 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Koopman-Based Generalization Bounds for Multi-Task Deep Learning
Dec 22, 2025The paper establishes generalization bounds for multitask deep neural networks using operator-theoretic techniques. The authors propose a tighter bound than those derived from conventional norm based methods by leveraging small condition numbers in the weight matrices and introducing a tailored Sobolev space as an expanded hypothesis space. This enhanced bound remains valid even in single output settings, outperforming existing Koopman based bounds. The resulting framework maintains key advantages such as flexibility and independence from network width, offering a more precise theoretical understanding of multitask deep learning in the context of kernel methods.
Operator-Based Generalization Bound for Deep Learning: Insights on Multi-Task Learning
Dec 22, 2025This paper presents novel generalization bounds for vector-valued neural networks and deep kernel methods, focusing on multi-task learning through an operator-theoretic framework. Our key development lies in strategically combining a Koopman based approach with existing techniques, achieving tighter generalization guarantees compared to traditional norm-based bounds. To mitigate computational challenges associated with Koopman-based methods, we introduce sketching techniques applicable to vector valued neural networks. These techniques yield excess risk bounds under generic Lipschitz losses, providing performance guarantees for applications including robust and multiple quantile regression. Furthermore, we propose a novel deep learning framework, deep vector-valued reproducing kernel Hilbert spaces (vvRKHS), leveraging Perron Frobenius (PF) operators to enhance deep kernel methods. We derive a new Rademacher generalization bound for this framework, explicitly addressing underfitting and overfitting through kernel refinement strategies. This work offers novel insights into the generalization properties of multitask learning with deep learning architectures, an area that has been relatively unexplored until recent developments.
Multi-Task Learning Based on Support Vector Machines and Twin Support Vector Machines: A Comprehensive Survey
Oct 30, 2025Multi-task learning (MTL) enables simultaneous training across related tasks, leveraging shared information to improve generalization, efficiency, and robustness, especially in data-scarce or high-dimensional scenarios. While deep learning dominates recent MTL research, Support Vector Machines (SVMs) and Twin SVMs (TWSVMs) remain relevant due to their interpretability, theoretical rigor, and effectiveness with small datasets. This chapter surveys MTL approaches based on SVM and TWSVM, highlighting shared representations, task regularization, and structural coupling strategies. Special attention is given to emerging TWSVM extensions for multi-task settings, which show promise but remain underexplored. We compare these models in terms of theoretical properties, optimization strategies, and empirical performance, and discuss applications in fields such as computer vision, natural language processing, and bioinformatics. Finally, we identify research gaps and outline future directions for building scalable, interpretable, and reliable margin-based MTL frameworks. This work provides a comprehensive resource for researchers and practitioners interested in SVM- and TWSVM-based multi-task learning.
A Brief Review of Explainable Artificial Intelligence in Healthcare
Apr 04, 2023



XAI refers to the techniques and methods for building AI applications which assist end users to interpret output and predictions of AI models. Black box AI applications in high-stakes decision-making situations, such as medical domain have increased the demand for transparency and explainability since wrong predictions may have severe consequences. Model explainability and interpretability are vital successful deployment of AI models in healthcare practices. AI applications' underlying reasoning needs to be transparent to clinicians in order to gain their trust. This paper presents a systematic review of XAI aspects and challenges in the healthcare domain. The primary goals of this study are to review various XAI methods, their challenges, and related machine learning models in healthcare. The methods are discussed under six categories: Features-oriented methods, global methods, concept models, surrogate models, local pixel-based methods, and human-centric methods. Most importantly, the paper explores XAI role in healthcare problems to clarify its necessity in safety-critical applications. The paper intends to establish a comprehensive understanding of XAI-related applications in the healthcare field by reviewing the related experimental results. To facilitate future research for filling research gaps, the importance of XAI models from different viewpoints and their limitations are investigated.
