 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCLARE: Cognitive Load Assessment in REaltime with Multimodal Data
Apr 26, 2024



We present a novel multimodal dataset for Cognitive Load Assessment in REaltime (CLARE). The dataset contains physiological and gaze data from 24 participants with self-reported cognitive load scores as ground-truth labels. The dataset consists of four modalities, namely, Electrocardiography (ECG), Electrodermal Activity (EDA), Electroencephalogram (EEG), and Gaze tracking. To map diverse levels of mental load on participants during experiments, each participant completed four nine-minutes sessions on a computer-based operator performance and mental workload task (the MATB-II software) with varying levels of complexity in one minute segments. During the experiment, participants reported their cognitive load every 10 seconds. For the dataset, we also provide benchmark binary classification results with machine learning and deep learning models on two different evaluation schemes, namely, 10-fold and leave-one-subject-out (LOSO) cross-validation. Benchmark results show that for 10-fold evaluation, the convolutional neural network (CNN) based deep learning model achieves the best classification performance with ECG, EDA, and Gaze. In contrast, for LOSO, the best performance is achieved by the deep learning model with ECG, EDA, and EEG.
Multimodal Brain-Computer Interface for In-Vehicle Driver Cognitive Load Measurement: Dataset and Baselines
Apr 09, 2023

