 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClosing the Train-Test Gap in World Models for Gradient-Based Planning
Dec 10, 2025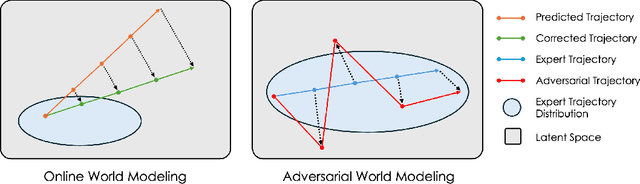
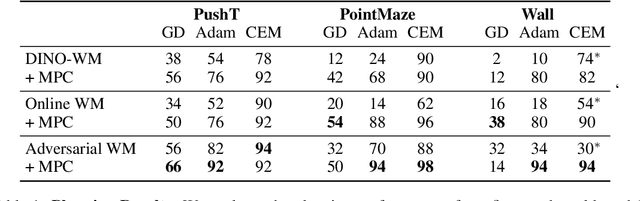
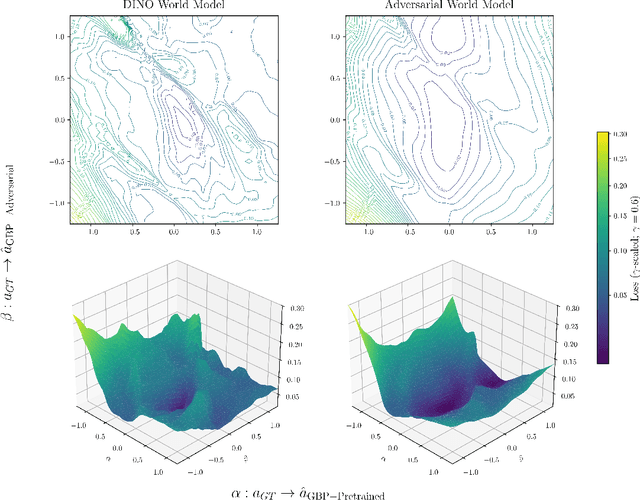
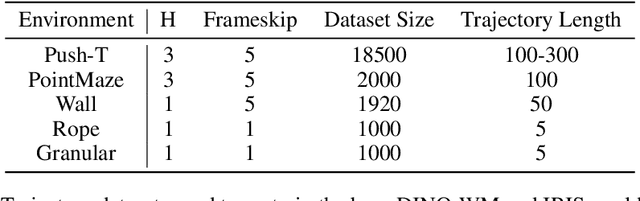
World models paired with model predictive control (MPC) can be trained offline on large-scale datasets of expert trajectories and enable generalization to a wide range of planning tasks at inference time. Compared to traditional MPC procedures, which rely on slow search algorithms or on iteratively solving optimization problems exactly, gradient-based planning offers a computationally efficient alternative. However, the performance of gradient-based planning has thus far lagged behind that of other approaches. In this paper, we propose improved methods for training world models that enable efficient gradient-based planning. We begin with the observation that although a world model is trained on a next-state prediction objective, it is used at test-time to instead estimate a sequence of actions. The goal of our work is to close this train-test gap. To that end, we propose train-time data synthesis techniques that enable significantly improved gradient-based planning with existing world models. At test time, our approach outperforms or matches the classical gradient-free cross-entropy method (CEM) across a variety of object manipulation and navigation tasks in 10% of the time budget.
Verdict: A Library for Scaling Judge-Time Compute
Feb 25, 2025The use of LLMs as automated judges ("LLM-as-a-judge") is now widespread, yet standard judges suffer from a multitude of reliability issues. To address these challenges, we introduce Verdict, an open-source library for scaling judge-time compute to enhance the accuracy, reliability, and interpretability of automated evaluators. Verdict leverages the composition of modular reasoning units -- such as verification, debate, and aggregation -- and increased inference-time compute to improve LLM judge quality. Across a variety of challenging tasks such as content moderation, fact-checking, and hallucination detection, Verdict judges achieve state-of-the-art (SOTA) or near-SOTA performance, surpassing orders-of-magnitude larger fine-tuned judges, prompted judges, and reasoning models. Ultimately, we hope Verdict serves as a useful framework for researchers and practitioners building scalable, interpretable, and reliable LLM-based evaluators.
Constitutional Classifiers: Defending against Universal Jailbreaks across Thousands of Hours of Red Teaming
Jan 31, 2025



Large language models (LLMs) are vulnerable to universal jailbreaks-prompting strategies that systematically bypass model safeguards and enable users to carry out harmful processes that require many model interactions, like manufacturing illegal substances at scale. To defend against these attacks, we introduce Constitutional Classifiers: safeguards trained on synthetic data, generated by prompting LLMs with natural language rules (i.e., a constitution) specifying permitted and restricted content. In over 3,000 estimated hours of red teaming, no red teamer found a universal jailbreak that could extract information from an early classifier-guarded LLM at a similar level of detail to an unguarded model across most target queries. On automated evaluations, enhanced classifiers demonstrated robust defense against held-out domain-specific jailbreaks. These classifiers also maintain deployment viability, with an absolute 0.38% increase in production-traffic refusals and a 23.7% inference overhead. Our work demonstrates that defending against universal jailbreaks while maintaining practical deployment viability is tractable.
Domain Adaptation Through Task Distillation
Aug 27, 2020

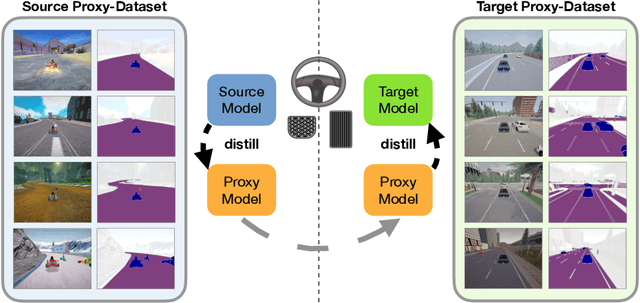
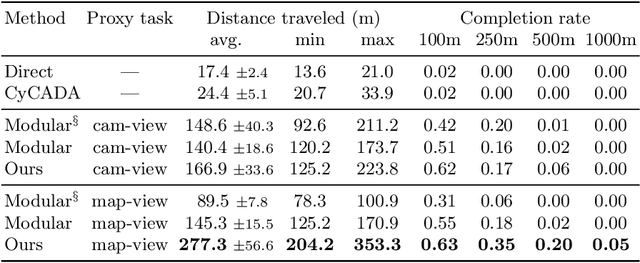
Deep networks devour millions of precisely annotated images to build their complex and powerful representations. Unfortunately, tasks like autonomous driving have virtually no real-world training data. Repeatedly crashing a car into a tree is simply too expensive. The commonly prescribed solution is simple: learn a representation in simulation and transfer it to the real world. However, this transfer is challenging since simulated and real-world visual experiences vary dramatically. Our core observation is that for certain tasks, such as image recognition, datasets are plentiful. They exist in any interesting domain, simulated or real, and are easy to label and extend. We use these recognition datasets to link up a source and target domain to transfer models between them in a task distillation framework. Our method can successfully transfer navigation policies between drastically different simulators: ViZDoom, SuperTuxKart, and CARLA. Furthermore, it shows promising results on standard domain adaptation benchmarks.