 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAssessing the risk of re-identification arising from an attack on anonymised data
Paper and Code
Mar 31, 2022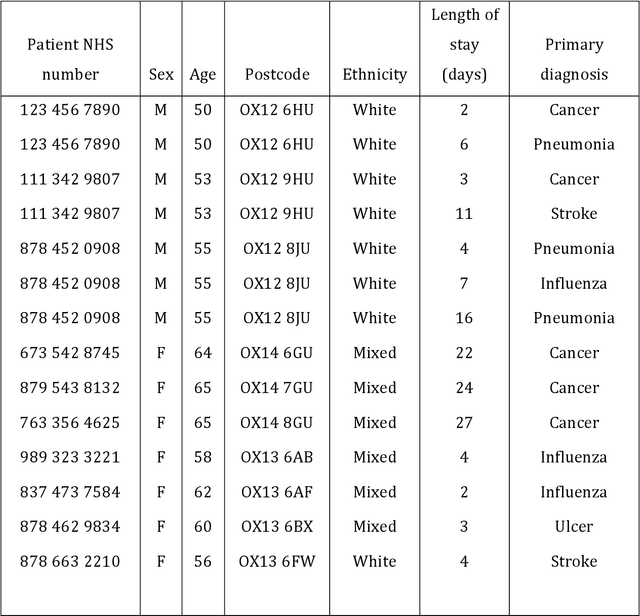
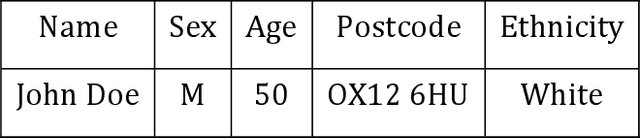
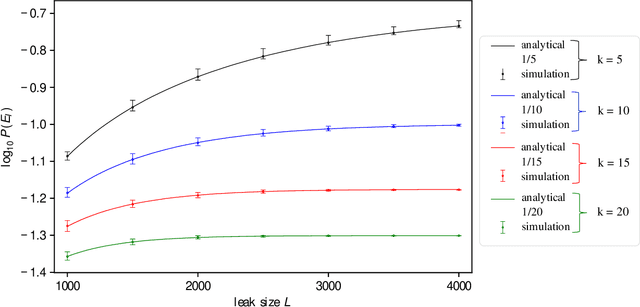
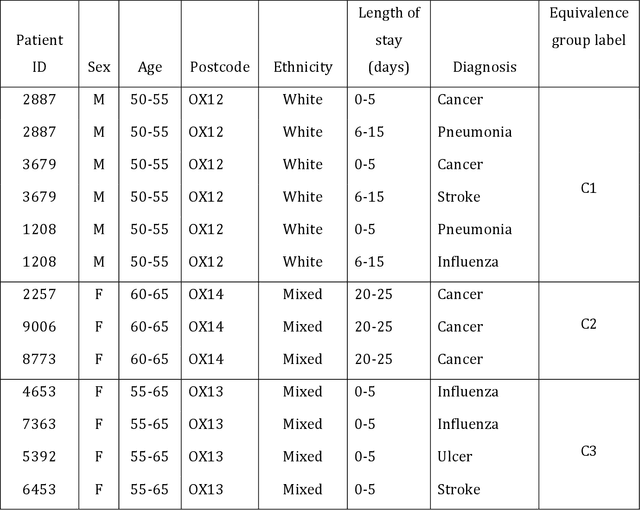
Objective: The use of routinely-acquired medical data for research purposes requires the protection of patient confidentiality via data anonymisation. The objective of this work is to calculate the risk of re-identification arising from a malicious attack to an anonymised dataset, as described below. Methods: We first present an analytical means of estimating the probability of re-identification of a single patient in a k-anonymised dataset of Electronic Health Record (EHR) data. Second, we generalize this solution to obtain the probability of multiple patients being re-identified. We provide synthetic validation via Monte Carlo simulations to illustrate the accuracy of the estimates obtained. Results: The proposed analytical framework for risk estimation provides re-identification probabilities that are in agreement with those provided by simulation in a number of scenarios. Our work is limited by conservative assumptions which inflate the re-identification probability. Discussion: Our estimates show that the re-identification probability increases with the proportion of the dataset maliciously obtained and that it has an inverse relationship with the equivalence class size. Our recursive approach extends the applicability domain to the general case of a multi-patient re-identification attack in an arbitrary k-anonymisation scheme. Conclusion: We prescribe a systematic way to parametrize the k-anonymisation process based on a pre-determined re-identification probability. We observed that the benefits of a reduced re-identification risk that come with increasing k-size may not be worth the reduction in data granularity when one is considering benchmarking the re-identification probability on the size of the portion of the dataset maliciously obtained by the adversary.