 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCLARE: Cognitive Load Assessment in REaltime with Multimodal Data
Apr 26, 2024



We present a novel multimodal dataset for Cognitive Load Assessment in REaltime (CLARE). The dataset contains physiological and gaze data from 24 participants with self-reported cognitive load scores as ground-truth labels. The dataset consists of four modalities, namely, Electrocardiography (ECG), Electrodermal Activity (EDA), Electroencephalogram (EEG), and Gaze tracking. To map diverse levels of mental load on participants during experiments, each participant completed four nine-minutes sessions on a computer-based operator performance and mental workload task (the MATB-II software) with varying levels of complexity in one minute segments. During the experiment, participants reported their cognitive load every 10 seconds. For the dataset, we also provide benchmark binary classification results with machine learning and deep learning models on two different evaluation schemes, namely, 10-fold and leave-one-subject-out (LOSO) cross-validation. Benchmark results show that for 10-fold evaluation, the convolutional neural network (CNN) based deep learning model achieves the best classification performance with ECG, EDA, and Gaze. In contrast, for LOSO, the best performance is achieved by the deep learning model with ECG, EDA, and EEG.
Multimodal Brain-Computer Interface for In-Vehicle Driver Cognitive Load Measurement: Dataset and Baselines
Apr 09, 2023

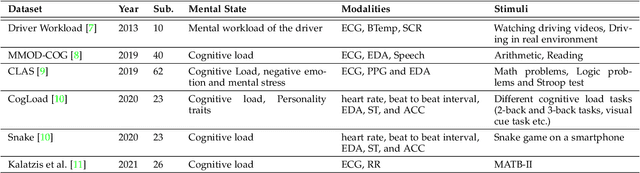
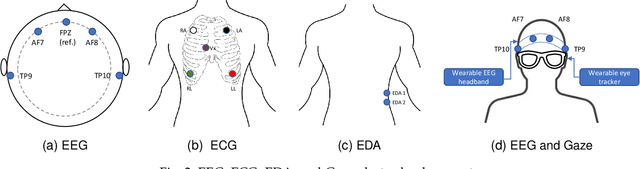
Through this paper, we introduce a novel driver cognitive load assessment dataset, CL-Drive, which contains Electroencephalogram (EEG) signals along with other physiological signals such as Electrocardiography (ECG) and Electrodermal Activity (EDA) as well as eye tracking data. The data was collected from 21 subjects while driving in an immersive vehicle simulator, in various driving conditions, to induce different levels of cognitive load in the subjects. The tasks consisted of 9 complexity levels for 3 minutes each. Each driver reported their subjective cognitive load every 10 seconds throughout the experiment. The dataset contains the subjective cognitive load recorded as ground truth. In this paper, we also provide benchmark classification results for different machine learning and deep learning models for both binary and ternary label distributions. We followed 2 evaluation criteria namely 10-fold and leave-one-subject-out (LOSO). We have trained our models on both hand-crafted features as well as on raw data.
AttX: Attentive Cross-Connections for Fusion of Wearable Signals in Emotion Recognition
Jun 09, 2022
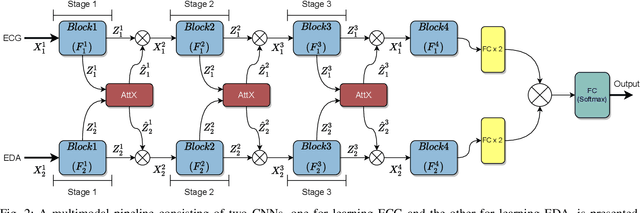


