 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning associations between clinical information and motion-based descriptors using a large scale MR-derived cardiac motion atlas
Jul 27, 2018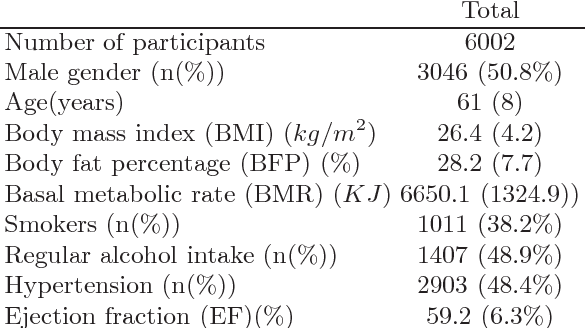
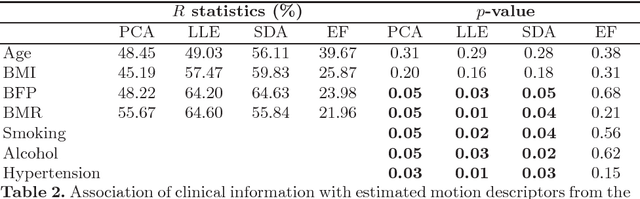
The availability of large scale databases containing imaging and non-imaging data, such as the UK Biobank, represents an opportunity to improve our understanding of healthy and diseased bodily function. Cardiac motion atlases provide a space of reference in which the motion fields of a cohort of subjects can be directly compared. In this work, a cardiac motion atlas is built from cine MR data from the UK Biobank (~ 6000 subjects). Two automated quality control strategies are proposed to reject subjects with insufficient image quality. Based on the atlas, three dimensionality reduction algorithms are evaluated to learn data-driven cardiac motion descriptors, and statistical methods used to study the association between these descriptors and non-imaging data. Results show a positive correlation between the atlas motion descriptors and body fat percentage, basal metabolic rate, hypertension, smoking status and alcohol intake frequency. The proposed method outperforms the ability to identify changes in cardiac function due to these known cardiovascular risk factors compared to ejection fraction, the most commonly used descriptor of cardiac function. In conclusion, this work represents a framework for further investigation of the factors influencing cardiac health.
Boosting k-NN for categorization of natural scenes
Jan 08, 2010



The k-nearest neighbors (k-NN) classification rule has proven extremely successful in countless many computer vision applications. For example, image categorization often relies on uniform voting among the nearest prototypes in the space of descriptors. In spite of its good properties, the classic k-NN rule suffers from high variance when dealing with sparse prototype datasets in high dimensions. A few techniques have been proposed to improve k-NN classification, which rely on either deforming the nearest neighborhood relationship or modifying the input space. In this paper, we propose a novel boosting algorithm, called UNN (Universal Nearest Neighbors), which induces leveraged k-NN, thus generalizing the classic k-NN rule. We redefine the voting rule as a strong classifier that linearly combines predictions from the k closest prototypes. Weak classifiers are learned by UNN so as to minimize a surrogate risk. A major feature of UNN is the ability to learn which prototypes are the most relevant for a given class, thus allowing one for effective data reduction. Experimental results on the synthetic two-class dataset of Ripley show that such a filtering strategy is able to reject "noisy" prototypes. We carried out image categorization experiments on a database containing eight classes of natural scenes. We show that our method outperforms significantly the classic k-NN classification, while enabling significant reduction of the computational cost by means of data filtering.