 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan Language Models Analyze Data? Evaluating Large Language Models for Question Answering over Datasets
May 11, 2026This paper investigates the effectiveness of large language models (LLMs) in answering questions over datasets. We examine their performance in two scenarios: (a) directly answering questions given a dataset file as input, and (b) generating SQL queries to answer questions given the schema of a relational database. We also evaluate the impact of different prompting strategies on model performance. The study includes both state-of-the-art LLMs and smaller language models that require fewer resources and operate at lower computational and financial cost. Experiments are conducted on two datasets containing questions of varying difficulty. The results demonstrate the strong performance of large LLMs, while highlighting the limitations of smaller, more cost-efficient models. These findings contribute to a better understanding of how LLMs can be utilized in data analytics tasks and their associated limitations.
Better Together -- An Ensemble Learner for Combining the Results of Ready-made Entity Linking Systems
Jan 14, 2021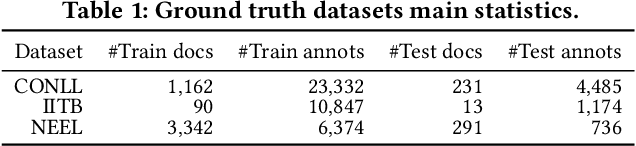
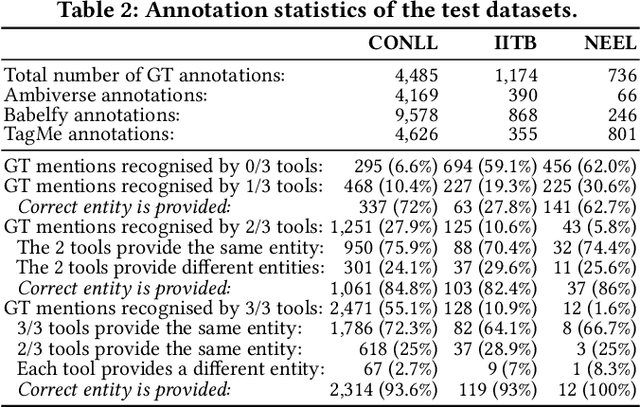
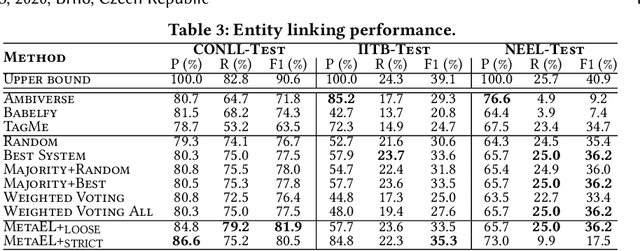
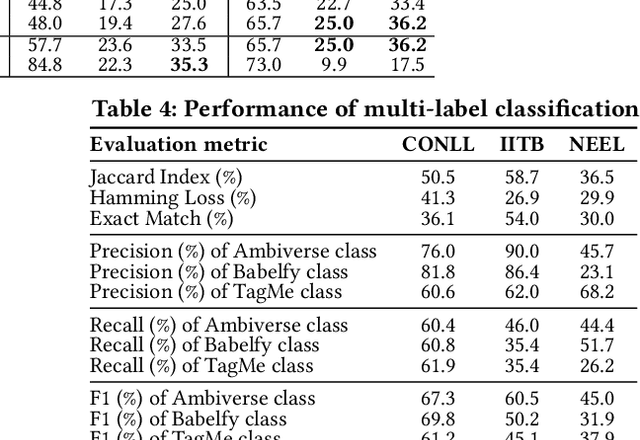
Entity linking (EL) is the task of automatically identifying entity mentions in text and resolving them to a corresponding entity in a reference knowledge base like Wikipedia. Throughout the past decade, a plethora of EL systems and pipelines have become available, where performance of individual systems varies heavily across corpora, languages or domains. Linking performance varies even between different mentions in the same text corpus, where, for instance, some EL approaches are better able to deal with short surface forms while others may perform better when more context information is available. To this end, we argue that performance may be optimised by exploiting results from distinct EL systems on the same corpus, thereby leveraging their individual strengths on a per-mention basis. In this paper, we introduce a supervised approach which exploits the output of multiple ready-made EL systems by predicting the correct link on a per-mention basis. Experimental results obtained on existing ground truth datasets and exploiting three state-of-the-art EL systems show the effectiveness of our approach and its capacity to significantly outperform the individual EL systems as well as a set of baseline methods.
