 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttX: Attentive Cross-Connections for Fusion of Wearable Signals in Emotion Recognition
Paper and Code
Jun 09, 2022
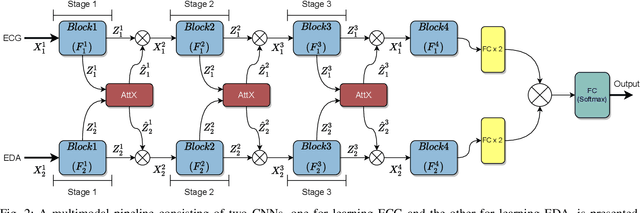


We propose cross-modal attentive connections, a new dynamic and effective technique for multimodal representation learning from wearable data. Our solution can be integrated into any stage of the pipeline, i.e., after any convolutional layer or block, to create intermediate connections between individual streams responsible for processing each modality. Additionally, our method benefits from two properties. First, it can share information uni-directionally (from one modality to the other) or bi-directionally. Second, it can be integrated into multiple stages at the same time to further allow network gradients to be exchanged in several touch-points. We perform extensive experiments on three public multimodal wearable datasets, WESAD, SWELL-KW, and CASE, and demonstrate that our method can effectively regulate and share information between different modalities to learn better representations. Our experiments further demonstrate that once integrated into simple CNN-based multimodal solutions (2, 3, or 4 modalities), our method can result in superior or competitive performance to state-of-the-art and outperform a variety of baseline uni-modal and classical multimodal methods.