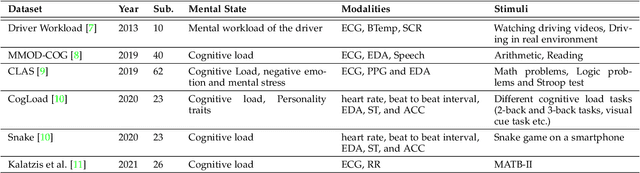
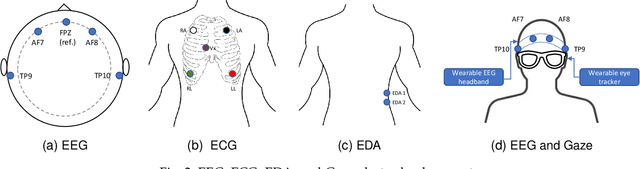
Through this paper, we introduce a novel driver cognitive load assessment dataset, CL-Drive, which contains Electroencephalogram (EEG) signals along with other physiological signals such as Electrocardiography (ECG) and Electrodermal Activity (EDA) as well as eye tracking data. The data was collected from 21 subjects while driving in an immersive vehicle simulator, in various driving conditions, to induce different levels of cognitive load in the subjects. The tasks consisted of 9 complexity levels for 3 minutes each. Each driver reported their subjective cognitive load every 10 seconds throughout the experiment. The dataset contains the subjective cognitive load recorded as ground truth. In this paper, we also provide benchmark classification results for different machine learning and deep learning models for both binary and ternary label distributions. We followed 2 evaluation criteria namely 10-fold and leave-one-subject-out (LOSO). We have trained our models on both hand-crafted features as well as on raw data.
Multistream Gaze Estimation with Anatomical Eye Region Isolation by Synthetic to Real Transfer Learning
Jun 18, 2022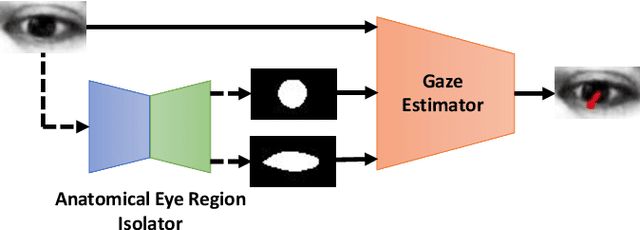
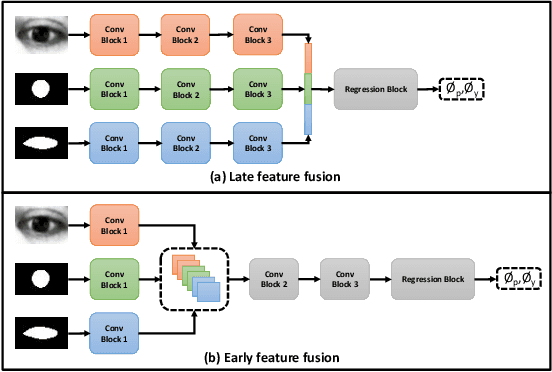
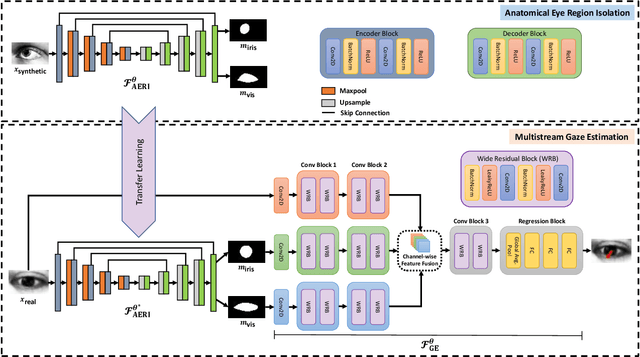
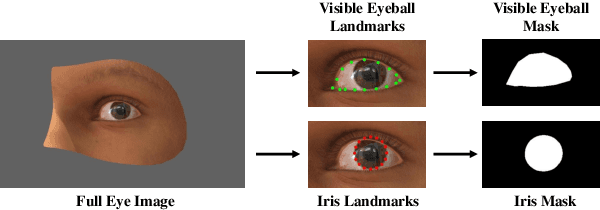
We propose a novel neural pipeline, MSGazeNet, that learns gaze representations by taking advantage of the eye anatomy information through a multistream framework. Our proposed solution comprises two components, first a network for isolating anatomical eye regions, and a second network for multistream gaze estimation. The eye region isolation is performed with a U-Net style network which we train using a synthetic dataset that contains eye region masks for the visible eyeball and the iris region. The synthetic dataset used in this stage is a new dataset consisting of 60,000 eye images, which we create using an eye-gaze simulator, UnityEyes. Successive to training, the eye region isolation network is then transferred to the real domain for generating masks for the real-world eye images. In order to successfully make the transfer, we exploit domain randomization in the training process, which allows for the synthetic images to benefit from a larger variance with the help of augmentations that resemble artifacts. The generated eye region masks along with the raw eye images are then used together as a multistream input to our gaze estimation network. We evaluate our framework on three benchmark gaze estimation datasets, MPIIGaze, Eyediap, and UTMultiview, where we set a new state-of-the-art on Eyediap and UTMultiview datasets by obtaining a performance gain of 7.57% and 1.85% respectively, while achieving competitive performance on MPIIGaze. We also study the robustness of our method with respect to the noise in the data and demonstrate that our model is less sensitive to noisy data. Lastly, we perform a variety of experiments including ablation studies to evaluate the contribution of different components and design choices in our solution.
Gaze Estimation with Eye Region Segmentation and Self-Supervised Multistream Learning
Dec 15, 2021
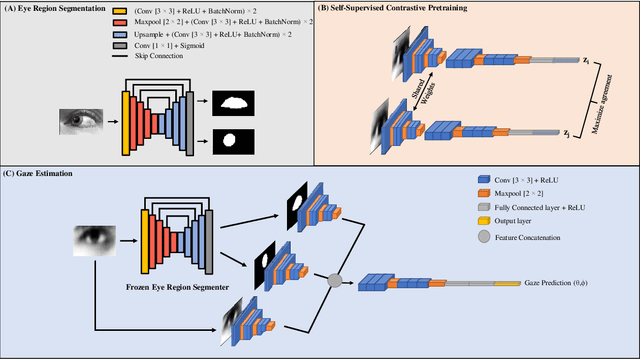


We present a novel multistream network that learns robust eye representations for gaze estimation. We first create a synthetic dataset containing eye region masks detailing the visible eyeball and iris using a simulator. We then perform eye region segmentation with a U-Net type model which we later use to generate eye region masks for real-world eye images. Next, we pretrain an eye image encoder in the real domain with self-supervised contrastive learning to learn generalized eye representations. Finally, this pretrained eye encoder, along with two additional encoders for visible eyeball region and iris, are used in parallel in our multistream framework to extract salient features for gaze estimation from real-world images. We demonstrate the performance of our method on the EYEDIAP dataset in two different evaluation settings and achieve state-of-the-art results, outperforming all the existing benchmarks on this dataset. We also conduct additional experiments to validate the robustness of our self-supervised network with respect to different amounts of labeled data used for training.