 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAIris: An AI-powered Wearable Assistive Device for the Visually Impaired
May 13, 2024Assistive technologies for the visually impaired have evolved to facilitate interaction with a complex and dynamic world. In this paper, we introduce AIris, an AI-powered wearable device that provides environmental awareness and interaction capabilities to visually impaired users. AIris combines a sophisticated camera mounted on eyewear with a natural language processing interface, enabling users to receive real-time auditory descriptions of their surroundings. We have created a functional prototype system that operates effectively in real-world conditions. AIris demonstrates the ability to accurately identify objects and interpret scenes, providing users with a sense of spatial awareness previously unattainable with traditional assistive devices. The system is designed to be cost-effective and user-friendly, supporting general and specialized tasks: face recognition, scene description, text reading, object recognition, money counting, note-taking, and barcode scanning. AIris marks a transformative step, bringing AI enhancements to assistive technology, enabling rich interactions with a human-like feel.
Visual attention information can be traced on cortical response but not on the retina: evidence from electrophysiological mouse data using natural images as stimuli
Aug 01, 2023
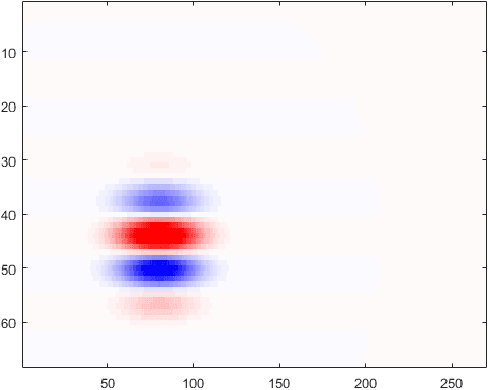


Visual attention forms the basis of understanding the visual world. In this work we follow a computational approach to investigate the biological basis of visual attention. We analyze retinal and cortical electrophysiological data from mouse. Visual Stimuli are Natural Images depicting real world scenes. Our results show that in primary visual cortex (V1), a subset of around $10\%$ of the neurons responds differently to salient versus non-salient visual regions. Visual attention information was not traced in retinal response. It appears that the retina remains naive concerning visual attention; cortical response gets modulated to interpret visual attention information. Experimental animal studies may be designed to further explore the biological basis of visual attention we traced in this study. In applied and translational science, our study contributes to the design of improved visual prostheses systems -- systems that create artificial visual percepts to visually impaired individuals by electronic implants placed on either the retina or the cortex.
Machine Learning Method for Functional Assessment of Retinal Models
Feb 05, 2022