We propose cross-modal attentive connections, a new dynamic and effective technique for multimodal representation learning from wearable data. Our solution can be integrated into any stage of the pipeline, i.e., after any convolutional layer or block, to create intermediate connections between individual streams responsible for processing each modality. Additionally, our method benefits from two properties. First, it can share information uni-directionally (from one modality to the other) or bi-directionally. Second, it can be integrated into multiple stages at the same time to further allow network gradients to be exchanged in several touch-points. We perform extensive experiments on three public multimodal wearable datasets, WESAD, SWELL-KW, and CASE, and demonstrate that our method can effectively regulate and share information between different modalities to learn better representations. Our experiments further demonstrate that once integrated into simple CNN-based multimodal solutions (2, 3, or 4 modalities), our method can result in superior or competitive performance to state-of-the-art and outperform a variety of baseline uni-modal and classical multimodal methods.
A Transformer Architecture for Stress Detection from ECG
Aug 22, 2021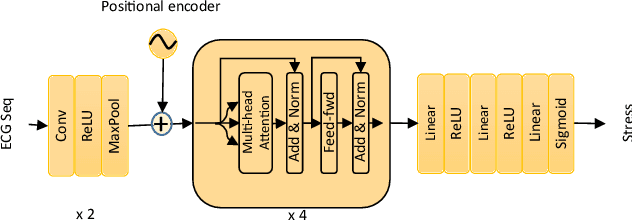
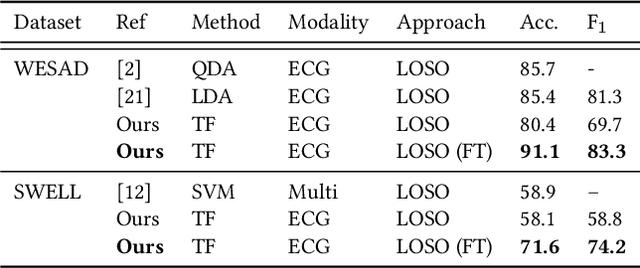
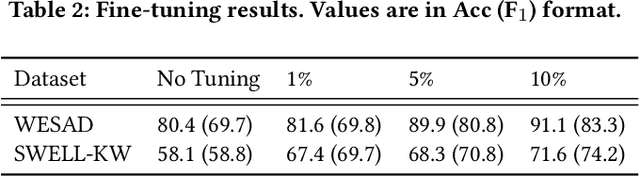
Electrocardiogram (ECG) has been widely used for emotion recognition. This paper presents a deep neural network based on convolutional layers and a transformer mechanism to detect stress using ECG signals. We perform leave-one-subject-out experiments on two publicly available datasets, WESAD and SWELL-KW, to evaluate our method. Our experiments show that the proposed model achieves strong results, comparable or better than the state-of-the-art models for ECG-based stress detection on these two datasets. Moreover, our method is end-to-end, does not require handcrafted features, and can learn robust representations with only a few convolutional blocks and the transformer component.
Attentive Cross-modal Connections for Deep Multimodal Wearable-based Emotion Recognition
Aug 04, 2021
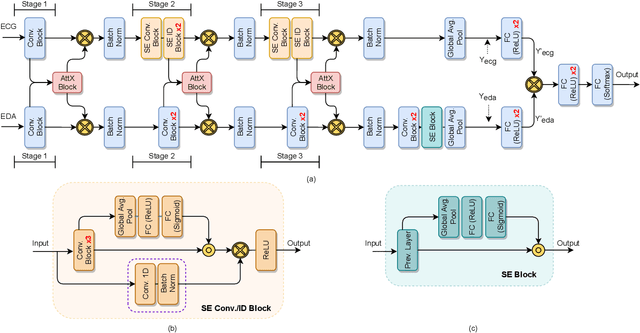
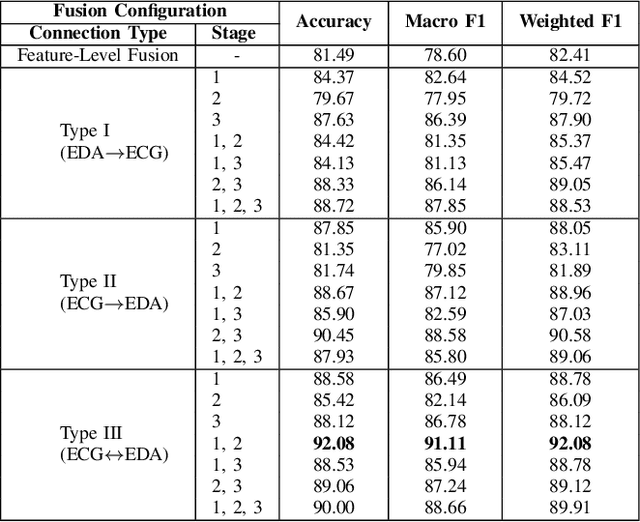

Classification of human emotions can play an essential role in the design and improvement of human-machine systems. While individual biological signals such as Electrocardiogram (ECG) and Electrodermal Activity (EDA) have been widely used for emotion recognition with machine learning methods, multimodal approaches generally fuse extracted features or final classification/regression results to boost performance. To enhance multimodal learning, we present a novel attentive cross-modal connection to share information between convolutional neural networks responsible for learning individual modalities. Specifically, these connections improve emotion classification by sharing intermediate representations among EDA and ECG and apply attention weights to the shared information, thus learning more effective multimodal embeddings. We perform experiments on the WESAD dataset to identify the best configuration of the proposed method for emotion classification. Our experiments show that the proposed approach is capable of learning strong multimodal representations and outperforms a number of baselines methods.