Exploiting stance hierarchies for cost-sensitive stance detection of Web documents
Jul 29, 2020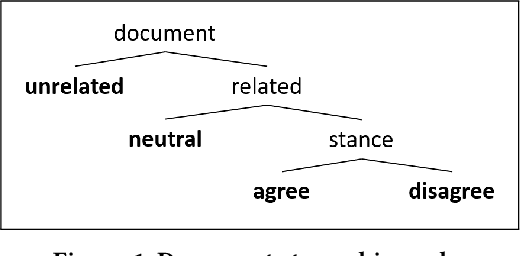
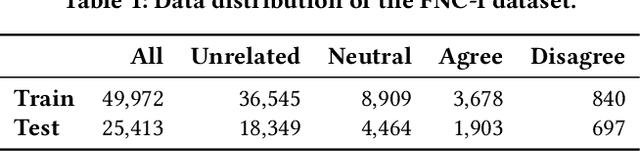
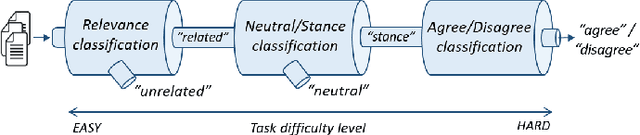
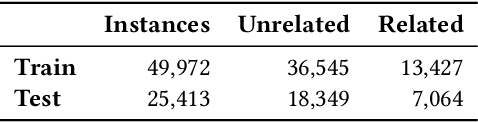
Fact checking is an essential challenge when combating fake news. Identifying documents that agree or disagree with a particular statement (claim) is a core task in this process. In this context, stance detection aims at identifying the position (stance) of a document towards a claim. Most approaches address this task through a 4-class classification model where the class distribution is highly imbalanced. Therefore, they are particularly ineffective in detecting the minority classes (for instance, 'disagree'), even though such instances are crucial for tasks such as fact-checking by providing evidence for detecting false claims. In this paper, we exploit the hierarchical nature of stance classes, which allows us to propose a modular pipeline of cascading binary classifiers, enabling performance tuning on a per step and class basis. We implement our approach through a combination of neural and traditional classification models that highlight the misclassification costs of minority classes. Evaluation results demonstrate state-of-the-art performance of our approach and its ability to significantly improve the classification performance of the important 'disagree' class.
