 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredicting household socioeconomic position in Mozambique using satellite and household imagery
Nov 13, 2024



Many studies have predicted SocioEconomic Position (SEP) for aggregated spatial units such as villages using satellite data, but SEP prediction at the household level and other sources of imagery have not been yet explored. We assembled a dataset of 975 households in a semi-rural district in southern Mozambique, consisting of self-reported asset, expenditure, and income SEP data, as well as multimodal imagery including satellite images and a ground-based photograph survey of 11 household elements. We fine-tuned a convolutional neural network to extract feature vectors from the images, which we then used in regression analyzes to model household SEP using different sets of image types. The best prediction performance was found when modeling asset-based SEP using random forest models with all image types, while the performance for expenditure- and income-based SEP was lower. Using SHAP, we observed clear differences between the images with the largest positive and negative effects, as well as identified the most relevant household elements in the predictions. Finally, we fitted an additional reduced model using only the identified relevant household elements, which had an only slightly lower performance compared to models using all images. Our results show how ground-based household photographs allow to zoom in from an area-level to an individual household prediction while minimizing the data collection effort by using explainable machine learning. The developed workflow can be potentially integrated into routine household surveys, where the collected household imagery could be used for other purposes, such as refined asset characterization and environmental exposure assessment.
The CAST package for training and assessment of spatial prediction models in R
Apr 10, 2024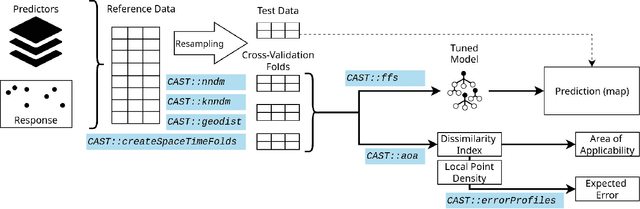



One key task in environmental science is to map environmental variables continuously in space or even in space and time. Machine learning algorithms are frequently used to learn from local field observations to make spatial predictions by estimating the value of the variable of interest in places where it has not been measured. However, the application of machine learning strategies for spatial mapping involves additional challenges compared to "non-spatial" prediction tasks that often originate from spatial autocorrelation and from training data that are not independent and identically distributed. In the past few years, we developed a number of methods to support the application of machine learning for spatial data which involves the development of suitable cross-validation strategies for performance assessment and model selection, spatial feature selection, and methods to assess the area of applicability of the trained models. The intention of the CAST package is to support the application of machine learning strategies for predictive mapping by implementing such methods and making them available for easy integration into modelling workflows. Here we introduce the CAST package and its core functionalities. At the case study of mapping plant species richness, we will go through the different steps of the modelling workflow and show how CAST can be used to support more reliable spatial predictions.