Homography augumented momentum constrastive learning for SAR image retrieval
Sep 21, 2021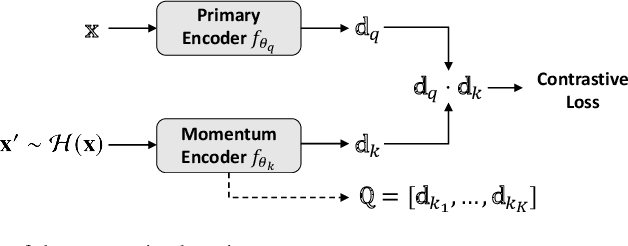
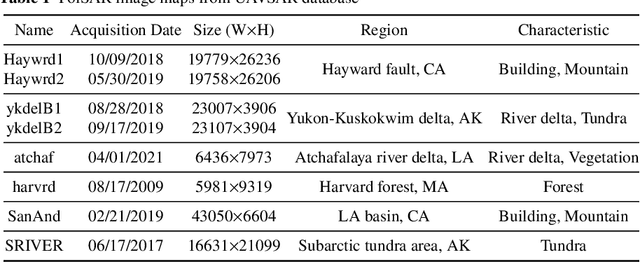
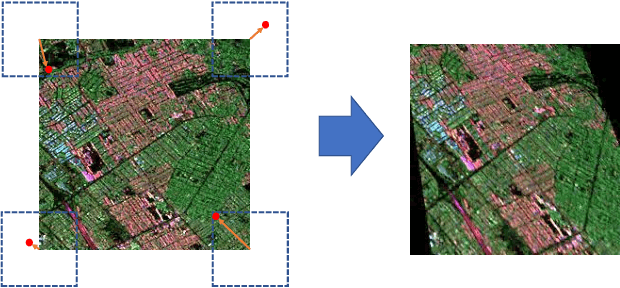
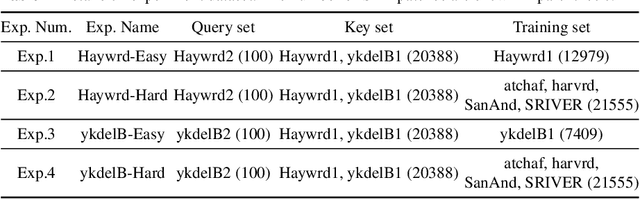
Deep learning-based image retrieval has been emphasized in computer vision. Representation embedding extracted by deep neural networks (DNNs) not only aims at containing semantic information of the image, but also can manage large-scale image retrieval tasks. In this work, we propose a deep learning-based image retrieval approach using homography transformation augmented contrastive learning to perform large-scale synthetic aperture radar (SAR) image search tasks. Moreover, we propose a training method for the DNNs induced by contrastive learning that does not require any labeling procedure. This may enable tractability of large-scale datasets with relative ease. Finally, we verify the performance of the proposed method by conducting experiments on the polarimetric SAR image datasets.
Deep Data Density Estimation through Donsker-Varadhan Representation
Apr 14, 2021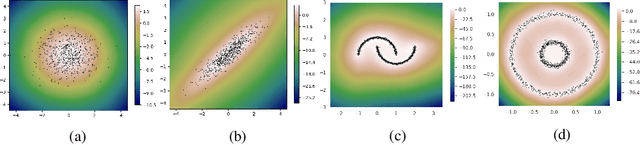

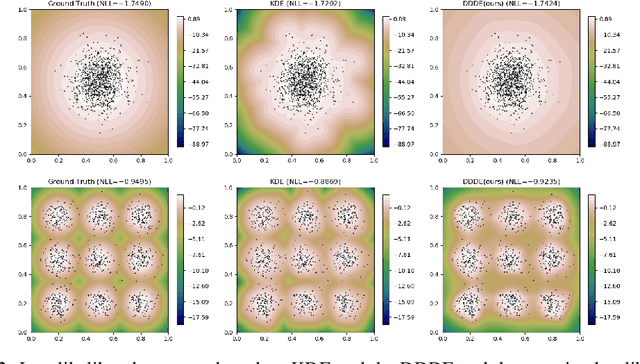

Estimating the data density is one of the challenging problems in deep learning. In this paper, we present a simple yet effective method for estimating the data density using a deep neural network and the Donsker-Varadhan variational lower bound on the KL divergence. We show that the optimal critic function associated with the Donsker-Varadhan representation on the KL divergence between the data and the uniform distribution can estimate the data density. We also present the deep neural network-based modeling and its stochastic learning. The experimental results and possible applications of the proposed method demonstrate that it is competitive with the previous methods and has a lot of possibilities in applied to various applications.
