 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Microphone and Multi-Modal Emotion Recognition in Reverbrant Enviroment
Sep 14, 2024


This paper presents a Multi-modal Emotion Recognition (MER) system designed to enhance emotion recognition accuracy in challenging acoustic conditions. Our approach combines a modified and extended Hierarchical Token-semantic Audio Transformer (HTS-AT) for multi-channel audio processing with an R(2+1)D Convolutional Neural Networks (CNN) model for video analysis. We evaluate our proposed method on a reverberated version of the Ryerson audio-visual database of emotional speech and song (RAVDESS) dataset using synthetic and real-world Room Impulse Responsess (RIRs). Our results demonstrate that integrating audio and video modalities yields superior performance compared to uni-modal approaches, especially in challenging acoustic conditions. Moreover, we show that the multimodal (audiovisual) approach that utilizes multiple microphones outperforms its single-microphone counterpart.
Multi-Microphone Speech Emotion Recognition using the Hierarchical Token-semantic Audio Transformer Architecture
Jun 05, 2024



Most emotion recognition systems fail in real-life situations (in the wild scenarios) where the audio is contaminated by reverberation. Our study explores new methods to alleviate the performance degradation of Speech Emotion Recognition (SER) algorithms and develop a more robust system for adverse conditions. We propose processing multi-microphone signals to address these challenges and improve emotion classification accuracy. We adopt a state-of-the-art transformer model, the Hierarchical Token-semantic Audio Transformer (HTS-AT), to handle multi-channel audio inputs. We evaluate two strategies: averaging mel-spectrograms across channels and summing patch-embedded representations. Our multimicrophone model achieves superior performance compared to single-channel baselines when tested on real-world reverberant environments.
Socially Pertinent Robots in Gerontological Healthcare
Apr 11, 2024
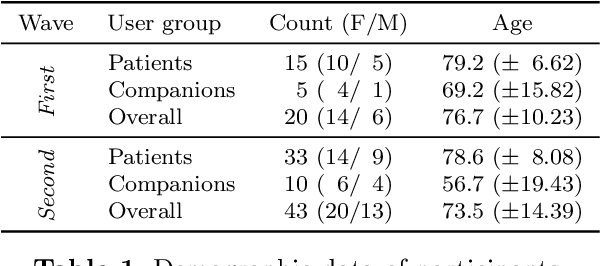
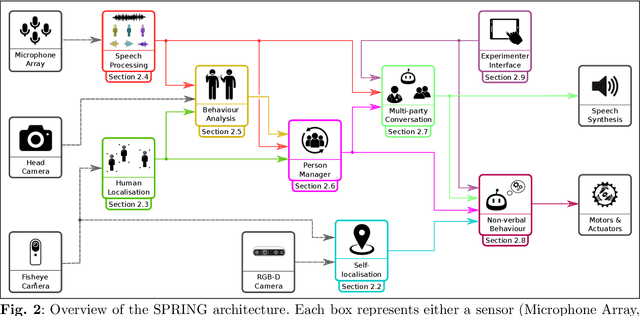
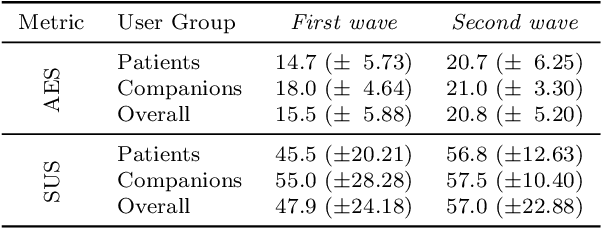
Despite the many recent achievements in developing and deploying social robotics, there are still many underexplored environments and applications for which systematic evaluation of such systems by end-users is necessary. While several robotic platforms have been used in gerontological healthcare, the question of whether or not a social interactive robot with multi-modal conversational capabilities will be useful and accepted in real-life facilities is yet to be answered. This paper is an attempt to partially answer this question, via two waves of experiments with patients and companions in a day-care gerontological facility in Paris with a full-sized humanoid robot endowed with social and conversational interaction capabilities. The software architecture, developed during the H2020 SPRING project, together with the experimental protocol, allowed us to evaluate the acceptability (AES) and usability (SUS) with more than 60 end-users. Overall, the users are receptive to this technology, especially when the robot perception and action skills are robust to environmental clutter and flexible to handle a plethora of different interactions.