilize various information seamlessly for turn-taking prediction. More importantly, to tackle the data imbalance issue, we design a simple yet effective data augmentation method to construct negative instances without supervision and apply contrastive learning to obtain better feature representations. Extensive experiments are conducted and the results demonstrate the superiority and competitiveness of our model over several state-of-the-art baselines.