 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRepresentation Based Complexity Measures for Predicting Generalization in Deep Learning
Dec 04, 2020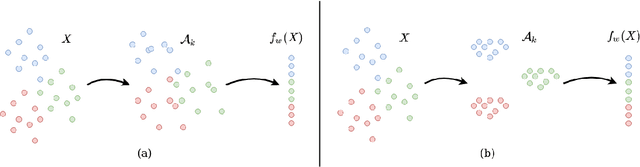
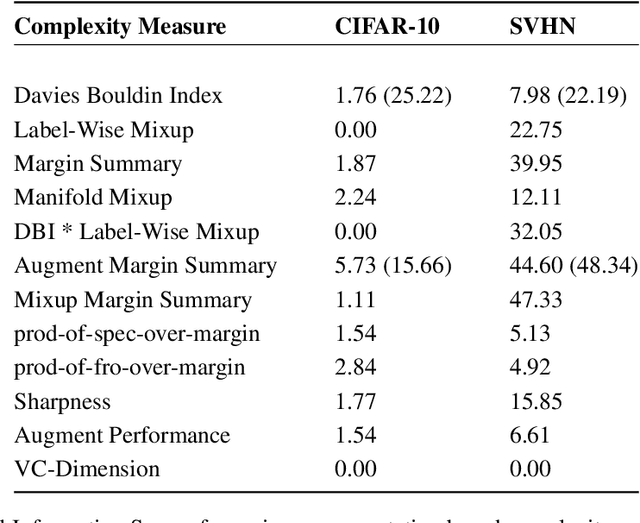
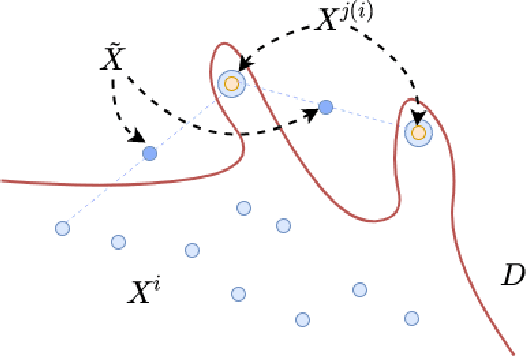
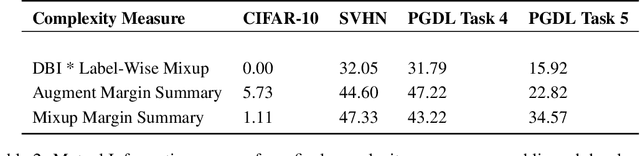
Deep Neural Networks can generalize despite being significantly overparametrized. Recent research has tried to examine this phenomenon from various view points and to provide bounds on the generalization error or measures predictive of the generalization gap based on these viewpoints, such as norm-based, PAC-Bayes based, and margin-based analysis. In this work, we provide an interpretation of generalization from the perspective of quality of internal representations of deep neural networks, based on neuroscientific theories of how the human visual system creates invariant and untangled object representations. Instead of providing theoretical bounds, we demonstrate practical complexity measures which can be computed ad-hoc to uncover generalization behaviour in deep models. We also provide a detailed description of our solution that won the NeurIPS competition on Predicting Generalization in Deep Learning held at NeurIPS 2020. An implementation of our solution is available at https://github.com/parthnatekar/pgdl.
Distangling Biological Noise in Cellular Images with a focus on Explainability
Jul 11, 2020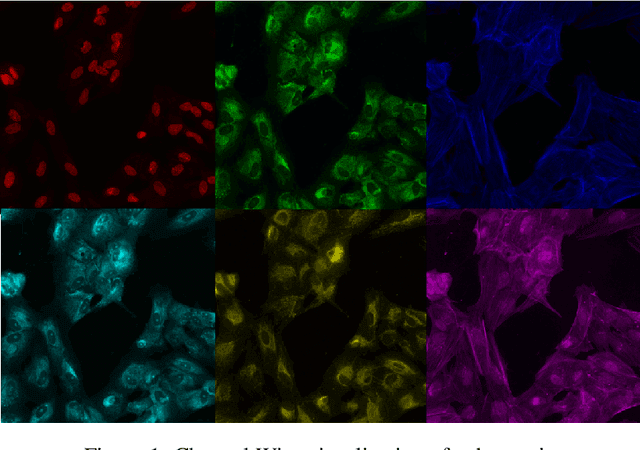
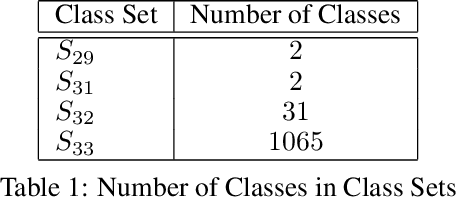
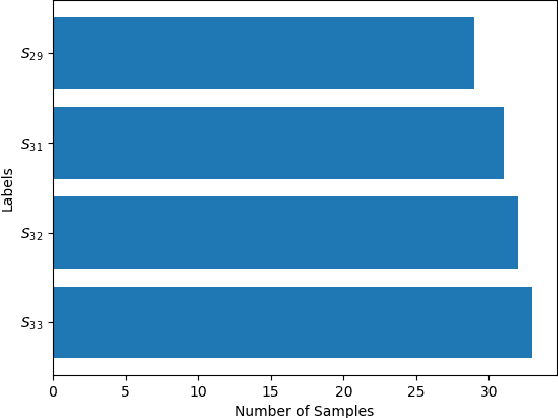
The cost of some drugs and medical treatments has risen in recent years that many patients are having to go without. A classification project could make researchers more efficient. One of the more surprising reasons behind the cost is how long it takes to bring new treatments to market. Despite improvements in technology and science, research and development continues to lag. In fact, finding new treatment takes, on average, more than 10 years and costs hundreds of millions of dollars. In turn, greatly decreasing the cost of treatments can make ensure these treatments get to patients faster. This work aims at solving a part of this problem by creating a cellular image classification model which can decipher the genetic