 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding Mental States in Active and Autonomous Driving with EEG
Dec 09, 2025Understanding how driver mental states differ between active and autonomous driving is critical for designing safe human-vehicle interfaces. This paper presents the first EEG-based comparison of cognitive load, fatigue, valence, and arousal across the two driving modes. Using data from 31 participants performing identical tasks in both scenarios of three different complexity levels, we analyze temporal patterns, task-complexity effects, and channel-wise activation differences. Our findings show that although both modes evoke similar trends across complexity levels, the intensity of mental states and the underlying neural activation differ substantially, indicating a clear distribution shift between active and autonomous driving. Transfer-learning experiments confirm that models trained on active driving data generalize poorly to autonomous driving and vice versa. We attribute this distribution shift primarily to differences in motor engagement and attentional demands between the two driving modes, which lead to distinct spatial and temporal EEG activation patterns. Although autonomous driving results in lower overall cortical activation, participants continue to exhibit measurable fluctuations in cognitive load, fatigue, valence, and arousal associated with readiness to intervene, task-evoked emotional responses, and monotony-related passive fatigue. These results emphasize the need for scenario-specific data and models when developing next-generation driver monitoring systems for autonomous vehicles.
Graph-Based Learning of Spectro-Topographical EEG Representations with Gradient Alignment for Brain-Computer Interfaces
Dec 08, 2025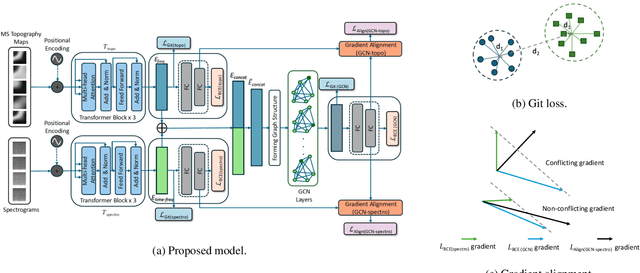
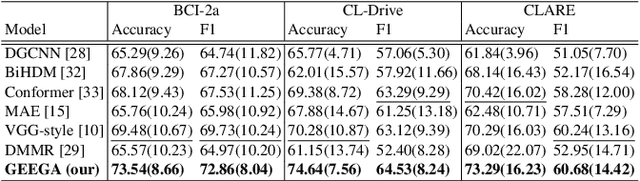
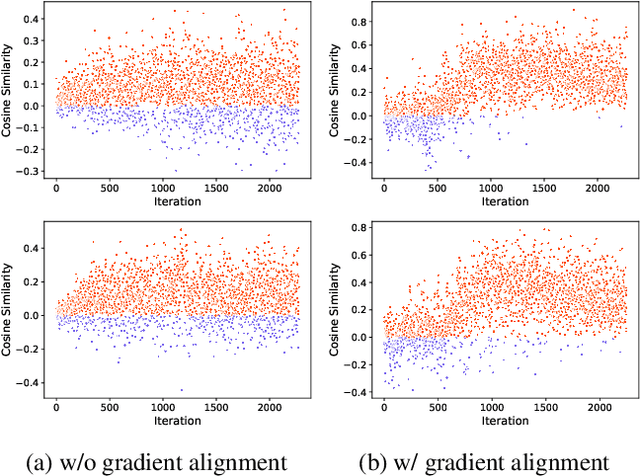
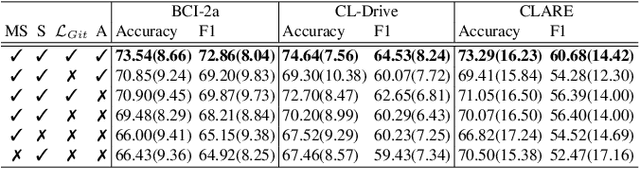
We present a novel graph-based learning of EEG representations with gradient alignment (GEEGA) that leverages multi-domain information to learn EEG representations for brain-computer interfaces. Our model leverages graph convolutional networks to fuse embeddings from frequency-based topographical maps and time-frequency spectrograms, capturing inter-domain relationships. GEEGA addresses the challenge of achieving high inter-class separability, which arises from the temporally dynamic and subject-sensitive nature of EEG signals by incorporating the center loss and pairwise difference loss. Additionally, GEEGA incorporates a gradient alignment strategy to resolve conflicts between gradients from different domains and the fused embeddings, ensuring that discrepancies, where gradients point in conflicting directions, are aligned toward a unified optimization direction. We validate the efficacy of our method through extensive experiments on three publicly available EEG datasets: BCI-2a, CL-Drive and CLARE. Comprehensive ablation studies further highlight the impact of various components of our model.
