 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConvergence of Gradient Descent on Separable Data
Jun 12, 2018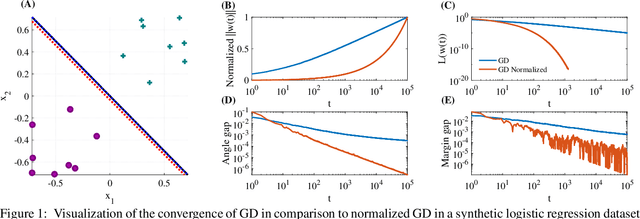
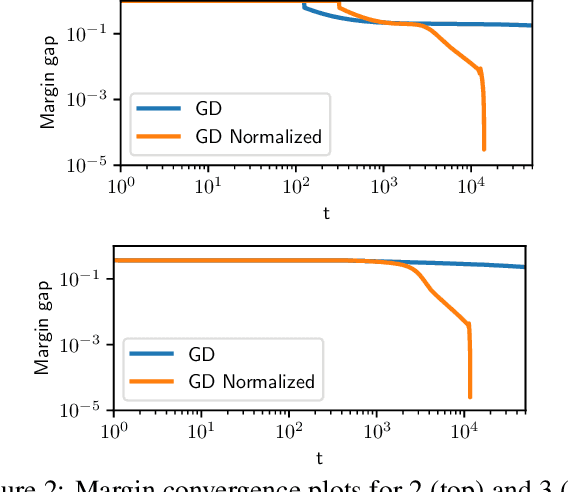
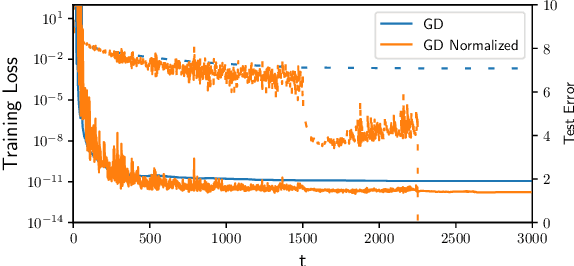
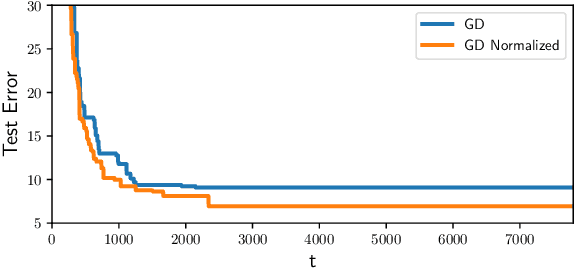
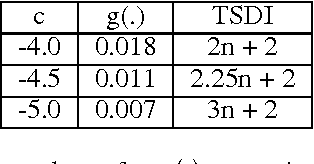
The implicit bias of gradient descent is not fully understood even in simple linear classification tasks (e.g., logistic regression). Soudry et al. (2018) studied this bias on separable data, where there are multiple solutions that correctly classify the data. It was found that, when optimizing monotonically decreasing loss functions with exponential tails using gradient descent, the linear classifier specified by the gradient descent iterates converge to the $L_2$ max margin separator. However, the convergence rate to the maximum margin solution with fixed step size was found to be extremely slow: $1/\log(t)$. Here we examine how the convergence is influenced by using different loss functions and by using variable step sizes. First, we calculate the convergence rate for loss functions with poly-exponential tails near $\exp(-u^{\nu})$. We prove that $\nu=1$ yields the optimal convergence rate in the range $\nu>0.25$. Based on further analysis we conjecture that this remains the optimal rate for $\nu \leq 0.25$, and even for sub-poly-exponential tails --- until loss functions with polynomial tails no longer converge to the max margin. Second, we prove the convergence rate could be improved to $(\log t) /\sqrt{t}$ for the exponential loss, by using aggressive step sizes which compensate for the rapidly vanishing gradients.