Interpreting Rate-Distortion of Variational Autoencoder and Using Model Uncertainty for Anomaly Detection
May 07, 2020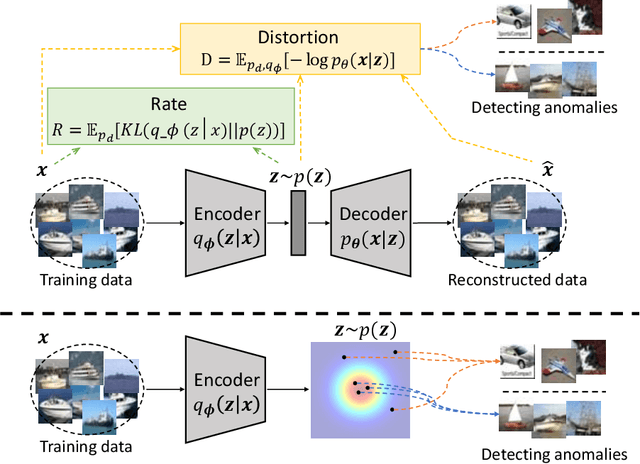
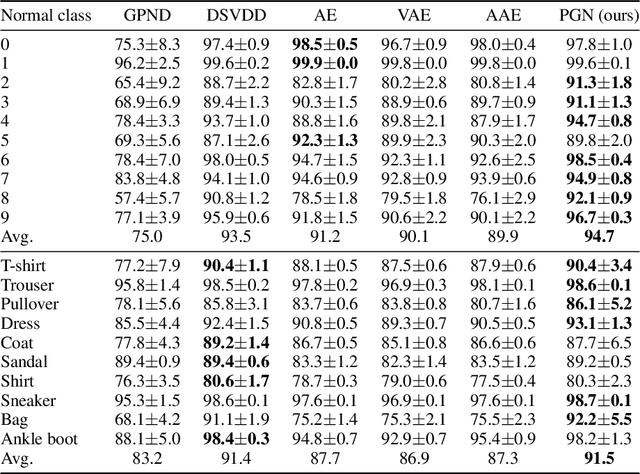
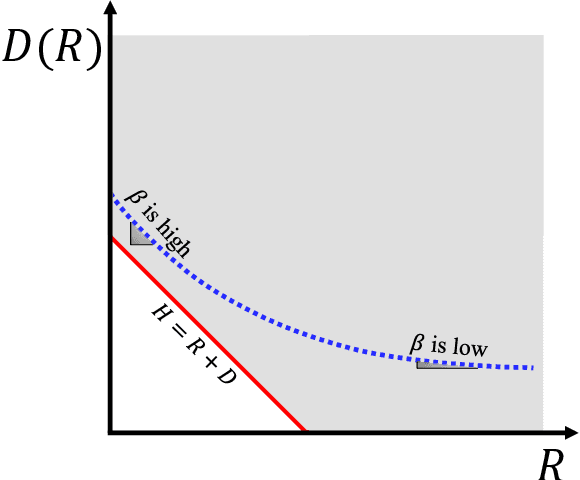

Building a scalable machine learning system for unsupervised anomaly detection via representation learning is highly desirable. One of the prevalent methods is using a reconstruction error from variational autoencoder (VAE) via maximizing the evidence lower bound. We revisit VAE from the perspective of information theory to provide some theoretical foundations on using the reconstruction error, and finally arrive at a simpler and more effective model for anomaly detection. In addition, to enhance the effectiveness of detecting anomalies, we incorporate a practical model uncertainty measure into the metric. We show empirically the competitive performance of our approach on benchmark datasets.
