 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredicting household socioeconomic position in Mozambique using satellite and household imagery
Nov 13, 2024



Many studies have predicted SocioEconomic Position (SEP) for aggregated spatial units such as villages using satellite data, but SEP prediction at the household level and other sources of imagery have not been yet explored. We assembled a dataset of 975 households in a semi-rural district in southern Mozambique, consisting of self-reported asset, expenditure, and income SEP data, as well as multimodal imagery including satellite images and a ground-based photograph survey of 11 household elements. We fine-tuned a convolutional neural network to extract feature vectors from the images, which we then used in regression analyzes to model household SEP using different sets of image types. The best prediction performance was found when modeling asset-based SEP using random forest models with all image types, while the performance for expenditure- and income-based SEP was lower. Using SHAP, we observed clear differences between the images with the largest positive and negative effects, as well as identified the most relevant household elements in the predictions. Finally, we fitted an additional reduced model using only the identified relevant household elements, which had an only slightly lower performance compared to models using all images. Our results show how ground-based household photographs allow to zoom in from an area-level to an individual household prediction while minimizing the data collection effort by using explainable machine learning. The developed workflow can be potentially integrated into routine household surveys, where the collected household imagery could be used for other purposes, such as refined asset characterization and environmental exposure assessment.
Assessing the risk of re-identification arising from an attack on anonymised data
Mar 31, 2022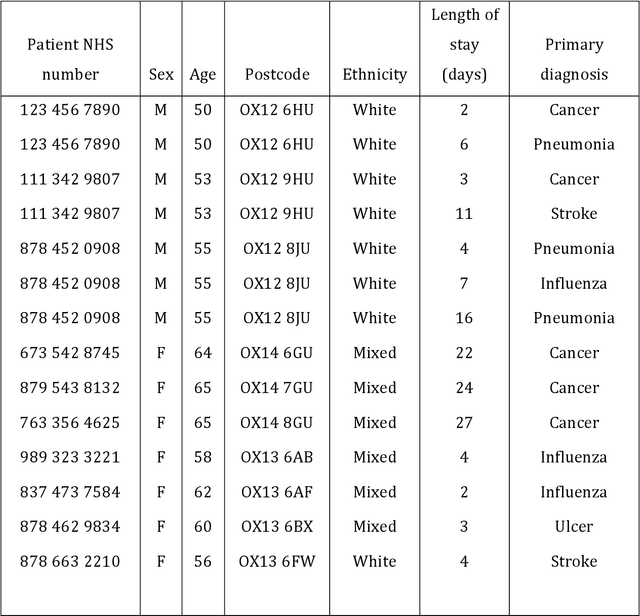
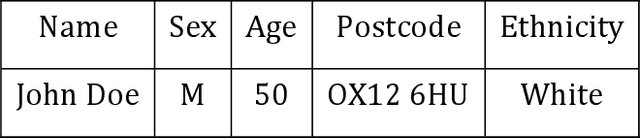
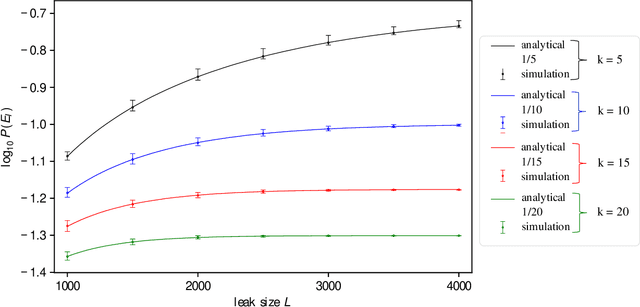
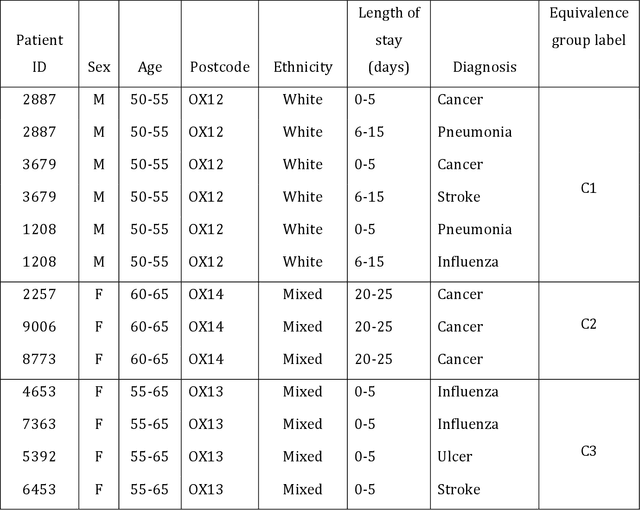
Objective: The use of routinely-acquired medical data for research purposes requires the protection of patient confidentiality via data anonymisation. The objective of this work is to calculate the risk of re-identification arising from a malicious attack to an anonymised dataset, as described below. Methods: We first present an analytical means of estimating the probability of re-identification of a single patient in a k-anonymised dataset of Electronic Health Record (EHR) data. Second, we generalize this solution to obtain the probability of multiple patients being re-identified. We provide synthetic validation via Monte Carlo simulations to illustrate the accuracy of the estimates obtained. Results: The proposed analytical framework for risk estimation provides re-identification probabilities that are in agreement with those provided by simulation in a number of scenarios. Our work is limited by conservative assumptions which inflate the re-identification probability. Discussion: Our estimates show that the re-identification probability increases with the proportion of the dataset maliciously obtained and that it has an inverse relationship with the equivalence class size. Our recursive approach extends the applicability domain to the general case of a multi-patient re-identification attack in an arbitrary k-anonymisation scheme. Conclusion: We prescribe a systematic way to parametrize the k-anonymisation process based on a pre-determined re-identification probability. We observed that the benefits of a reduced re-identification risk that come with increasing k-size may not be worth the reduction in data granularity when one is considering benchmarking the re-identification probability on the size of the portion of the dataset maliciously obtained by the adversary.
Voxelwise nonlinear regression toolbox for neuroimage analysis: Application to aging and neurodegenerative disease modeling
Apr 18, 2017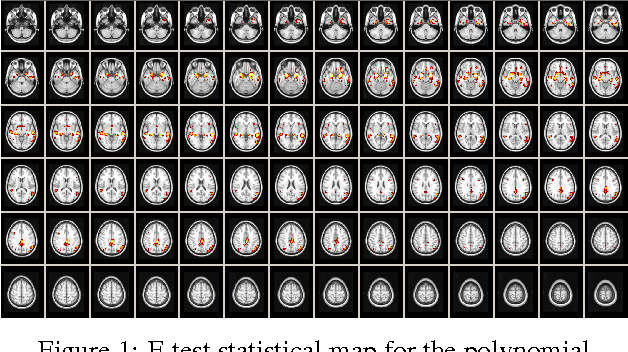
This paper describes a new neuroimaging analysis toolbox that allows for the modeling of nonlinear effects at the voxel level, overcoming limitations of methods based on linear models like the GLM. We illustrate its features using a relevant example in which distinct nonlinear trajectories of Alzheimer's disease related brain atrophy patterns were found across the full biological spectrum of the disease. The open-source toolbox presented in this paper is available at https://github.com/imatge-upc/VNeAT.