 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSC-GlowTTS: an Efficient Zero-Shot Multi-Speaker Text-To-Speech Model
Apr 02, 2021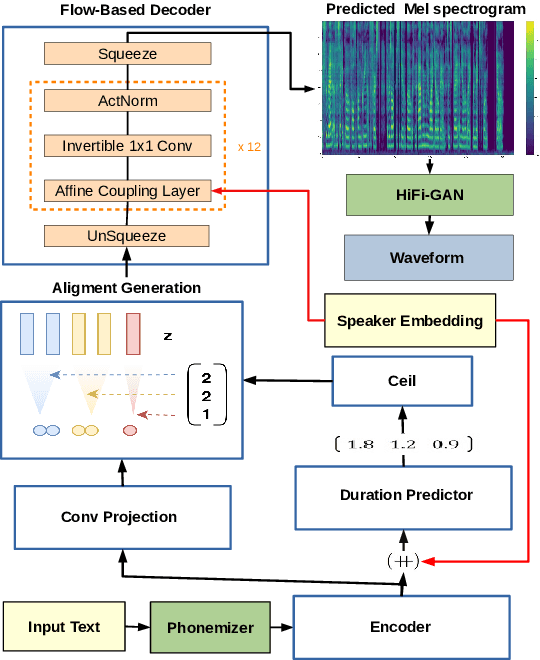
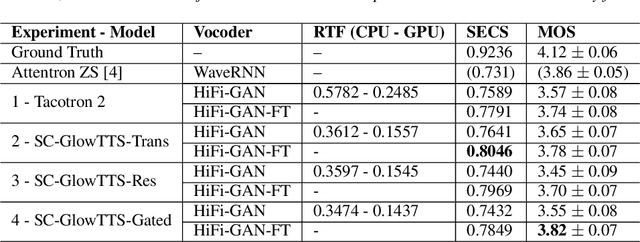
In this paper, we propose SC-GlowTTS: an efficient zero-shot multi-speaker text-to-speech model that improves similarity for speakers unseen in training. We propose a speaker-conditional architecture that explores a flow-based decoder that works in a zero-shot scenario. As text encoders, we explore a dilated residual convolutional-based encoder, gated convolutional-based encoder, and transformer-based encoder. Additionally, we have shown that adjusting a GAN-based vocoder for the spectrograms predicted by the TTS model on the training dataset can significantly improve the similarity and speech quality for new speakers. Our model is able to converge in training, using only 11 speakers, reaching state-of-the-art results for similarity with new speakers, as well as high speech quality.
Data Poisoning Attacks on Regression Learning and Corresponding Defenses
Sep 15, 2020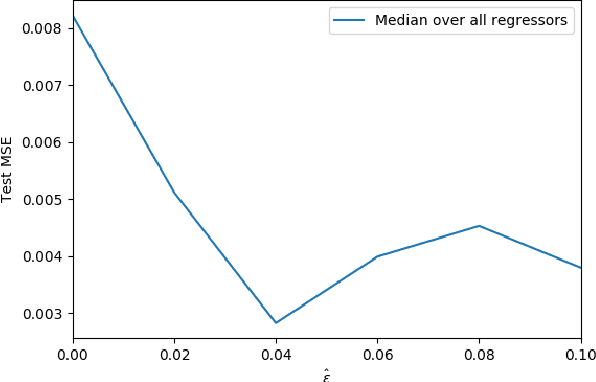
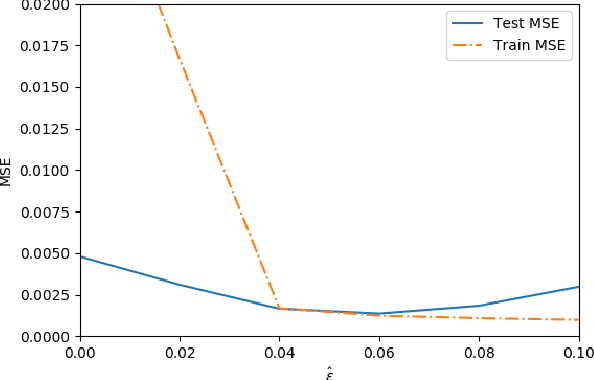

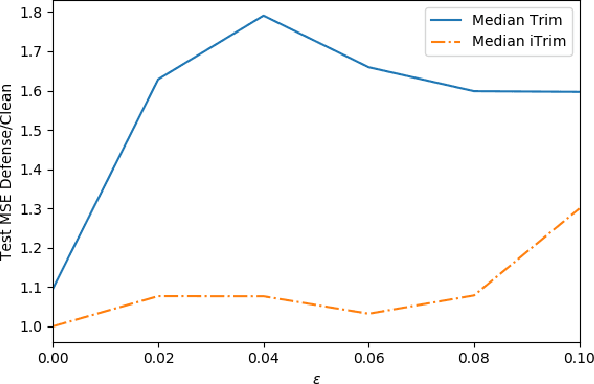
Adversarial data poisoning is an effective attack against machine learning and threatens model integrity by introducing poisoned data into the training dataset. So far, it has been studied mostly for classification, even though regression learning is used in many mission critical systems (such as dosage of medication, control of cyber-physical systems and managing power supply). Therefore, in the present research, we aim to evaluate all aspects of data poisoning attacks on regression learning, exceeding previous work both in terms of breadth and depth. We present realistic scenarios in which data poisoning attacks