Combining Stochastic Adaptive Cubic Regularization with Negative Curvature for Nonconvex Optimization
Jun 27, 2019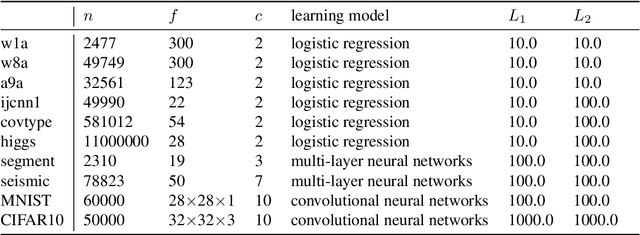


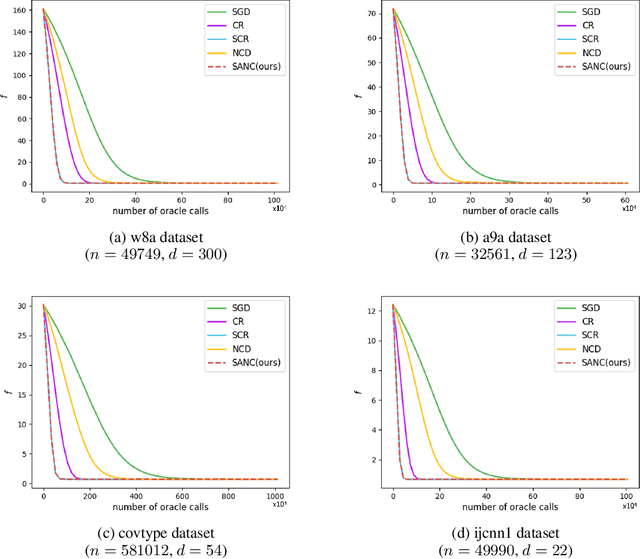
We focus on minimizing nonconvex finite-sum functions that typically arise in machine learning problems. In an attempt to solve this problem, the adaptive cubic regularized Newton method has shown its strong global convergence guarantees and ability to escape from strict saddle points. This method uses a trust region-like scheme to determine if an iteration is successful or not, and updates only when it is successful. In this paper, we suggest an algorithm combining negative curvature with the adaptive cubic regularized Newton method to update even at unsuccessful iterations. We call this new method Stochastic Adaptive cubic regularization with Negative Curvature (SANC). Unlike the previous method, in order to attain stochastic gradient and Hessian estimators, the SANC algorithm uses independent sets of data points of consistent size over all iterations. It makes the SANC algorithm more practical to apply for solving large-scale machine learning problems. To the best of our knowledge, this is the first approach that combines the negative curvature method with the adaptive cubic regularized Newton method. Finally, we provide experimental results including neural networks problems supporting the efficiency of our method.
Extended Vertical Lists for Temporal Pattern Mining from Multivariate Time Series
Apr 26, 2018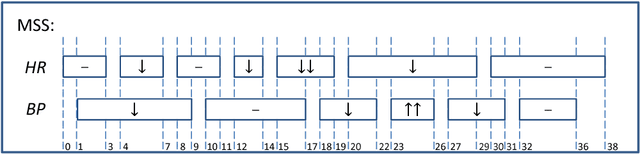
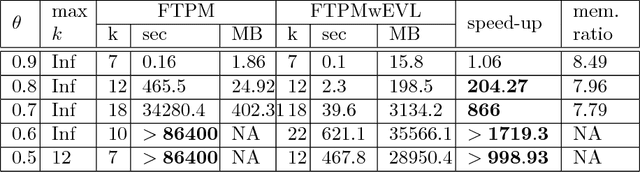
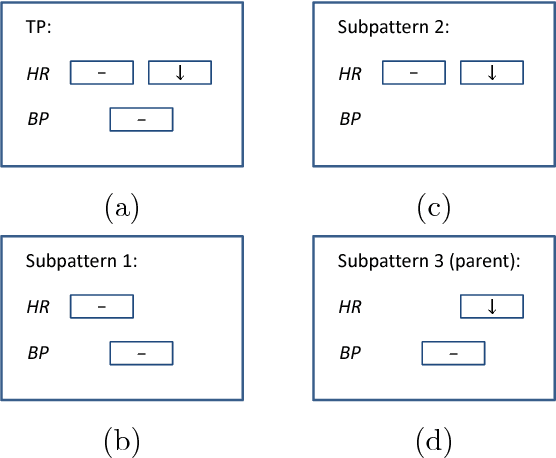
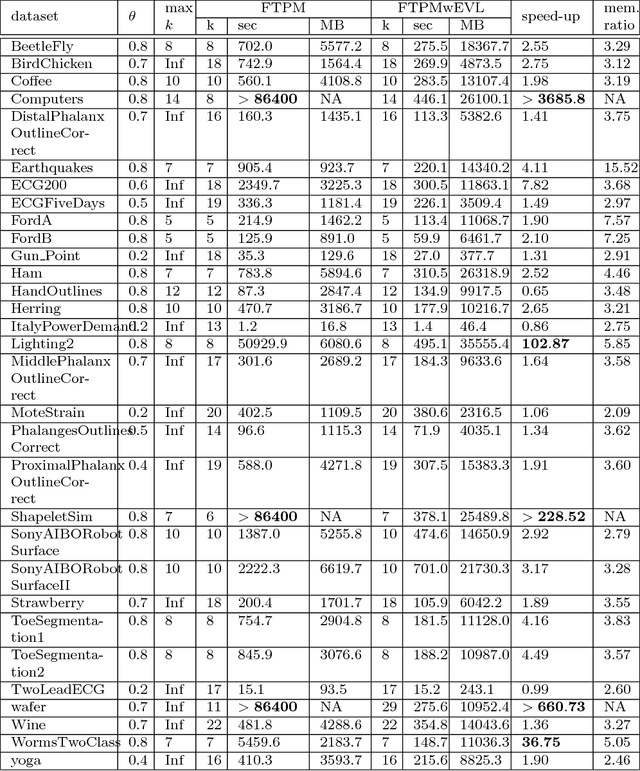
Temporal Pattern Mining (TPM) is the problem of mining predictive complex temporal patterns from multivariate time series in a supervised setting. We develop a new method called the Fast Temporal Pattern Mining with Extended Vertical Lists. This method utilizes an extension of the Apriori property which requires a more complex pattern to appear within records only at places where all of its subpatterns are detected as well. The approach is based on a novel data structure called the Extended Vertical List that tracks positions of the first state of the pattern inside records. Extensive computational results indicate that the new method performs significantly faster than the previous version of the algorithm for TMP. However, the speed-up comes at the expense of memory usage.