perturbations in cell (occurring naturally or artificially). Another interesting question addressed is what makes the deep-learning model decide in a particular fashion, which can further help in demystifying the mechanism of action of certain perturbations and paves a way towards the explainability of the deep-learning model. We show the results of Grad-CAM visualizations and make a case for the significance of certain features over others. Further we discuss how these significant features are pivotal in extracting useful diagnostic information from the deep-learning model.
Dynamic Regularizer with an Informative Prior
Oct 31, 2019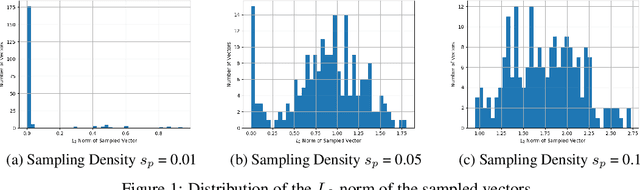

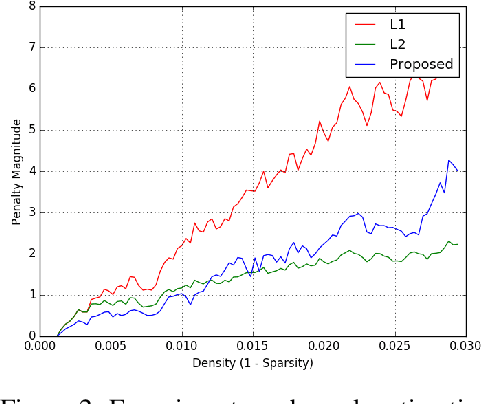
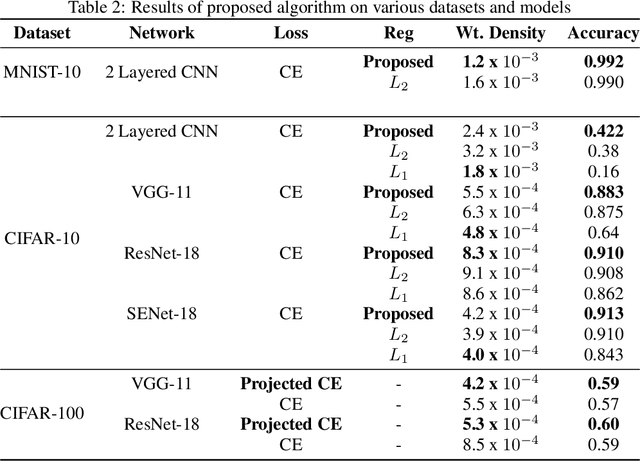
Regularization methods, specifically those which directly alter weights like $L_1$ and $L_2$, are an integral part of many learning algorithms. Both the regularizers mentioned above are formulated by assuming certain priors in the parameter space and these assumptions, in some cases, induce sparsity in the parameter space. Regularizers help in transferring beliefs one has on the dataset or the parameter space by introducing adequate terms in the loss function. Any kind of formulation represents a specific set of beliefs: $L_1$ regularization conveys that the parameter space should be sparse whereas $L_2$ regularization conveys that the parameter space should be bounded and continuous. These regularizers in turn leverage certain priors to express these inherent beliefs. A better understanding of how the prior affects the behavior of the parameters and how the priors can be updated based on the dataset can contribute greatly in improving the generalization capabilities of a function estimator. In this work, we introduce a weakly informative prior and then further extend it to an informative prior in order to formulate a regularization penalty, which shows better results in terms of inducing sparsity experimentally, when compared to regularizers based only on Gaussian and Laplacian priors. Experimentally, we verify that a regularizer based on an adapted prior improves the generalization capabilities of any network. We illustrate the performance of the proposed method on the MNIST and CIFAR-10 datasets.