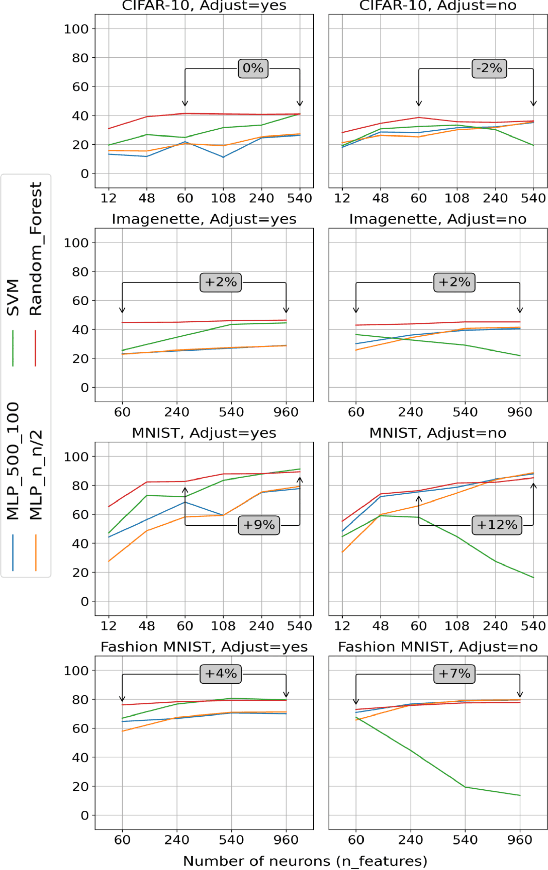
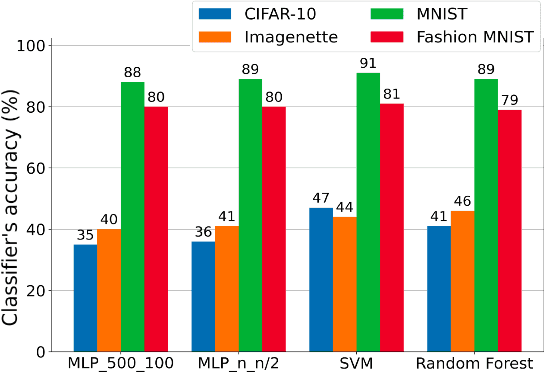
Challenges in the field of retinal prostheses motivate the development of retinal models to accurately simulate Retinal Ganglion Cells (RGCs) responses. The goal of retinal prostheses is to enable blind individuals to solve complex, reallife visual tasks. In this paper, we introduce the functional assessment (FA) of retinal models, which describes the concept of evaluating the performance of retinal models on visual understanding tasks. We present a machine learning method for FA: we feed traditional machine learning classifiers with RGC responses generated by retinal models, to solve object and digit recognition tasks (CIFAR-10, MNIST, Fashion MNIST, Imagenette). We examined critical FA aspects, including how the performance of FA depends on the task, how to optimally feed RGC responses to the classifiers and how the number of output neurons correlates with the model's accuracy. To increase the number of output neurons, we manipulated input images - by splitting and then feeding them to the retinal model and we found that image splitting does not significantly improve the model's accuracy. We also show that differences in the structure of datasets result in largely divergent performance of the retinal model (MNIST and Fashion MNIST exceeded 80% accuracy, while CIFAR-10 and Imagenette achieved ~40%). Furthermore, retinal models which perform better in standard evaluation, i.e. more accurately predict RGC response, perform better in FA as well. However, unlike standard evaluation, FA results can be straightforwardly interpreted in the context of comparing the quality of visual perception.
Stratification of carotid atheromatous plaque using interpretable deep learning methods on B-mode ultrasound images
Feb 04, 2022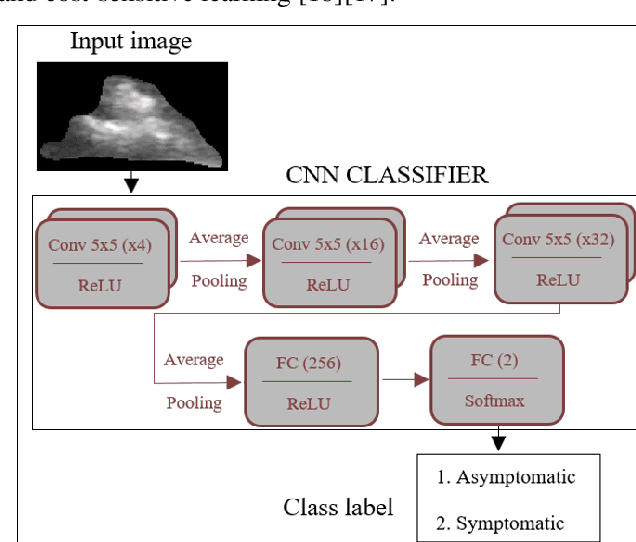
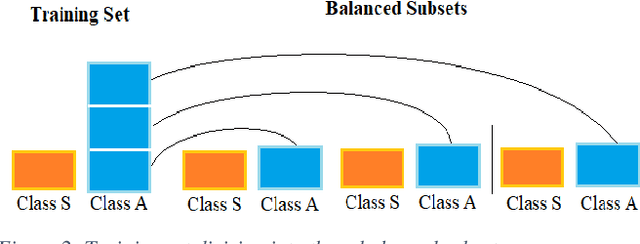
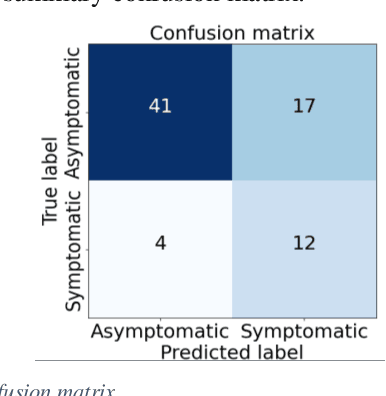
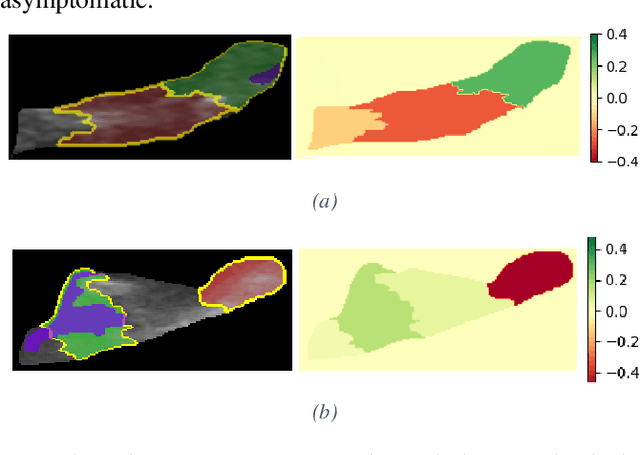
Carotid atherosclerosis is the major cause of ischemic stroke resulting in significant rates of mortality and disability annually. Early diagnosis of such cases is of great importance, since it enables clinicians to apply a more effective treatment strategy. This paper introduces an interpretable classification approach of carotid ultrasound images for the risk assessment and stratification of patients with carotid atheromatous plaque. To address the highly imbalanced distribution of patients between the symptomatic and asymptomatic classes (16 vs 58, respectively), an ensemble learning scheme based on a sub-sampling approach was applied along with a two-phase, cost-sensitive