 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe CAST package for training and assessment of spatial prediction models in R
Apr 10, 2024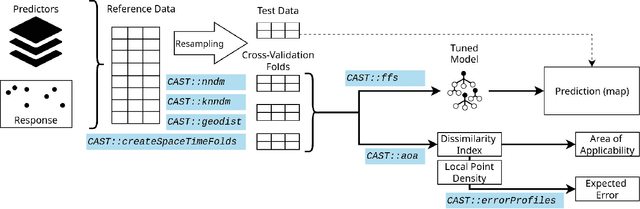



One key task in environmental science is to map environmental variables continuously in space or even in space and time. Machine learning algorithms are frequently used to learn from local field observations to make spatial predictions by estimating the value of the variable of interest in places where it has not been measured. However, the application of machine learning strategies for spatial mapping involves additional challenges compared to "non-spatial" prediction tasks that often originate from spatial autocorrelation and from training data that are not independent and identically distributed. In the past few years, we developed a number of methods to support the application of machine learning for spatial data which involves the development of suitable cross-validation strategies for performance assessment and model selection, spatial feature selection, and methods to assess the area of applicability of the trained models. The intention of the CAST package is to support the application of machine learning strategies for predictive mapping by implementing such methods and making them available for easy integration into modelling workflows. Here we introduce the CAST package and its core functionalities. At the case study of mapping plant species richness, we will go through the different steps of the modelling workflow and show how CAST can be used to support more reliable spatial predictions.
Predicting into unknown space? Estimating the area of applicability of spatial prediction models
May 16, 2020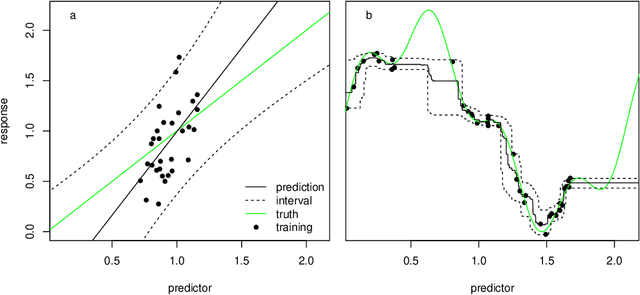
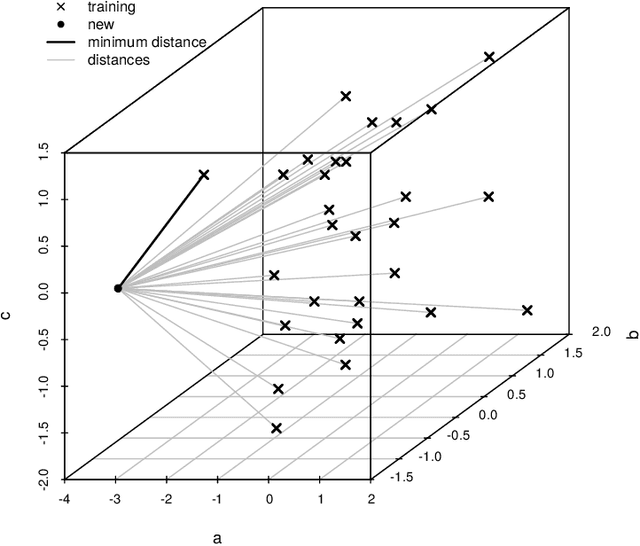
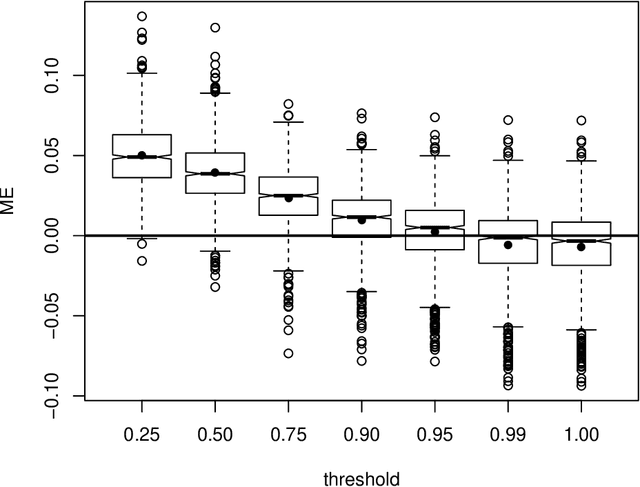
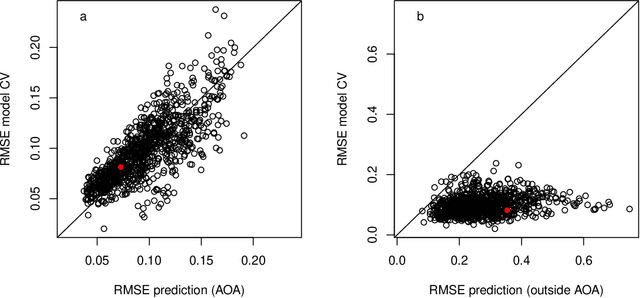
Predictive modelling using machine learning has become very popular for spatial mapping of the environment. Models are often applied to make predictions far beyond sampling locations where new geographic locations might considerably differ from the training data in their environmental properties. However, areas in the predictor space without support of training data are problematic. Since the model has no knowledge about these environments, predictions have to be considered uncertain. Estimating the area to which a prediction model can be reliably applied is required. Here, we suggest a methodology that delineates the "area of applicability" (AOA) that we define as the area, for which the cross-validation error of the model applies. We first propose a "dissimilarity index" (DI) that is based on the minimum distance to the training data in the predictor space, with predictors being weighted by their respective importance in the model. The AOA is then derived by applying a threshold based on the DI of the training data where the DI is calculated with respect to the cross-validation strategy used for model training. We test for the ideal threshold by using simulated data and compare the prediction error within the AOA with the cross-validation error of the model. We illustrate the approach using a simulated case study. Our simulation study suggests a threshold on DI to define the AOA at the .95 quantile of the DI in the training data. Using this threshold, the prediction error within the AOA is comparable to the cross-validation RMSE of the model, while the cross-validation error does not apply outside the AOA. This applies to models being trained with randomly distributed training data, as well as when training data are clustered in space and where spatial cross-validation is applied. We suggest to report the AOA alongside predictions, complementary to validation measures.