Multi-Domain EEG Representation Learning with Orthogonal Mapping and Attention-based Fusion for Cognitive Load Classification
Nov 16, 2025We propose a new representation learning solution for the classification of cognitive load based on Electroencephalogram (EEG). Our method integrates both time and frequency domains by first passing the raw EEG signals through the convolutional encoder to obtain the time domain representations. Next, we measure the Power Spectral Density (PSD) for all five EEG frequency bands and generate the channel power values as 2D images referred to as multi-spectral topography maps. These multi-spectral topography maps are then fed to a separate encoder to obtain the representations in frequency domain. Our solution employs a multi-domain attention module that maps these domain-specific embeddings onto a shared embedding space to emphasize more on important inter-domain relationships to enhance the representations for cognitive load classification. Additionally, we incorporate an orthogonal projection constraint during the training of our method to effectively increase the inter-class distances while improving intra-class clustering. This enhancement allows efficient discrimination between different cognitive states and aids in better grouping of similar states within the feature space. We validate the effectiveness of our model through extensive experiments on two public EEG datasets, CL-Drive and CLARE for cognitive load classification. Our results demonstrate the superiority of our multi-domain approach over the traditional single-domain techniques. Moreover, we conduct ablation and sensitivity analyses to assess the impact of various components of our method. Finally, robustness experiments on different amounts of added noise demonstrate the stability of our method compared to other state-of-the-art solutions.
CLARE: Cognitive Load Assessment in REaltime with Multimodal Data
Apr 26, 2024



We present a novel multimodal dataset for Cognitive Load Assessment in REaltime (CLARE). The dataset contains physiological and gaze data from 24 participants with self-reported cognitive load scores as ground-truth labels. The dataset consists of four modalities, namely, Electrocardiography (ECG), Electrodermal Activity (EDA), Electroencephalogram (EEG), and Gaze tracking. To map diverse levels of mental load on participants during experiments, each participant completed four nine-minutes sessions on a computer-based operator performance and mental workload task (the MATB-II software) with varying levels of complexity in one minute segments. During the experiment, participants reported their cognitive load every 10 seconds. For the dataset, we also provide benchmark binary classification results with machine learning and deep learning models on two different evaluation schemes, namely, 10-fold and leave-one-subject-out (LOSO) cross-validation. Benchmark results show that for 10-fold evaluation, the convolutional neural network (CNN) based deep learning model achieves the best classification performance with ECG, EDA, and Gaze. In contrast, for LOSO, the best performance is achieved by the deep learning model with ECG, EDA, and EEG.
