 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Identity Mappings with Residual Gates
Paper and Code
Dec 29, 2016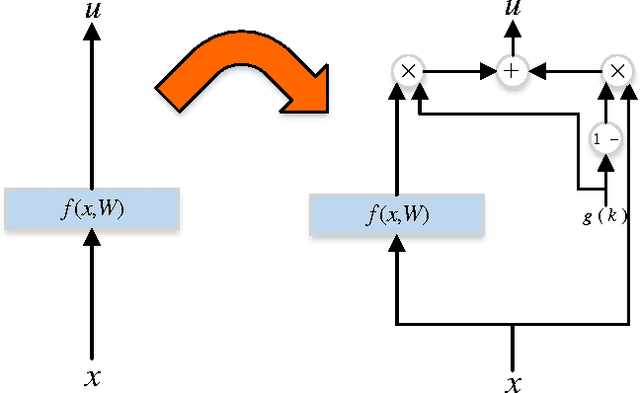
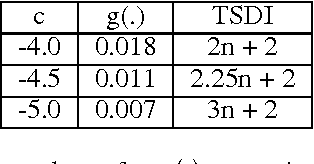
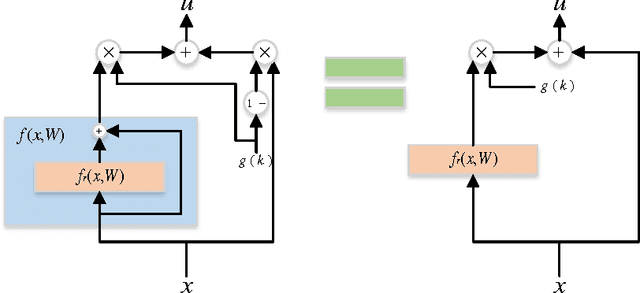
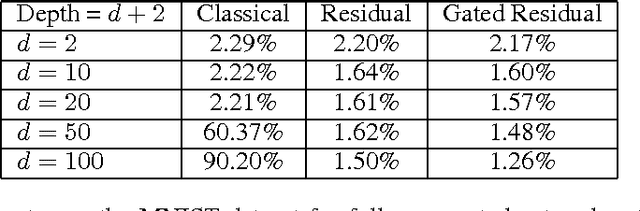
We propose a new layer design by adding a linear gating mechanism to shortcut connections. By using a scalar parameter to control each gate, we provide a way to learn identity mappings by optimizing only one parameter. We build upon the motivation behind Residual Networks, where a layer is reformulated in order to make learning identity mappings less problematic to the optimizer. The augmentation introduces only one extra parameter per layer, and provides easier optimization by making degeneration into identity mappings simpler. We propose a new model, the Gated Residual Network, which is the result when augmenting Residual Networks. Experimental results show that augmenting layers provides better optimization, increased performance, and more layer independence. We evaluate our method on MNIST using fully-connected networks, showing empirical indications that our augmentation facilitates the optimization of deep models, and that it provides high tolerance to full layer removal: the model retains over 90% of its performance even after half of its layers have been randomly removed. We also evaluate our model on CIFAR-10 and CIFAR-100 using Wide Gated ResNets, achieving 3.65% and 18.27% error, respectively.