 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Systematic Review on Data-Driven Brain Deformation Modeling for Image-Guided Neurosurgery
Feb 09, 2026Accurate compensation of brain deformation is a critical challenge for reliable image-guided neurosurgery, as surgical manipulation and tumor resection induce tissue motion that misaligns preoperative planning images with intraoperative anatomy and longitudinal studies. In this systematic review, we synthesize recent AI-driven approaches developed between January 2020 and April 2025 for modeling and correcting brain deformation. A comprehensive literature search was conducted in PubMed, IEEE Xplore, Scopus, and Web of Science, with predefined inclusion and exclusion criteria focused on computational methods applied to brain deformation compensation for neurosurgical imaging, resulting in 41 studies meeting these criteria. We provide a unified analysis of methodological strategies, including deep learning-based image registration, direct deformation field regression, synthesis-driven multimodal alignment, resection-aware architectures addressing missing correspondences, and hybrid models that integrate biomechanical priors. We also examine dataset utilization, reported evaluation metrics, validation protocols, and how uncertainty and generalization have been assessed across studies. While AI-based deformation models demonstrate promising performance and computational efficiency, current approaches exhibit limitations in out-of-distribution robustness, standardized benchmarking, interpretability, and readiness for clinical deployment. Our review highlights these gaps and outlines opportunities for future research aimed at achieving more robust, generalizable, and clinically translatable deformation compensation solutions for neurosurgical guidance. By organizing recent advances and critically evaluating evaluation practices, this work provides a comprehensive foundation for researchers and clinicians engaged in developing and applying AI-based brain deformation methods.
DMCL: Distillation Multiple Choice Learning for Multimodal Action Recognition
Dec 23, 2019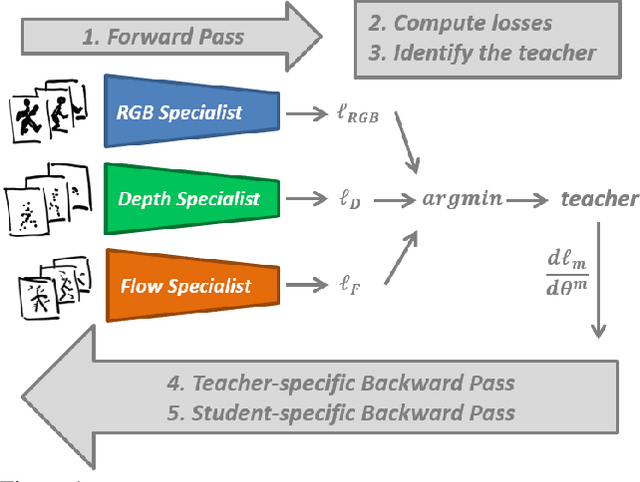
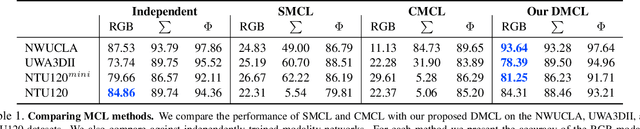
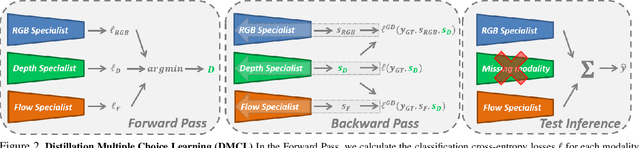

In this work, we address the problem of learning an ensemble of specialist networks using multimodal data, while considering the realistic and challenging scenario of possible missing modalities at test time. Our goal is to leverage the complementary information of multiple modalities to the benefit of the ensemble and each individual network. We introduce a novel Distillation Multiple Choice Learning framework for multimodal data, where different modality networks learn in a cooperative setting from scratch, strengthening one another. The modality networks learned using our method achieve significantly higher accuracy than if trained separately, due to the guidance of other modalities. We evaluate this approach on three video action recognition benchmark datasets. We obtain state-of-the-art results in comparison to other approaches that work with missing modalities at test time.
Learning with privileged information via adversarial discriminative modality distillation
Oct 19, 2018

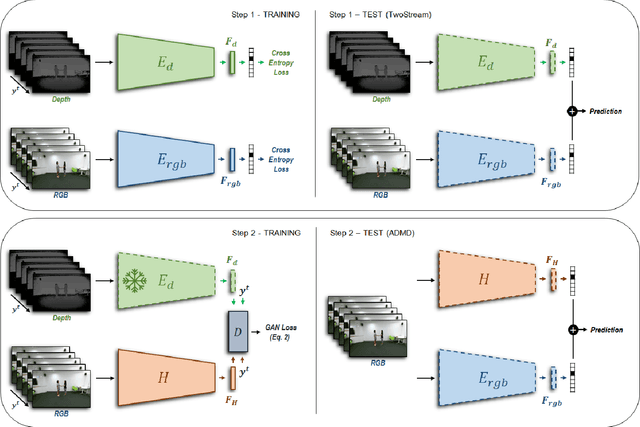

Heterogeneous data modalities can provide complementary cues for several tasks, usually leading to more robust algorithms and better performance. However, while training data can be accurately collected to include a variety of sensory modalities, it is often the case that not all of them are available in real life (testing) scenarios, where a model has to be deployed. This raises the challenge of how to extract information from multimodal data in the training stage, in a form that can be exploited at test time, considering limitations such as noisy or missing modalities. This paper presents a new approach in this direction for RGB-D vision tasks, developed within the adversarial learning and privileged information frameworks. We consider the practical case of learning representations from depth and RGB videos, while relying only on RGB data at test time. We propose a new approach to train a hallucination network that learns to distill depth information via adversarial learning, resulting in a clean approach without several losses to balance or hyperparameters. We report state-of-the-art results on object classification on the NYUD dataset and video action recognition on the largest multimodal dataset available for this task, the NTU RGB+D, as well as on the Northwestern-UCLA.