Same but Different: Distant Supervision for Predicting and Understanding Entity Linking Difficulty
Dec 13, 2018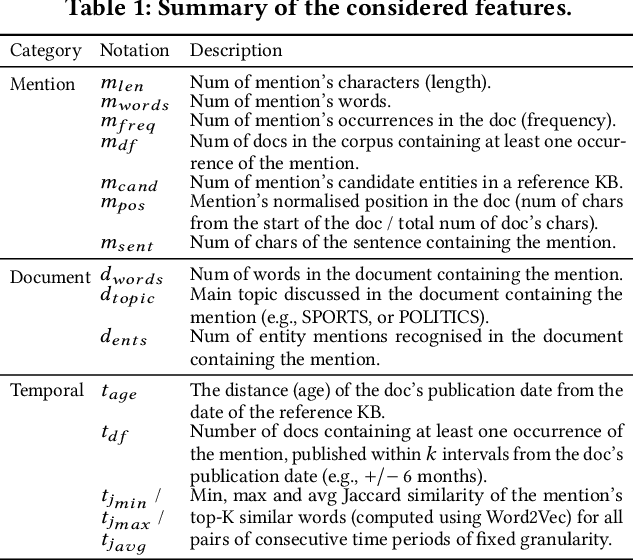
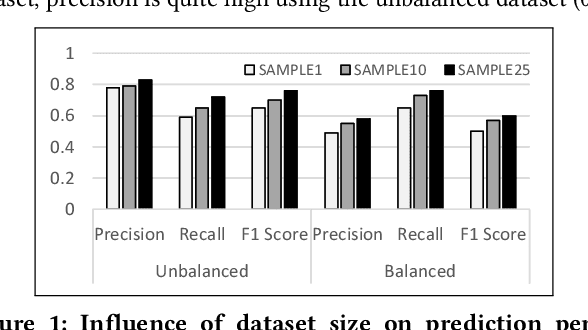
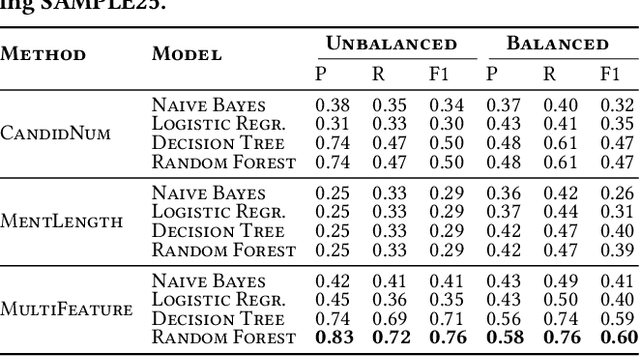

Entity Linking (EL) is the task of automatically identifying entity mentions in a piece of text and resolving them to a corresponding entity in a reference knowledge base like Wikipedia. There is a large number of EL tools available for different types of documents and domains, yet EL remains a challenging task where the lack of precision on particularly ambiguous mentions often spoils the usefulness of automated disambiguation results in real applications. A priori approximations of the difficulty to link a particular entity mention can facilitate flagging of critical cases as part of semi-automated EL systems, while detecting latent factors that affect the EL performance, like corpus-specific features, can provide insights on how to improve a system based on the special characteristics of the underlying corpus. In this paper, we first introduce a consensus-based method to generate difficulty labels for entity mentions on arbitrary corpora. The difficulty labels are then exploited as training data for a supervised classification task able to predict the EL difficulty of entity mentions using a variety of features. Experiments over a corpus of news articles show that EL difficulty can be estimated with high accuracy, revealing also latent features that affect EL performance. Finally, evaluation results demonstrate the effectiveness of the proposed method to inform semi-automated EL pipelines.
Time-Aware and Corpus-Specific Entity Relatedness
Oct 23, 2018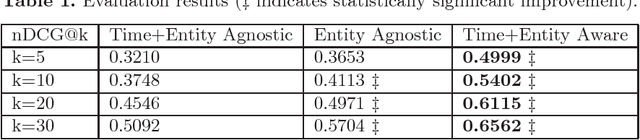
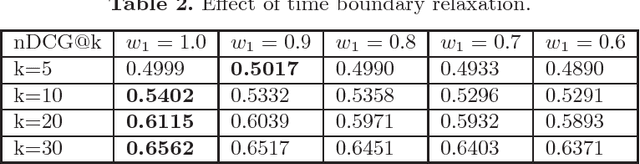
Entity relatedness has emerged as an important feature in a plethora of applications such as information retrieval, entity recommendation and entity linking. Given an entity, for instance a person or an organization, entity relatedness measures can be exploited for generating a list of highly-related entities. However, the relation of an entity to some other entity depends on several factors, with time and context being two of the most important ones (where, in our case, context is determined by a particular corpus). For example, the entities related to the International Monetary Fund are different now compared to some years ago, while these entities also may highly differ in the context of a USA news portal compared to a Greek news portal. In this paper, we propose a simple but flexible model for entity relatedness which considers time and entity aware word embeddings by exploiting the underlying corpus. The proposed model does not require external knowledge and is language independent, which makes it widely useful in a variety of applications.