From Monte Carlo to Las Vegas: Improving Restricted Boltzmann Machine Training Through Stopping Sets
Nov 22, 2017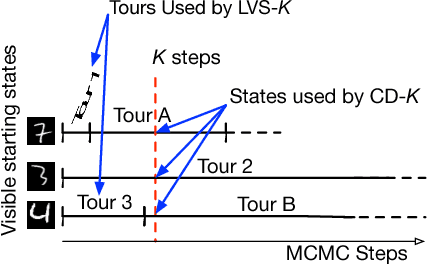

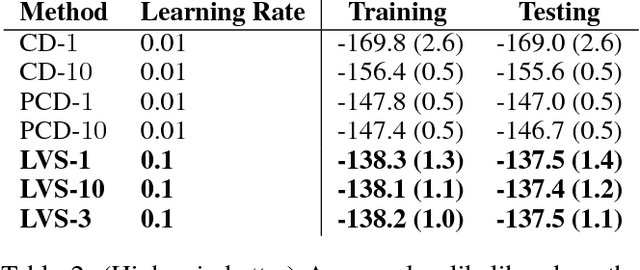
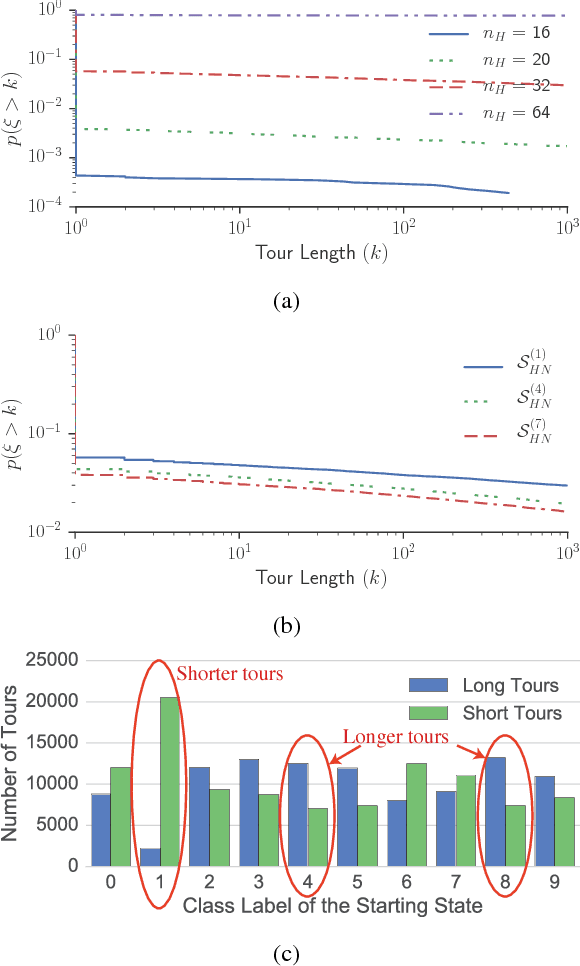
We propose a Las Vegas transformation of Markov Chain Monte Carlo (MCMC) estimators of Restricted Boltzmann Machines (RBMs). We denote our approach Markov Chain Las Vegas (MCLV). MCLV gives statistical guarantees in exchange for random running times. MCLV uses a stopping set built from the training data and has maximum number of Markov chain steps K (referred as MCLV-K). We present a MCLV-K gradient estimator (LVS-K) for RBMs and explore the correspondence and differences between LVS-K and Contrastive Divergence (CD-K), with LVS-K significantly outperforming CD-K training RBMs over the MNIST dataset, indicating MCLV to be a promising direction in learning generative models.
* AAAI2018, 10 Pages
Learning Identity Mappings with Residual Gates
Dec 29, 2016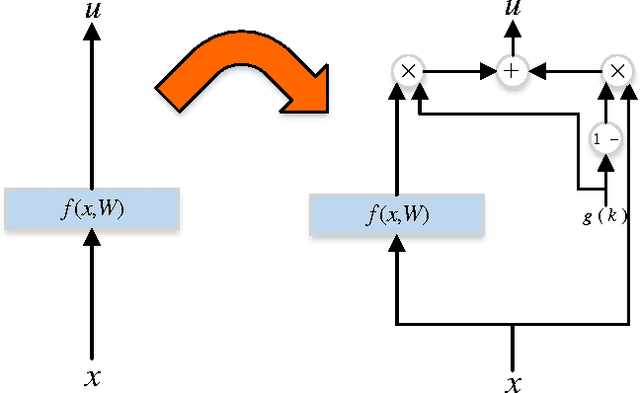
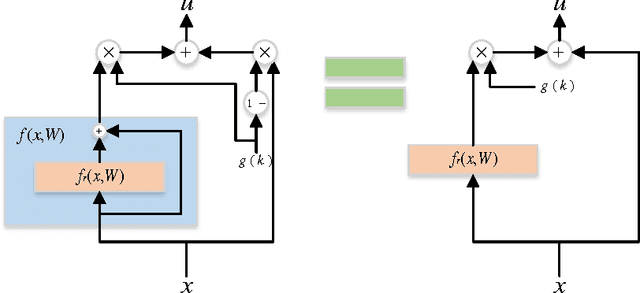
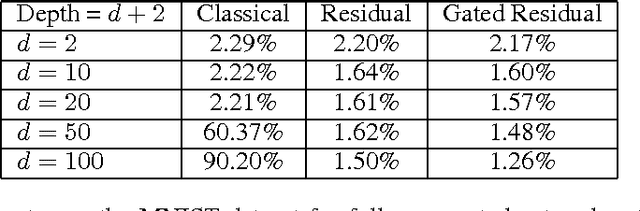
We propose a new layer design by adding a linear gating mechanism to shortcut connections. By using a scalar parameter to control each gate, we provide a way to learn identity mappings by optimizing only one parameter. We build upon the motivation behind Residual Networks, where a layer is reformulated in order to make learning identity mappings less problematic to the optimizer. The augmentation introduces only one extra parameter per layer, and provides easier optimization by making degeneration into identity mappings simpler. We propose a new model, the Gated Residual Network, which is the result when augmenting Residual Networks. Experimental results show that augmenting layers provides better optimization, increased performance, and more layer independence. We evaluate our method on MNIST using fully-connected networks, showing empirical indications that our augmentation facilitates the optimization of deep models, and that it provides high tolerance to full layer removal: the model retains over 90% of its performance even after half of its layers have been randomly removed. We also evaluate our model on CIFAR-10 and CIFAR-100 using Wide Gated ResNets, achieving 3.65% and 18.27% error, respectively.