Machine Learning Methods for Solving Assignment Problems in Multi-Target Tracking
Feb 19, 2018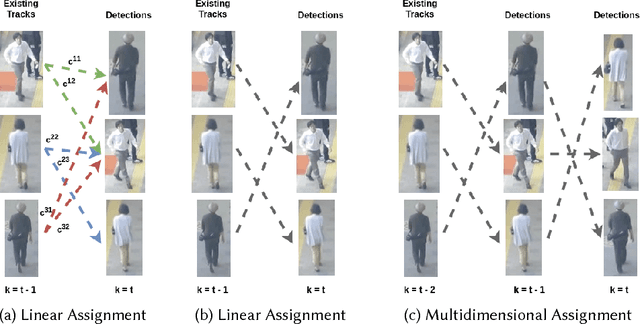

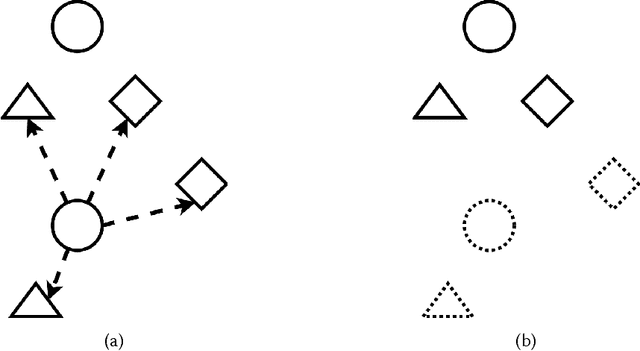
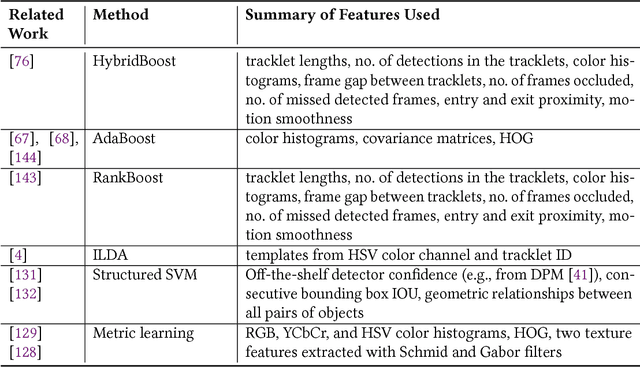
Data association and track-to-track association, two fundamental problems in single-sensor and multi-sensor multi-target tracking, are instances of an NP-hard combinatorial optimization problem known as the multidimensional assignment problem (MDAP). Over the last few years, data-driven approaches to tackling MDAPs in tracking have become increasingly popular. We argue that viewing multi-target tracking as an assignment problem conceptually unifies the wide variety of machine learning methods that have been proposed for data association and track-to-track association. In this survey, we review recent literature, provide rigorous formulations of the assignment problems encountered in multi-target tracking, and review classic approaches used prior to the shift towards data-driven techniques. Recent attempts at using deep learning to solve NP-hard combinatorial optimization problems, including data association, are discussed as well. We highlight representation learning methods for multi-sensor applications and conclude by providing an overview of current multi-target tracking benchmarks.