strategy of learning, that uses the original and a resampled data set. Convolutional Neural Networks (CNNs) were utilized for building the primary models of the ensemble. A six-layer deep CNN was used to automatically extract features from the images, followed by a classification stage of two fully connected layers. The obtained results (Area Under the ROC Curve (AUC): 73%, sensitivity: 75%, specificity: 70%) indicate that the proposed approach achieved acceptable discrimination performance. Finally, interpretability methods were applied on the model's predictions in order to reveal insights on the model's decision process as well as to enable the identification of novel image biomarkers for the stratification of patients with carotid atheromatous plaque.Clinical Relevance-The integration of interpretability methods with deep learning strategies can facilitate the identification of novel ultrasound image biomarkers for the stratification of patients with carotid atheromatous plaque.
A linear method for camera pair self-calibration and multi-view reconstruction with geometrically verified correspondences
Jun 28, 2019

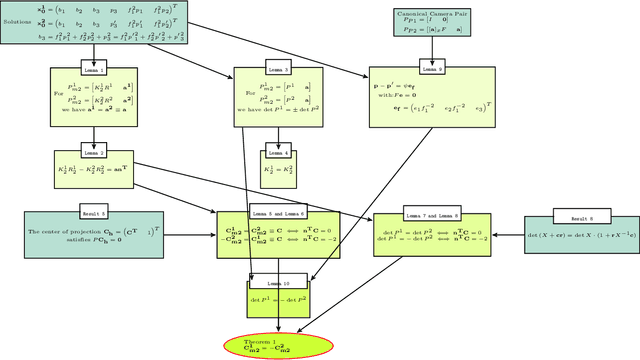

We examine 3D reconstruction of architectural scenes in unordered sets of uncalibrated images. We introduce a linear method to self-calibrate and find the metric reconstruction of a camera pair. We assume unknown and different focal lengths but otherwise known internal camera parameters and a known projective reconstruction of the camera pair. We recover two possible camera configurations in space and use the Cheirality condition, that all 3D scene points are in front of both cameras, to disambiguate the solution. We show in two Theorems, first that the two solutions are in mirror positions and then the relations between their viewing directions. Our new method performs on par (median rotation error $\Delta R = 3.49^{\circ}$) with the standard approach of Kruppa equations ($\Delta R = 3.77^{\circ}$) for self-calibration and 5-Point algorithm for calibrated metric reconstruction of a camera pair. We reject erroneous image correspondences by introducing a method to examine whether point correspondences appear in the same order along $x, y$ image axes in image pairs. We evaluate this method by its precision and recall and show that it improves the robustness of point matches in architectural and general scenes. Finally, we integrate all the introduced methods to a 3D reconstruction pipeline. We utilize the numerous camera pair metric recontructions using rotation-averaging algorithms and a novel method to average focal length estimates.