Importance of spatial predictor variable selection in machine learning applications -- Moving from data reproduction to spatial prediction
Aug 21, 2019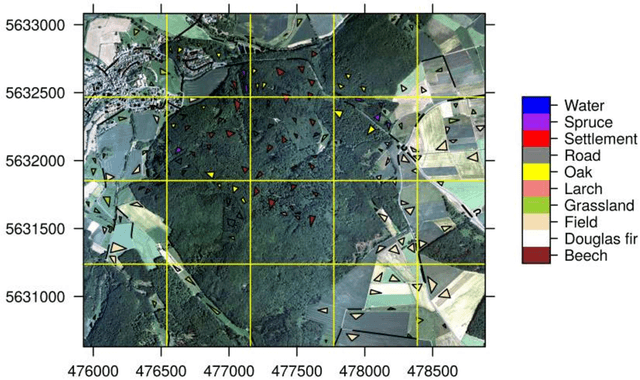
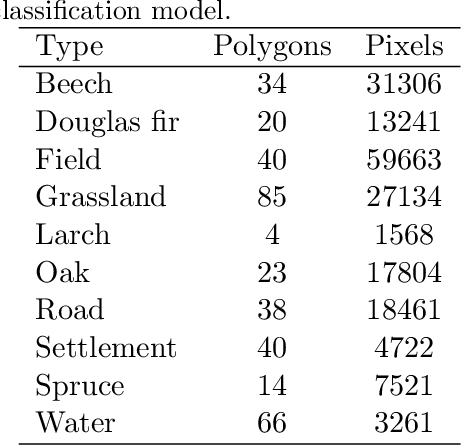
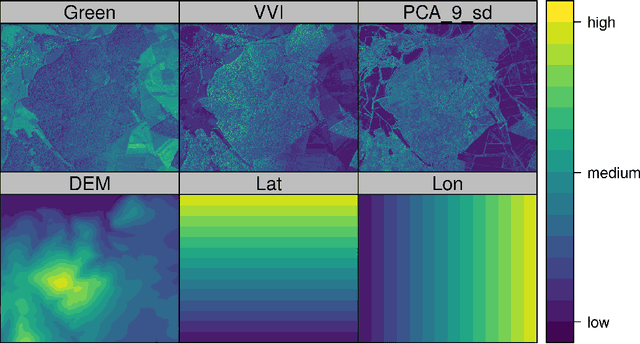
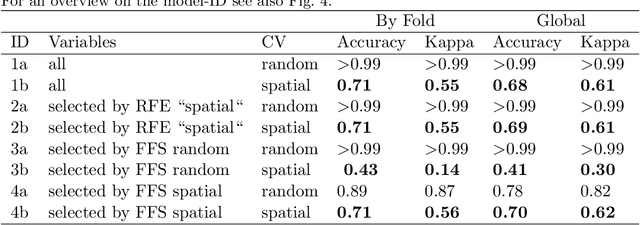
Machine learning algorithms find frequent application in spatial prediction of biotic and abiotic environmental variables. However, the characteristics of spatial data, especially spatial autocorrelation, are widely ignored. We hypothesize that this is problematic and results in models that can reproduce training data but are unable to make spatial predictions beyond the locations of the training samples. We assume that not only spatial validation strategies but also spatial variable selection is essential for reliable spatial predictions. We introduce two case studies that use remote sensing to predict land cover and the leaf area index for the "Marburg Open Forest", an open research and education site of Marburg University, Germany. We use the machine learning algorithm Random Forests to train models using non-spatial and spatial cross-validation strategies to understand how spatial variable selection affects the predictions. Our findings confirm that spatial cross-validation is essential in preventing overoptimistic model performance. We further show that highly autocorrelated predictors (such as geolocation variables, e.g. latitude, longitude) can lead to considerable overfitting and result in models that can reproduce the training data but fail in making spatial predictions. The problem becomes apparent in the visual assessment of the spatial predictions that show clear artefacts that can be traced back to a misinterpretation of the spatially autocorrelated predictors by the algorithm. Spatial variable selection could automatically detect and remove such variables that lead to overfitting, resulting in reliable spatial prediction patterns and improved statistical spatial model performance. We conclude that in addition to spatial validation, a spatial variable selection must be considered in spatial predictions of ecological data to produce reliable predictions.