 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRepresentation Based Complexity Measures for Predicting Generalization in Deep Learning
Dec 04, 2020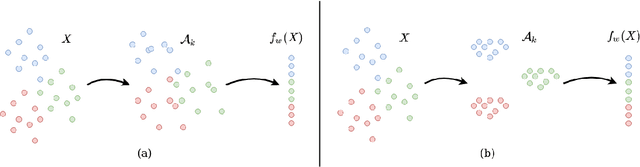
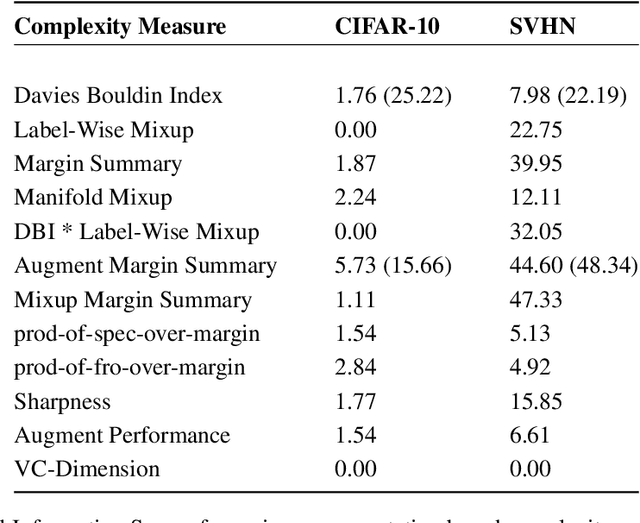
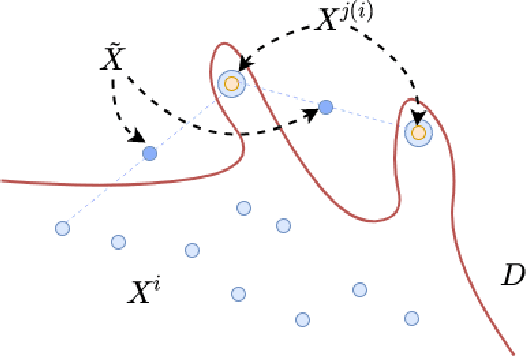
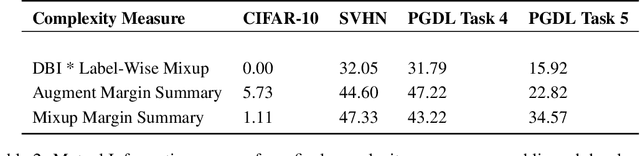
Deep Neural Networks can generalize despite being significantly overparametrized. Recent research has tried to examine this phenomenon from various view points and to provide bounds on the generalization error or measures predictive of the generalization gap based on these viewpoints, such as norm-based, PAC-Bayes based, and margin-based analysis. In this work, we provide an interpretation of generalization from the perspective of quality of internal representations of deep neural networks, based on neuroscientific theories of how the human visual system creates invariant and untangled object representations. Instead of providing theoretical bounds, we demonstrate practical complexity measures which can be computed ad-hoc to uncover generalization behaviour in deep models. We also provide a detailed description of our solution that won the NeurIPS competition on Predicting Generalization in Deep Learning held at NeurIPS 2020. An implementation of our solution is available at https://github.com/parthnatekar/pgdl.
Abstracting Deep Neural Networks into Concept Graphs for Concept Level Interpretability
Aug 14, 2020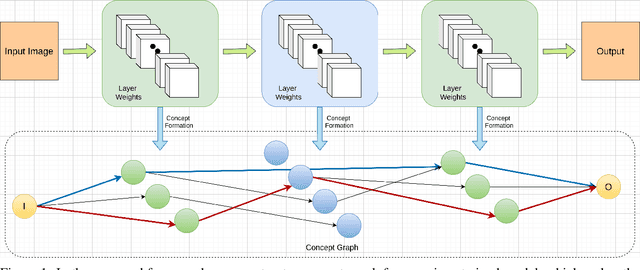

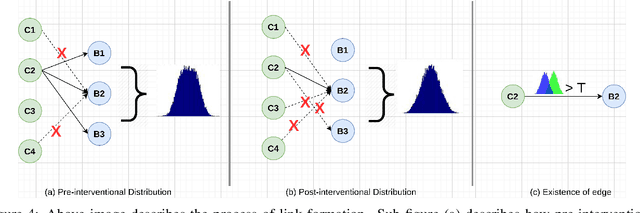
The black-box nature of deep learning models prevents them from being completely trusted in domains like biomedicine. Most explainability techniques do not capture the concept-based reasoning that human beings follow. In this work, we attempt to understand the behavior of trained models that perform image processing tasks in the medical domain by building a graphical representation of the concepts they learn. Extracting such a graphical representation of the model's behavior on an abstract, higher conceptual level would unravel the learnings of these models and would help us to evaluate the steps taken by the model for predictions. We show the application of our proposed implementation on two biomedical problems - brain tumor segmentation and fundus image classification. We provide an alternative graphical representation of the model by formulating a \textit{concept level graph} as discussed above, which makes the problem of intervention to find active inference trails more tractable. Understanding these trails would provide an understanding of the hierarchy of the decision-making process followed by the model. [As well as overall nature of model]. Our framework is available at \url{https://github.com/koriavinash1/BioExp}
Demystifying Brain Tumour Segmentation Networks: Interpretability and Uncertainty Analysis
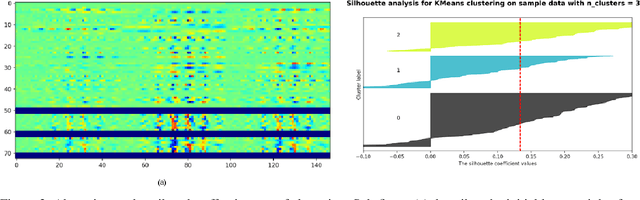
Sep 05, 2019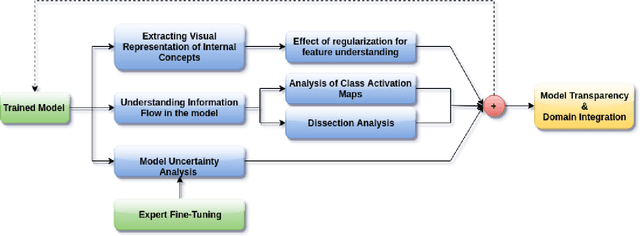
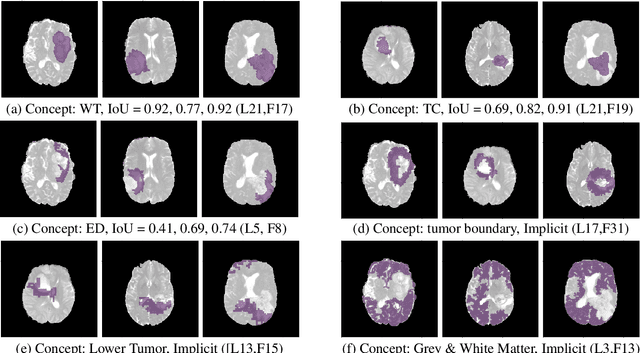
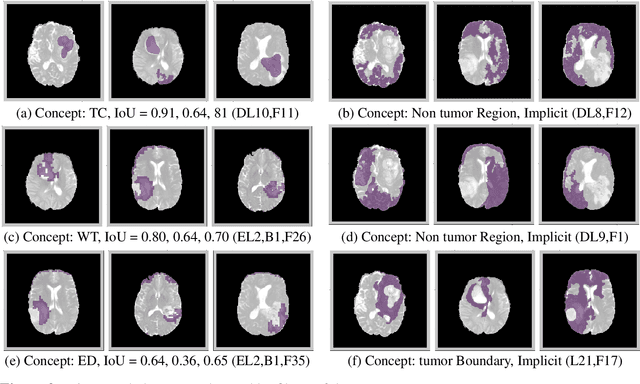
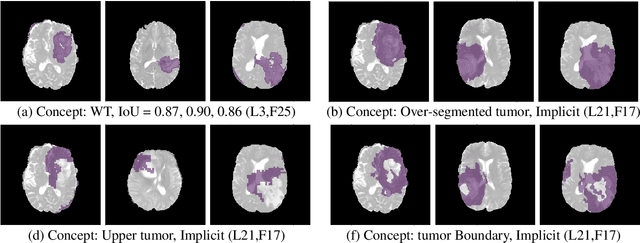
The accurate automatic segmentation of gliomas and its intra-tumoral structures is important not only for treatment planning but also for follow-up evaluations. Several methods based on 2D and 3D Deep Neural Networks (DNN) have been developed to segment brain tumors and to classify different categories of tumors from different MRI modalities. However, these networks are often black-box models and do not provide any evidence regarding the process they take to perform this task. Increasing transparency and interpretability of such deep learning techniques are necessary for the complete integration of such methods into medical practice. In this paper, we explore various techniques to explain the functional organization of brain tumor segmentation models and to extract visualizations of internal concepts to understand how these networks achieve highly accurate tumor segmentations. We use the BraTS 2018 dataset to train three different networks with standard architectures and outline similarities and differences in the process that these networks take to segment brain tumors. We show that brain tumor segmentation networks learn certain human-understandable disentangled concepts on a filter level. We also show that they take a top-down or hierarchical approach to localizing the different parts of the tumor. We then extract visualizations of some internal feature maps and also provide a measure of uncertainty with regards to the outputs of the models to give additional qualitative evidence about the predictions of these networks. We believe that the emergence of such human-understandable organization and concepts might aid in the acceptance and integration of such methods in medical diagnosis.