EEG-based Cognitive Load Classification using Feature Masked Autoencoding and Emotion Transfer Learning
Aug 01, 2023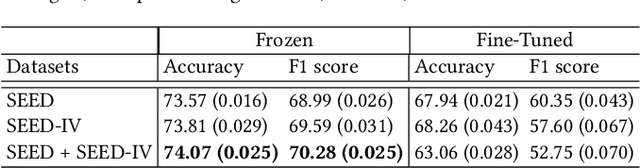
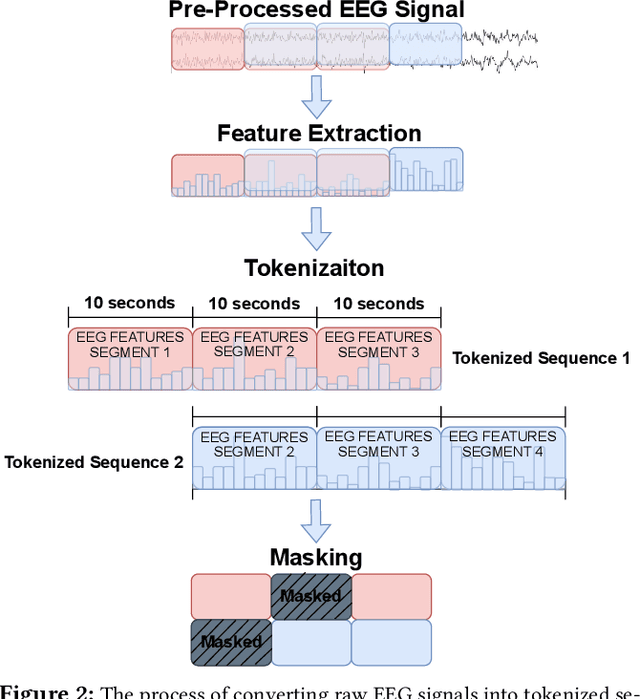
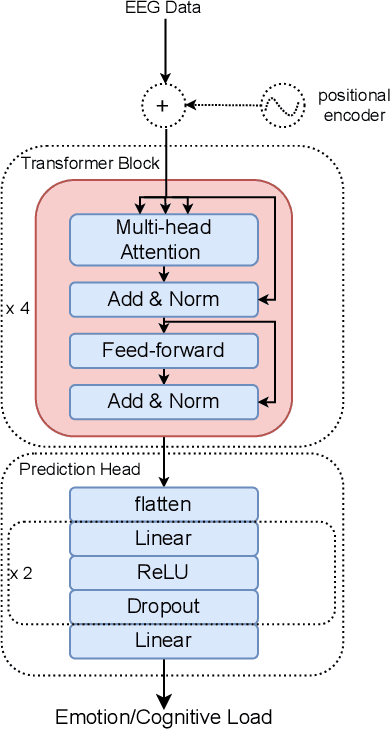
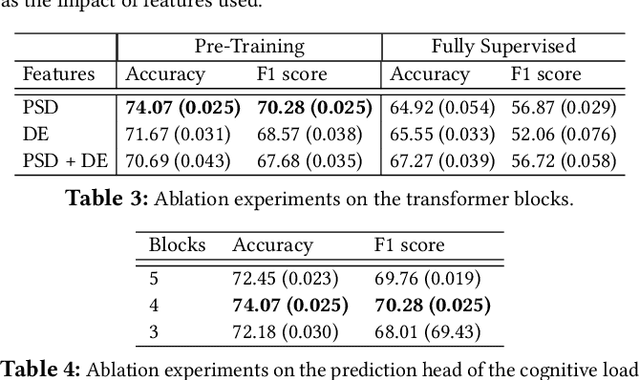
Cognitive load, the amount of mental effort required for task completion, plays an important role in performance and decision-making outcomes, making its classification and analysis essential in various sensitive domains. In this paper, we present a new solution for the classification of cognitive load using electroencephalogram (EEG). Our model uses a transformer architecture employing transfer learning between emotions and cognitive load. We pre-train our model using self-supervised masked autoencoding on emotion-related EEG datasets and use transfer learning with both frozen weights and fine-tuning to perform downstream cognitive load classification. To evaluate our method, we carry out a series of experiments utilizing two publicly available EEG-based emotion datasets, namely SEED and SEED-IV, for pre-training, while we use the CL-Drive dataset for downstream cognitive load classification. The results of our experiments show that our proposed approach achieves strong results and outperforms conventional single-stage fully supervised learning. Moreover, we perform detailed ablation and sensitivity studies to evaluate the impact of different aspects of our proposed solution. This research contributes to the growing body of literature in affective computing with a focus on cognitive load, and opens up new avenues for future research in the field of cross-domain transfer learning using self-supervised pre-training.
Multimodal Brain-Computer Interface for In-Vehicle Driver Cognitive Load Measurement: Dataset and Baselines
Apr 09, 2023

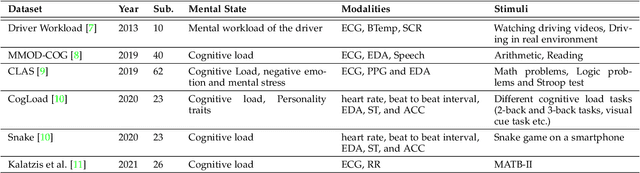
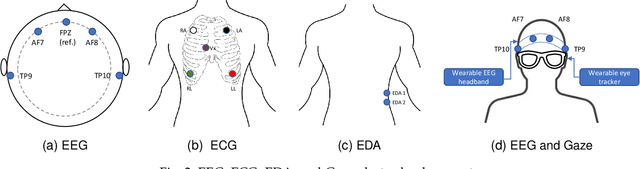
Through this paper, we introduce a novel driver cognitive load assessment dataset, CL-Drive, which contains Electroencephalogram (EEG) signals along with other physiological signals such as Electrocardiography (ECG) and Electrodermal Activity (EDA) as well as eye tracking data. The data was collected from 21 subjects while driving in an immersive vehicle simulator, in various driving conditions, to induce different levels of cognitive load in the subjects. The tasks consisted of 9 complexity levels for 3 minutes each. Each driver reported their subjective cognitive load every 10 seconds throughout the experiment. The dataset contains the subjective cognitive load recorded as ground truth. In this paper, we also provide benchmark classification results for different machine learning and deep learning models for both binary and ternary label distributions. We followed 2 evaluation criteria namely 10-fold and leave-one-subject-out (LOSO). We have trained our models on both hand-crafted features as well as on raw data.
