 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDMCL: Distillation Multiple Choice Learning for Multimodal Action Recognition
Paper and Code
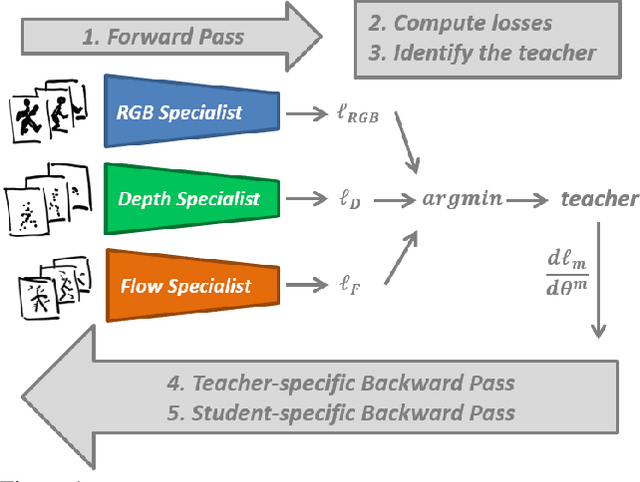
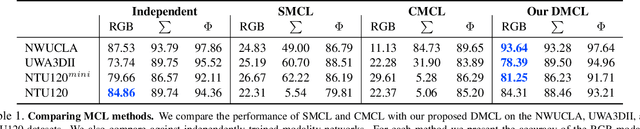
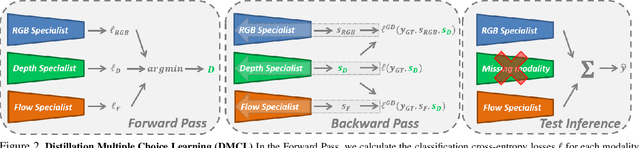

In this work, we address the problem of learning an ensemble of specialist networks using multimodal data, while considering the realistic and challenging scenario of possible missing modalities at test time. Our goal is to leverage the complementary information of multiple modalities to the benefit of the ensemble and each individual network. We introduce a novel Distillation Multiple Choice Learning framework for multimodal data, where different modality networks learn in a cooperative setting from scratch, strengthening one another. The modality networks learned using our method achieve significantly higher accuracy than if trained separately, due to the guidance of other modalities. We evaluate this approach on three video action recognition benchmark datasets. We obtain state-of-the-art results in comparison to other approaches that work with missing modalities at test time.