threaten production systems and introduce a novel black-box attack, which is then applied to a real-word medical use-case. As a result, we observe that the mean squared error (MSE) of the regressor increases to 150 percent due to inserting only two percent of poison samples. Finally, we present a new defense strategy against the novel and previous attacks and evaluate it thoroughly on 26 datasets. As a result of the conducted experiments, we conclude that the proposed defence strategy effectively mitigates the considered attacks.
Identifying Mislabeled Instances in Classification Datasets
Dec 11, 2019
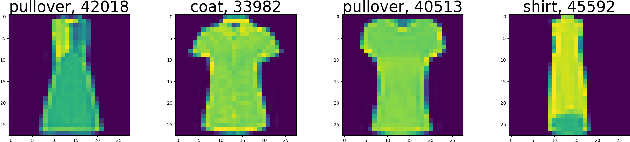
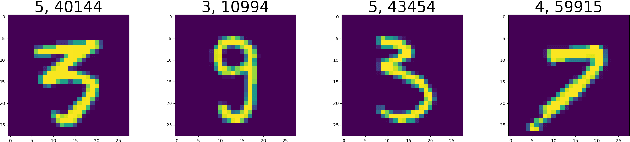
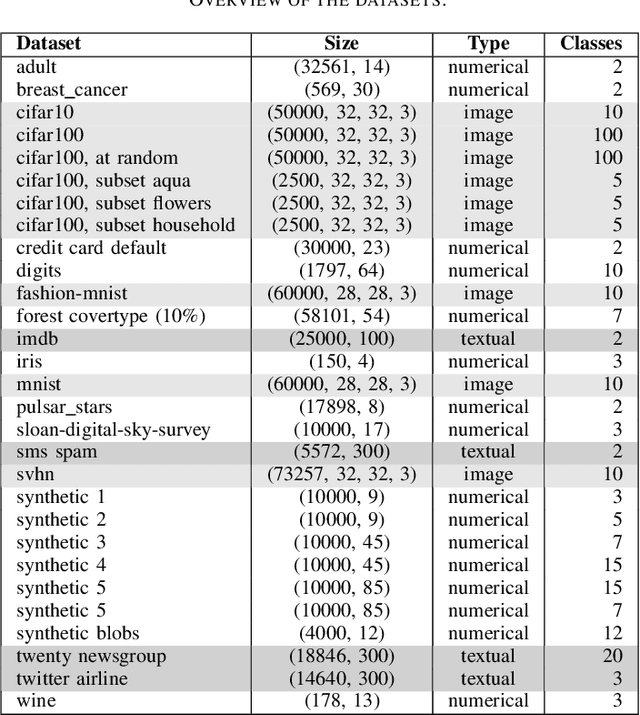
A key requirement for supervised machine learning is labeled training data, which is created by annotating unlabeled data with the appropriate class. Because this process can in many cases not be done by machines, labeling needs to be performed by human domain experts. This process tends to be expensive both in time and money, and is prone to errors. Additionally, reviewing an entire labeled dataset manually is often prohibitively costly, so many real world datasets contain mislabeled instances. To address this issue, we present in this paper a non-parametric end-to-end pipeline to find mislabeled instances in numerical, image and natural language datasets. We evaluate our system quantitatively by adding a small number of label noise to 29 datasets, and show that we find mislabeled instances with an average precision of more than 0.84 when reviewing our system's top 1\% recommendation. We then apply our system to publicly available datasets and find mislabeled instances in CIFAR-100, Fashion-MNIST, and others. Finally, we publish the code and an applicable implementation of our approach.