Multistream Gaze Estimation with Anatomical Eye Region Isolation by Synthetic to Real Transfer Learning
Jun 18, 2022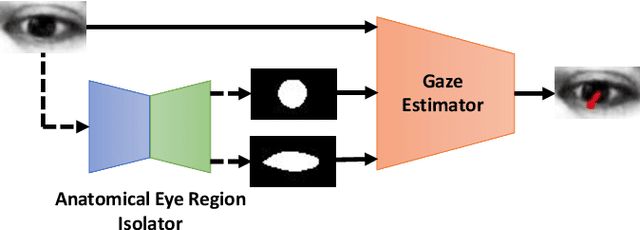
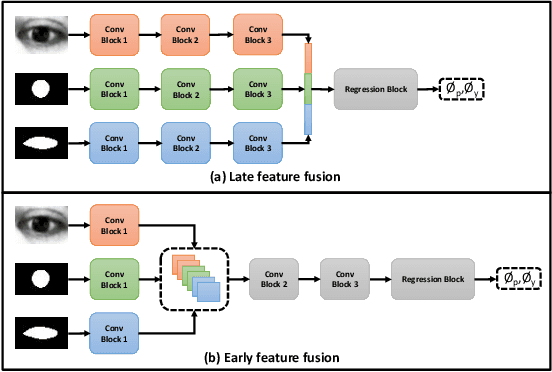
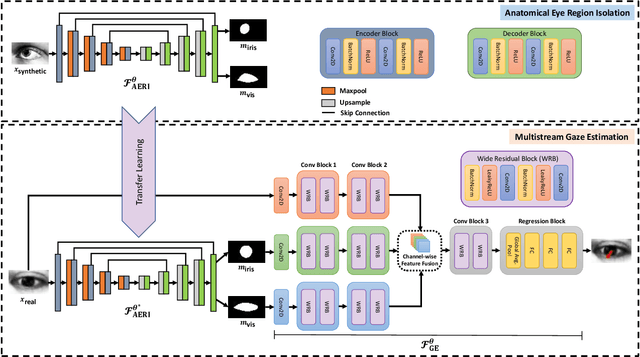
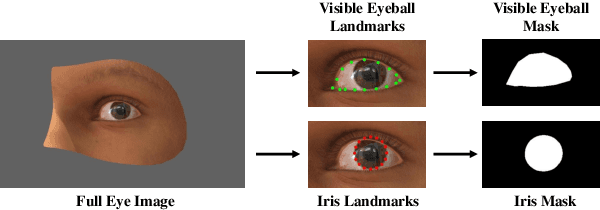
We propose a novel neural pipeline, MSGazeNet, that learns gaze representations by taking advantage of the eye anatomy information through a multistream framework. Our proposed solution comprises two components, first a network for isolating anatomical eye regions, and a second network for multistream gaze estimation. The eye region isolation is performed with a U-Net style network which we train using a synthetic dataset that contains eye region masks for the visible eyeball and the iris region. The synthetic dataset used in this stage is a new dataset consisting of 60,000 eye images, which we create using an eye-gaze simulator, UnityEyes. Successive to training, the eye region isolation network is then transferred to the real domain for generating masks for the real-world eye images. In order to successfully make the transfer, we exploit domain randomization in the training process, which allows for the synthetic images to benefit from a larger variance with the help of augmentations that resemble artifacts. The generated eye region masks along with the raw eye images are then used together as a multistream input to our gaze estimation network. We evaluate our framework on three benchmark gaze estimation datasets, MPIIGaze, Eyediap, and UTMultiview, where we set a new state-of-the-art on Eyediap and UTMultiview datasets by obtaining a performance gain of 7.57% and 1.85% respectively, while achieving competitive performance on MPIIGaze. We also study the robustness of our method with respect to the noise in the data and demonstrate that our model is less sensitive to noisy data. Lastly, we perform a variety of experiments including ablation studies to evaluate the contribution of different components and design choices in our solution.
