 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimulation Studies on Deep Reinforcement Learning for Building Control with Human Interaction
Mar 14, 2021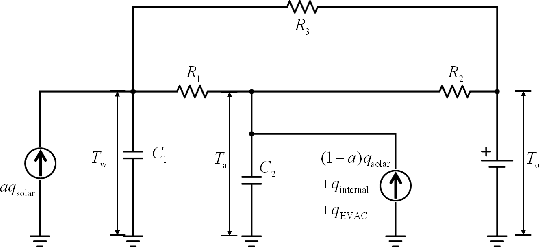
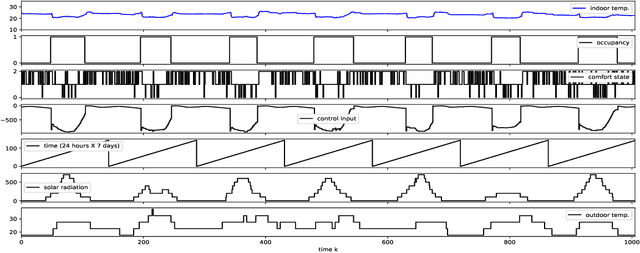

The building sector consumes the largest energy in the world, and there have been considerable research interests in energy consumption and comfort management of buildings. Inspired by recent advances in reinforcement learning (RL), this paper aims at assessing the potential of RL in building climate control problems with occupant interaction. We apply a recent RL approach, called DDPG (deep deterministic policy gradient), for the continuous building control tasks and assess its performance with simulation studies in terms of its ability to handle (a) the partial state observability due to sensor limitations; (b) complex stochastic system with high-dimensional state-spaces, which are jointly continuous and discrete; (c) uncertainties due to ambient weather conditions, occupant's behavior, and comfort feelings. Especially, the partial observability and uncertainty due to the occupant interaction significantly complicate the control problem. Through simulation studies, the policy learned by DDPG demonstrates reasonable performance and computational tractability.
Learning Personalized Thermal Preferences via Bayesian Active Learning with Unimodality Constraints
Apr 01, 2019


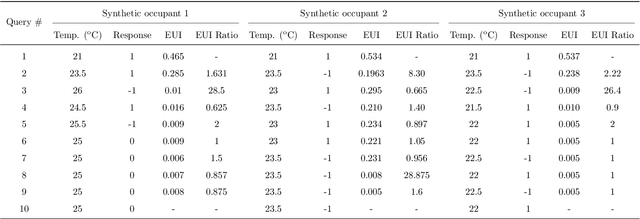
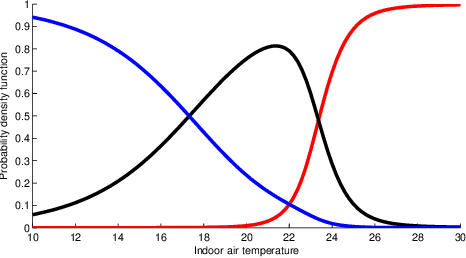
Thermal preferences vary from person to person and may change over time. The main objective of this paper is to sequentially pose intelligent queries to occupants in order to optimally learn the indoor air temperature values which maximize their satisfaction. Our central hypothesis is that an occupant's preference relation over indoor air temperature can be described using a scalar function of these temperatures, which we call the "occupant's thermal utility function". Information about an occupant's preference over these temperatures is available to us through their response to thermal preference queries : "prefer warmer," "prefer cooler" and "satisfied" which we interpret as statements about the derivative of their utility function, i.e. the utility function is "increasing", "decreasing" and "constant" respectively. We model this hidden utility function using a Gaussian process prior with built-in unimodality constraint, i.e., the utility function has a unique maximum, and we train this model using Bayesian inference. This permits an expected improvement based selection of next preference query to pose to the occupant, which takes into account both exploration (sampling from areas of high uncertainty) and exploitation (sampling from areas which are likely to offer an improvement over current best observation). We use this framework to sequentially design experiments and illustrate its benefits by showing that it requires drastically fewer observations to learn the maximally preferred temperature values as compared to other methods. This framework is an important step towards the development of intelligent HVAC systems which would be able to respond to occupants' personalized thermal comfort needs. In order to encourage the use of our PE framework and ensure reproducibility in results, we publish an implementation of our work named GPPrefElicit as an open-source package in Python.