AttX: Attentive Cross-Connections for Fusion of Wearable Signals in Emotion Recognition
Jun 09, 2022
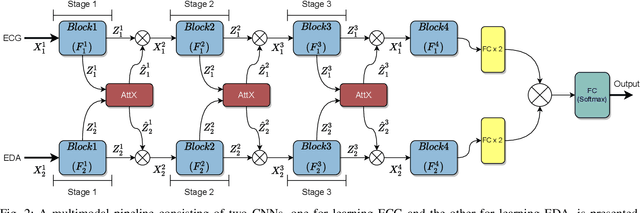


We propose cross-modal attentive connections, a new dynamic and effective technique for multimodal representation learning from wearable data. Our solution can be integrated into any stage of the pipeline, i.e., after any convolutional layer or block, to create intermediate connections between individual streams responsible for processing each modality. Additionally, our method benefits from two properties. First, it can share information uni-directionally (from one modality to the other) or bi-directionally. Second, it can be integrated into multiple stages at the same time to further allow network gradients to be exchanged in several touch-points. We perform extensive experiments on three public multimodal wearable datasets, WESAD, SWELL-KW, and CASE, and demonstrate that our method can effectively regulate and share information between different modalities to learn better representations. Our experiments further demonstrate that once integrated into simple CNN-based multimodal solutions (2, 3, or 4 modalities), our method can result in superior or competitive performance to state-of-the-art and outperform a variety of baseline uni-modal and classical multimodal methods.
Gaze Estimation with Eye Region Segmentation and Self-Supervised Multistream Learning
Dec 15, 2021
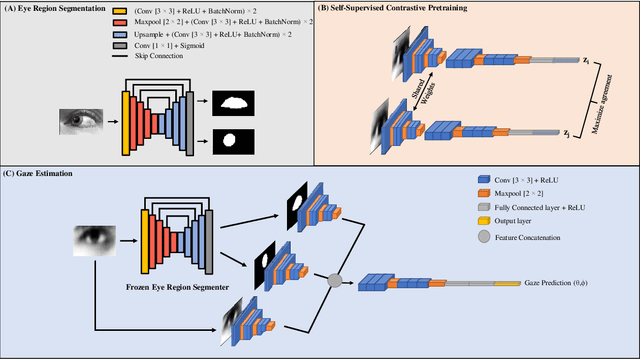


We present a novel multistream network that learns robust eye representations for gaze estimation. We first create a synthetic dataset containing eye region masks detailing the visible eyeball and iris using a simulator. We then perform eye region segmentation with a U-Net type model which we later use to generate eye region masks for real-world eye images. Next, we pretrain an eye image encoder in the real domain with self-supervised contrastive learning to learn generalized eye representations. Finally, this pretrained eye encoder, along with two additional encoders for visible eyeball region and iris, are used in parallel in our multistream framework to extract salient features for gaze estimation from real-world images. We demonstrate the performance of our method on the EYEDIAP dataset in two different evaluation settings and achieve state-of-the-art results, outperforming all the existing benchmarks on this dataset. We also conduct additional experiments to validate the robustness of our self-supervised network with respect to different amounts of labeled data used for training.
A Transformer Architecture for Stress Detection from ECG
Aug 22, 2021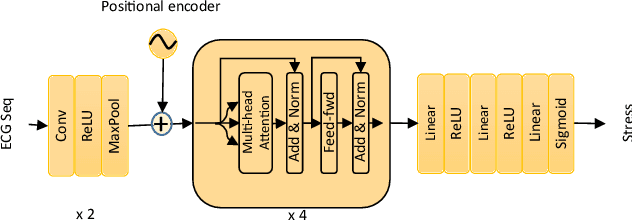
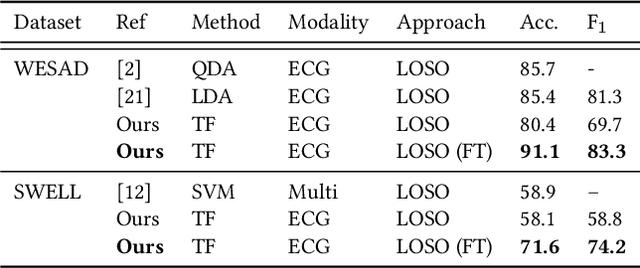
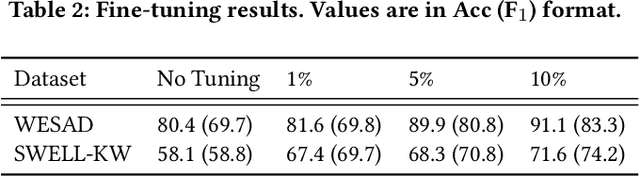
Electrocardiogram (ECG) has been widely used for emotion recognition. This paper presents a deep neural network based on convolutional layers and a transformer mechanism to detect stress using ECG signals. We perform leave-one-subject-out experiments on two publicly available datasets, WESAD and SWELL-KW, to evaluate our method. Our experiments show that the proposed model achieves strong results, comparable or better than the state-of-the-art models for ECG-based stress detection on these two datasets. Moreover, our method is end-to-end, does not require handcrafted features, and can learn robust representations with only a few convolutional blocks and the transformer component.